caffe solver.ptototxt详解
来源:互联网 发布:终结者创世纪知乎 编辑:程序博客网 时间:2024/05/22 07:54
caffe中文社区:http://caffecn.cn/caffe中solver参数详解# The train/test net protocol buffer definition# this follows "ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION"# 自己定义的网络结构,也可以将训练用的网络结构和测试用的网络结构分别定义# train_net: "examples/mnist/train.prototxt"# test_net: "examples/mnist/test.prototxt"net: "examples/mnist/lenet_train_test.prototxt"# test_iter specifies how many forward passes the test should carry out.# In the case of MNIST, we have test batch size 100 and 100 test iterations,# covering the full 10,000 testing images.# 测试迭代次数,需要结合lenet_train_test.prototxt中测试阶段的输入数据来看# 就是最下面的那个数据层,最下面的那个层批处理大小是100的话,有10000个数据,因此,需要迭代10000/100=100次test_iter: 100# Carry out testing every 500 training iterations.# 测试间隔,也就是每训练500次,测试一次test_interval: 500# All parameters are from the cited paper above# 学习率的设置:基础学习率,也可以认为是初始化学习率base_lr: 0.001# 上一次梯度权重,为什么要加这个权重?因为在有些优化求解的算法中,梯度更新的方向是呈现锯齿形状的,因此,为了让梯度更新的方向# 朝着总体是最优的方向进行,需要考虑上一次梯度的更新,而在物理学中理解来看,就是:动量,因此,加入该参数后权重的更新是上次权重与这次更新权重的加权和momentum: 0.9momentum2: 0.999# since Adam dynamically changes the learning rate, we set the base learning# rate to a fixed value# 学习率的更新策略,下面有学习率更新策略可选的参数lr_policy: "fixed"# Display every 100 iterationsdisplay: 100# The maximum number of iterationsmax_iter: 10000# snapshot intermediate results# 每5000次保存一次中间结果,方便下次继续进行训练snapshot: 5000snapshot_prefix: "examples/mnist/lenet"# solver mode: CPU or GPU# 优化求解方法,可选方法见下面的具体讲解type: "Adam"solver_mode: GPU一般的solver里面还会有一个权重衰减项:weight_decay: 0.0005网络权值越大往往overfitting的程度越高,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和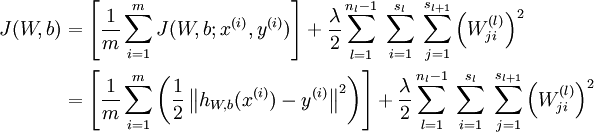
右边项即用来惩罚大权值。权值衰减惩罚项使得权值收敛到较小的绝对值,而惩罚大的权值。从而避免overfitting的出现。 lr_policy,学习率更新策略,可以设置为下面这些值,相应的学习率的计算为(下面的iter是当前的迭代次数): - fixed: 保持base_lr不变. - step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数 - exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数 - inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power) - multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据 stepvalue值变化 - poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power) - sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))关于学习率,还需要记住的是,每一层都有两个学习率lr_mult,一个是该层的参数,一个是该层的偏置(激活层与池化层没有这两项),例如,下面的卷积层和全连接层layer { name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2" param { lr_mult: 1 } param { lr_mult: 2 } convolution_param { num_output: 20 kernel_size: 5 stride: 1 pad: 2 weight_filler { type: "xavier" } bias_filler { type: "constant" } }}layer { name: "ip1.1" type: "InnerProduct" bottom: "res2a" top: "ip1.1" param { lr_mult: 1 } param { lr_mult: 2 } inner_product_param { num_output: 100 weight_filler { type: "xavier" } bias_filler { type: "constant" } }}caffe提供了以下几种优化求解方法: Stochastic Gradient Descent (type: "SGD"), AdaDelta (type: "AdaDelta"), Adaptive Gradient (type: "AdaGrad"), Adam (type: "Adam"), Nesterov’s Accelerated Gradient (type: "Nesterov") and RMSprop (type: "RMSProp")layer { name: "mnist" type: "Data" top: "data" top: "label" include { phase: TEST } transform_param { scale: 0.00390625 } data_param { source: "examples/mnist/mnist_test_lmdb" batch_size: 100 backend: LMDB }} 0 0
- caffe solver.ptototxt详解
- caffe——solver层详解
- caffe学习(8)Solver 配置详解
- caffe 参数的详解solver文件<一>
- Caffe Solver
- caffe的solver文件参数详解--caffe学习(2)
- caffe solver.prototxt文件
- Caffe学习:Solver
- Caffe的Solver参数设置
- Caffe: solver及其配置
- Caffe学习3-Solver
- Caffe学习:Solver
- caffe solver解释
- caffe solver及其配置
- caffe solver参数解析
- Caffe solver.prototxt学习
- Caffe的Solver参数设置
- Caffe:solver及其配置
- leetcode_35. Search Insert Position
- java中23种常见的设计模式
- java内码和外码
- android sensor移植
- UVALive 3637 The Bookcase(DP)
- caffe solver.ptototxt详解
- As从svn检出项目到本地并关联
- 每日论文InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial
- Web tools
- Libsvm网格参数寻优教程
- 几种网络编程技术在协议栈中的层次
- 一个Excel转换为Json格式的Python脚本
- Java中的并发工具类(七)
- 测试短信日志表里超过64个字的短信数量SQL


