READING NOTE: A Pursuit of Temporal Accuracy in General Activity Detection
来源:互联网 发布:淘宝开店品牌怎么填 编辑:程序博客网 时间:2024/05/16 18:53
TITLE: A Pursuit of Temporal Accuracy in General Activity Detection
AUTHOR: Yuanjun Xiong, Yue Zhao, Limin Wang, Dahua Lin, Xiaoou Tang
ASSOCIATION: The Chinese University of Hong Kong, ETH
FROM: arXiv:1703.02716
CONTRIBUTIONS
- A novel proposal scheme is proposed that can efficiently generate candidates with accurate temporal boundaries.
- A cascaded classification pipeline is introduced that explicitly distinguishes between relevance and completeness of a candidate instance.
METHOD
The proposed action detection framework starts with evaluating the actionness of the snippets of the video. A set of temporal action proposals (in orange color) are generated with temporal actionness grouping (TAG). The proposals are evaluated against the cascaded classifiers to verify their relevance and completeness. Only proposals being complete instances are produced by the framework. Non-complete proposals and background proposals are rejected by a cascaded classification pipeline. The framework is illustrated in the following figure.
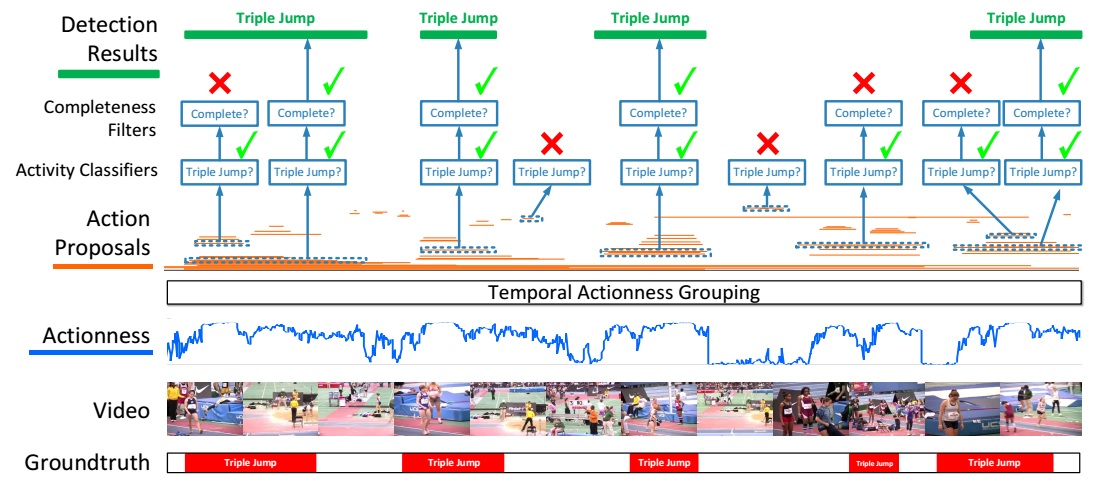
Temporal Region proposals
The temporal region proposals are generated with a bottom-up procedure, which consists of three steps: extract snippets, evaluate snippet-wise actionness, and finally group them into region proposals.
- To evaluate the actionness, a binary classifier is learnt based on the Temporal Segment Network proposed in Temporal segment networks: Towards good practices for deep action recognition.
- To generate temporal region proposals, the basic idea is to group consecutive snippets with high actionness scores. The scheme first obtains a number of action fragments by thresholding – a fragment here is a consecutive sub-sequence of snippets whose actionness scores are above a certain threshold, referred to as actionness threshold.
- Then, to generate a region proposal, a fragment is picked as a starting point and expanded recursively by absorbing succeeding fragments. The expansion terminates when the portion of low-actionness snippets goes beyond a threshold, a positive value which is referred to as the tolerance threshold. Beginning with different fragments, we can obtain a collection of different region proposals.
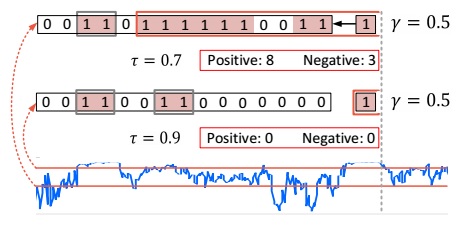
Note that this scheme is controlled by two design parameters: the actionness threshold and the tolerance threshold. The final proposal set is the union of those derived from individual combination of the two values. This scheme is called Temporal Actionness Grouping, illustrated in the above figure, which has several advantages:
- Thanks to the actionness classifier, the generated proposals are mostly focused on action-related contents, which greatly reduce the number of needed proposals.
- Action fragments are sensitive to temporal transitions. Hence, as a bottom-up method that relies on merging action fragments, it often yields proposals with more accurate temporal boundaries.
- With the multi-threshold design, it can cover a broad range of actions without the need of case-specific parameter tuning. With these properties, the proposed method can achieve high recall with just a moderate number of proposals. This also benefits the training of the classifiers in the next stage.
Detecting Action Instances
this is accomplished by a cascaded pipeline with two steps: activity classification and completeness filtering.
Activity Classification
A classifier is trained based on TSN. During training, region proposals that overlap with a ground-truth instance with an IOU above 0.7 will be used as positive samples. A proposal is considered as a negative sample only when less than 5% of its time span overlaps with any annotated instances. Only the proposals classified as non-background classes will be retained for completeness filtering. The probability from the activity classifier is denoted as
Completeness Filtering
To evaluate the completeness, a simple feature representation is extracted and used to train class-specific SVMs. The feature comprises three parts: (1) A temporal pyramid of two levels. The first level pools the snippet scores within the proposed region. The second level split the segment into two parts and pool the snippet scores inside each part. (2) The average classification scores of two short periods – the ones before and after the proposed region. The method is illustrated in the following figure.

The output of the SVMs for one class is denoted as
Then final detection confidence for each proposal is
- READING NOTE: A Pursuit of Temporal Accuracy in General Activity Detection
- Temporal Activity Detection in Untrimmed Videos with Recurrent Neural Networks
- READING NOTE: Face Detection with End-to-End Integration of a ConvNet and a 3D Model
- <A Survey of CPU-GPU Heterogeneous Computing Techniques >reading note
- READING NOTE: A New Convolutional Network-in-Network Structure
- READING NOTE: Pushing the Limits of Deep CNNs for Pedestrian Detection
- READING NOTE: Object Detection by Labeling Superpixels
- READING NOTE: SuperCNN: A Superpixelwise Convolutional Neural Network for Salient Object Detection
- Reading note of Effective C++
- PolyNet A pursuit of structural diversity in very deep networks(翻译笔记)
- Reading attribute of a BOR (Business Object) in ABAP
- READING NOTE: Feature Pyramid Networks for Object Detection
- The 1st Part Reading Note of the Android - A Programmer's Guide
- A. Arrival of the General
- Fast detection of multiple objects in traffic scenes with a common detection framework
- READING NOTE: Speed/accuracy trade-offs for modern convolutional object detectors
- Reading Note
- Detection of a buffer overrun
- ARIMA模型原理及其java实现
- POJ 2405 Beavergnaw G++
- hadoop中在map和reduce方法中调试代码
- Linux基础入门
- 基础算法分治
- READING NOTE: A Pursuit of Temporal Accuracy in General Activity Detection
- vimrc备份
- Android基础之应用Service
- 基于STM32L151//STM32F407的矩阵键盘程序(不规则接口):
- Lodash中十个常用的工具函数
- 人工智能商业应用成功的六大必要条件
- HTML5-网页绘画板
- No4.Week 4
- leetcode 139. Word Break


