CUDA之Dynamic Parallelism详解(二)
来源:互联网 发布:查看端口占用 编辑:程序博客网 时间:2024/06/06 01:02
CUDA 5.0中引入动态并行化,使得在device端执行的kernel的线程也能跟在host上一样launch kernels,只有支持CC3.5或者以上的设备中才能支持。动态并行化使用CUDA Device Runtime library(cudadevrt),它是一个能在device code中调用的CUDA runtime子集。
编译链接
为了支持动态并行化,必须使用两步分离编译和链接的过程:首先,设定-c和-rdc=true(–relocatable-device-code=true)来生成relocatable device code来进行后续链接,可以使用-dc(–device -c)来合并这两个选项;然后将上一步目标文件和cudadevrt库进行连接生成可执行文件,-lcudadevrt。过程如下图
或者简化成一步
执行、同步
在CUDA编程模型中,一组执行的kernel的线程块叫做一个grid。在CUDA动态并行化,parent grid能够调用child grids。child grid继承parant grid的特定属性和限制,如L1 cache、shared_memory、栈大小。如果一个parent grid有M个block和N个thread,如果对child kernel launch没有控制的话,那个将产生M*N个child kernel launch。如果想一个block产生一个child kernel,那么只需要其中一个线程launch a kernel就行。如下
grid lanuch是完全嵌套的,child grids总是在发起它们的parent grids结束前完成,这可以看作是一个一种隐式的同步。

如果parent kernel需要使用child kernel的计算结果,也可以使用CudaDeviceSynchronize(void)进行显示的同步,这个函数会等待一个线程块发起的所有子kernel结束。往往不知道一个线程块中哪些子kernel已经执行,可以通过下述方式进行一个线程块级别的同步
CudaDeviceSynchronize(void)调用开销较大,不是必须的时候,尽量减少使用,同时不要在父kernel退出时调用,因为结束时存在上述介绍的隐式同步。
内存一致
当子 grids开始与结束之间,父grids和子grids有完全一致的global memory view。
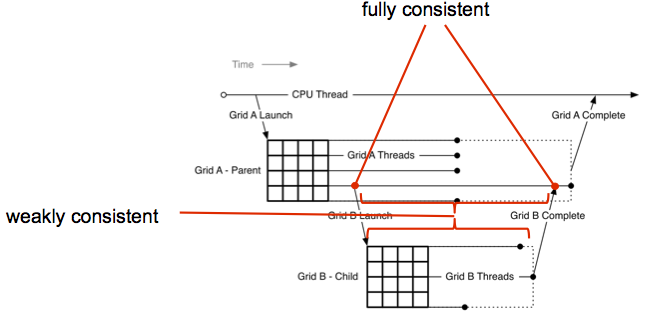
当子kernel launch的时候,global memory视图不一致。
在子kernel launch之后,显示同步之前,parent grid不能对 child grid读取的内存做写入操作,否则会造成race condition。
向Child grids传递指针
指针的传递存在限制:
- 可以传递的指针:global memory(包括__device__变量和malloc分配的内存),zero-copy host端内存,常量内存。
- 不可以传递的指针:shared_memory(__shared__变量), local memory(包括stack变量)
Device Streams和Events
所有在device上创建的streams都是non-blocking的,不支持默认NULL stream的隐式同步。创建流的方式如下
一旦一个device stream被创建,它能被一个线程块中其他线程使用。只有当这个线程块完成执行的时候,这个stream才能被其他线程块或者host使用。反之亦然。
Event也是支持的,不过有限制,只支持在不同stream之间使用cudaStreamWaitEvent()指定执行顺序,而不能使用event来计时或者同步。
Recursion Depth和Device Limits
递归深度包括两个概念:
- nesting depth:递归grids的最大嵌套层次,host端的为0;
- synchronization depth:cudaDeviceSynchronize()能调用的最大嵌套层次,host端为1,cudaLimitDevRuntimeSyncDepth应该设定为maximum 所以你吃肉你咋体on depth加1,设定方式如
cudaDeviceLimit(cudaLimitDevRuntimeSyncDepth, 4).
maximum nesting depth有硬件限制,在CC3.5中, 对depth 的限制为24. synchronization depth也一样。
从外到内,直到最大同步深度,每一次层会保留一部分内存来保存父block的上下文数据,即使这些内存没有被使用。所以递归深度的设定需要考虑到每一层所预留的内存。
另外还有一个限制是待处理的子grid数量。pending launch buffer用来维持launch queue和追踪当前执行kernel的状态。通过
来设定合适的限制。否则通过cudaGetLastError()调用可以返回CudaErrorLaunchPendingCountExceeded的错误。
动态并行化执行有点类似树的结构,但与CPU上树处理也有些不同。类似深度小,分支多,比较茂密的树的执行结构,比较适合动态并行化的处理。深度大,每层节点少的树的执行结构,则不适合动态并行化。
characteristictree processingdynamic parallelismnodethin (1 thread)thick (many threads)branch degreesmall (usually < 10)large (usually > 100)depthlargesmall- CUDA之Dynamic Parallelism详解(二)
- CUDA之Dynamic Parallelism详解(一)
- CUDA之Dynamic Parallelism详解(三)
- CUDA Dynamic Parallelism 学习笔记
- cuda dynamic parallelism-CUDA动态并行
- Dynamic Parallelism
- CUDA dynamic parallelism在 visual studio 2010 中的设置
- 如何解决cuda 5.0 编译dynamic parallelism 功能代码时的 fatal error
- cuda中dynamic parallelism中遇到的链接错误:error LNK2001: unresolved external symbol ___fatbinwrap_66_tmpxft_…
- CUDA C 编程指导(二):CUDA编程模型详解
- [深入浅出Cocoa]之消息(二)-详解动态方法决议(Dynamic Method Resolution)
- [深入浅出Cocoa]之消息(二)-详解动态方法决议(Dynamic Method Resolution)
- [深入浅出Cocoa]之消息(二)-详解动态方法决议(Dynamic Method Resolution)
- [深入浅出Cocoa]之消息(二)-详解动态方法决议(Dynamic Method Resolution)
- [深入浅出Cocoa]之消息(二)-详解动态方法决议(Dynamic Method Resolution)
- CUDA学习之二
- cuda入门之二
- CUDA学习(二)
- 正确使用join语句
- Sticks (剪枝)
- 【JZOJ3737】【NOI2014模拟7.11】挖宝藏(treasure)
- Linux 服务器安装MySQL数据库
- 百度富文本编辑器的上传图片的路径问题
- CUDA之Dynamic Parallelism详解(二)
- zoomeye用户使用手册
- css Sprite
- nodejs:使用emailjs发送邮件
- Renting Bikes 二分
- eclipse 使用maven 构建springboot+注入servlet
- 1. thinkphp相关
- source 命令找不到的情况(修改完/etc/profile文件之后,使其生效)
- OPENGL编程练习


