Standford 机器学习—第三讲 Logistic Regression 逻辑回归
来源:互联网 发布:上网监控软件下载 编辑:程序博客网 时间:2024/06/06 04:23
本栏目(Machine learning)包括单参数的线性回归、多参数的线性回归、Octave Tutorial、Logistic Regression、Regularization、神经网络、机器学习系统设计、SVM(Support Vector Machines 支持向量机)、聚类、降维、异常检测、大规模机器学习等章节。所有内容均来自Standford公开课machine learning中Andrew老师的讲解。
Logistic Regression 逻辑回归
- Logistic Regression 逻辑回归
- Classification
- Decision Boundary 决策边界
- cost function代价函数
- 高级优化
- Multi-class Classification One-vs-all
- Regularization 正则化
- 1 什么是过度拟合
- 2 如何解决过拟合问题
- 3 正则化线性回归regularized linear regression
- 4 正则化逻辑回归
1. Classification
假设函数:
模型的输出变量范围始终在0和1之间。
假设模型为:
其中:X代表特征向量,g代表逻辑函数,即S型函数
则
函数图如下:

例如:对于给定x,得出
2. Decision Boundary 决策边界
所谓Decision Boundary就是能够将所有数据点进行很好地分类的h(x)边界。
如下图所示,假设形如
predict Y=1, if -3+x1+x2>=0
predict Y=0, if -3+x1+x2<0
刚好能够将图中所示数据集进行很好地分类

除了线性boundary还有非线性decision boundaries,比如
下图中,进行分类的decision boundary就是一个半径为1的圆,如图所示:

结论:
假设函数:
预测:
当
当
根据 S 型函数图像得出:
即:
3. cost function代价函数
定义逻辑回归的cost function为:

y=0 和 y=1 时的cost funciton 函数图如下:


由于y只会取0,1,那么就可以写成
对应的梯度下降算法为:
对应的梯度
这里的梯度和
注意:必须要同时更新
4. 高级优化
这部分内容将对logistic regression 做一些优化措施,使得能够更快地进行参数梯度下降。本段实现了matlab下用梯度方法计算最优参数的过程。
首先声明,除了gradient descent 方法之外,我们还有很多方法可以使用,如下图所示,左边是另外三种方法,右边是这三种方法共同的优缺点,无需选择学习率α,更快,但是更复杂。具体的octave和matlab实现这里先略过,后续有机会补上。

5. Multi-class Classification One-vs-all
所谓 one-vs-all method 就是将 binary 分类的方法应用到多类分类中。
比如我想分成 K 类,那么就将其中一类作为 positive,另(k-1)合起来作为 negative,这样进行 K 个

在做预测时,需要把所有的分类
6. Regularization 正则化
正则化,是用来改善或者减少在回归的过程中产生的过度拟合(overfitting)的问题的。
6.1 什么是过度拟合
当我们有非常多的特征,我们通过学习得到的假设函数能够非常好的适应训练集(代价函数几乎为0),但是可能不能很好的应用到新的数据中去。例子如下:
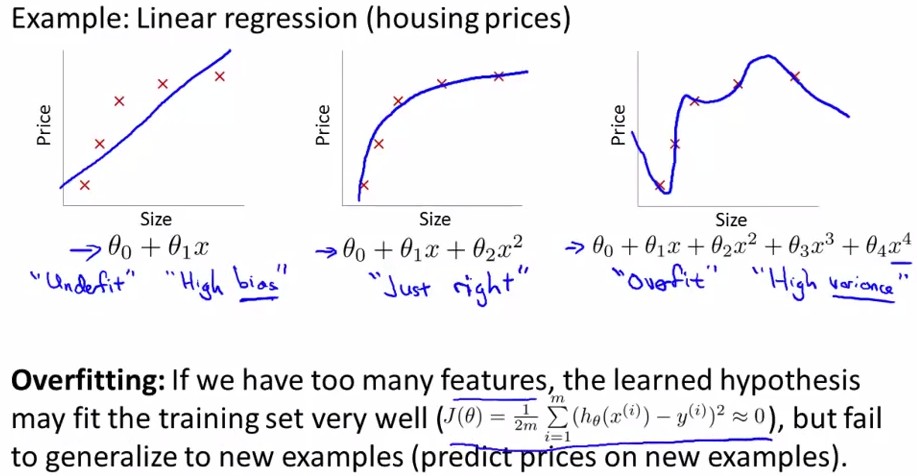
左边图为欠拟合,右边图为过拟合,中间图为刚刚好。
6.2 如何解决过拟合问题
丢弃一些不能帮助我们预测的特征,可以手工选择保留哪些特征,或者使用模型来解决。
正则化。保留所有的特征,但是减少参数的大小。好处 :当特征很多时,每一个特征都会对预测y贡献一份合适的力量。
代价函数:
其中
按照惯例,不对
6.3 正则化线性回归(regularized linear regression)
- 基于梯度下降的算法
θ0:=θ0−αm∑i=1m((hθ(x(i))−y)∗x(i)0)
注意:j 从 1,2,3…,n
- 正规方程

正则化还可以解决
6.4 正则化逻辑回归
和linear regression一样,我们给J(θ)加入关于θ的惩罚项来抑制过拟合:
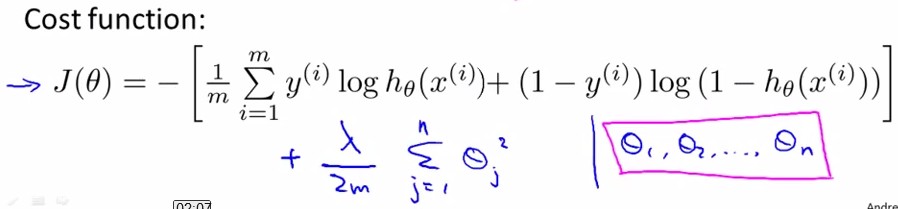
用Gradient Descent的方法,令J(θ)对θj求导都等于0,得到

这里我们发现,其实和线性回归的θ更新方法是一样的。
- Standford 机器学习—第三讲 Logistic Regression 逻辑回归
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Stanford 机器学习 第四讲-------逻辑回归(Logistic Regression)
- Coursera机器学习-第三周-逻辑回归Logistic Regression
- 机器学习: 逻辑回归(Logistic Regression)
- dcloud混合开发-修改用户头像支持截图的解决方案
- 外观模式
- Qt程序设置整个软件字体类型和字体大小
- 关于java内部类(静态内部类和普通内部类)
- Linux设置静态IP,掩码,网关,DNS服务器
- Standford 机器学习—第三讲 Logistic Regression 逻辑回归
- Java进阶(五十五)-Java Lambda表达式入门
- ArcGIS锁
- 实时计算平台设计
- mysql-cluster 环境配置
- Atlas-手淘组件化框架(阿里巴巴开源框架)
- Java内部类(成员内部类、静态内部类、局部内部类、匿名内部类)小结
- ssh 信任关系无密码登陆,清除公钥,批量脚本
- git使用教程


