决策树梳理
来源:互联网 发布:网络算命高手 编辑:程序博客网 时间:2024/04/29 14:03
决策树
martin
- 决策树
- 基本概念
- ID3
- C45
- CART
- 剪枝处理
- 前剪枝
- 后剪枝
基本概念
一般的,一颗决策树包含一个根节点、若干个内部节点和若干个叶节点,所以决策树相当于多叉树。叶节点对应于决策结果,其他每个结点则对应与一个属性测试,每个节点包含的样本集合根据属性测试的结果被分到子节点中。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力的决策树,基本思想遵循“分而治之”的策略。
决策树的生成是一个递归过程。在决策树算法中有三种情形会导致递归返回:
- 当前节点包含的样本全部属于同一个类别,无需划分。
- 当前属性集为空,或是所有样本在所有属性集上取值相同,无法划分。此时,把当前节点标记为叶节点,并将其类别设定为该节点所含样本最多的类别。
- 当前节点包含的样本集合为空,不能划分。此时,同样把当前节点标记为叶节点,但将其类别设定为其父节点所含样本最多的类别。
注意:2和3不同,2是后验概率,3是把父节点的样本分布作为当前节点的先验概率。
下面给出一个决策树的例子:
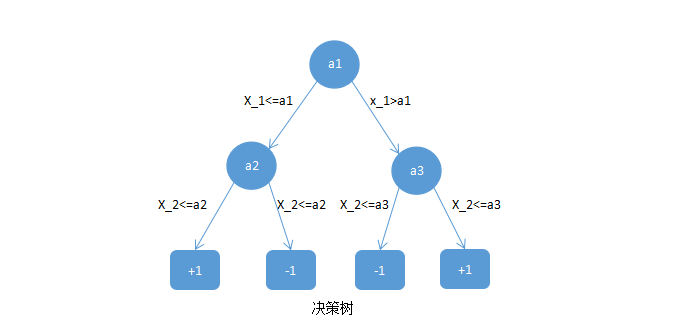
决策树相当于对特征空间进行划分,如下:
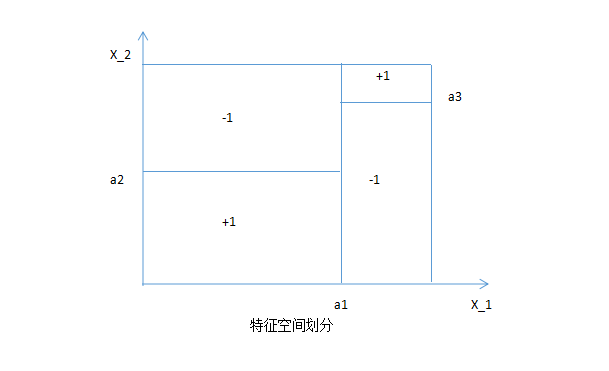
也就是说,决策树的每条路径对应于特征空间的每个区域。对于决策树主要有以下几种:ID3,C4.5主要应用于分类任务;CART树,主要应用于预测任务,下面将逐个介绍。
ID3
对于之前给出的决策树的节点划分在ID3中有特定的方法,ID3中节点划分所衡量的指标是:信息增益。
一般而言,信息增益越大,则意味着使用属性
给一个数据集,我们在这个数据集上来进行ID3决策树的生成:
然后,我们要计算出当前属性集合
先计算根节点的信息熵:
计算属性“
有了上面的信息就可以求该特征的每个属性的信息熵了:
于是,可以计算出属性色泽的信息增益:
类似的,我们可以计算出其他属性的信息增益:
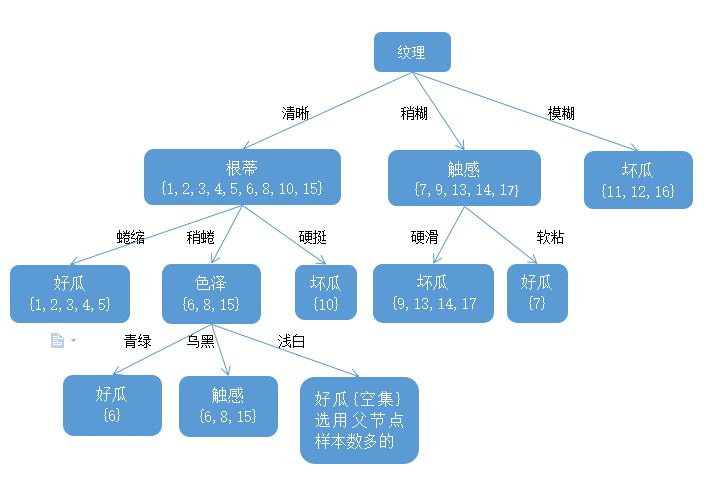
显然,属性纹理的信息增益最大,于是它被选为划分属性,给出基于纹理对根节点进行划分的结果:
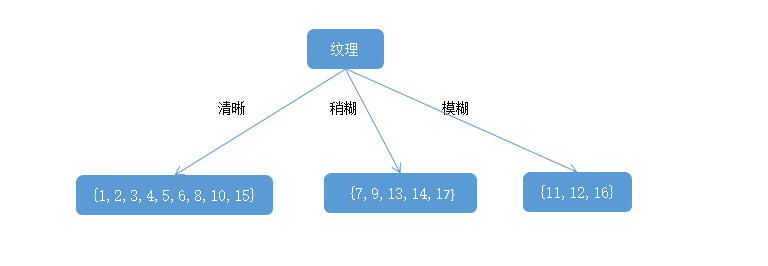
然后,决策树学习算法将对每个分之节点做进一步划分。以上图第一个分支节点(纹理=清晰)为例,该节点包含的样例集合
先计算第一个分支节点的信息熵:
计算属性“
有了上面的信息就可以求该特征的每个属性的信息熵了:
于是,可以计算出属性色泽的信息增益:
类似的,我们可以计算出其他属性的信息增益:
根蒂,脐部,触感3个属性均取得了最大的信息熵增益,可任选其中之一作为划分属性,于是在第一个分支上划分后的决策树如下图:
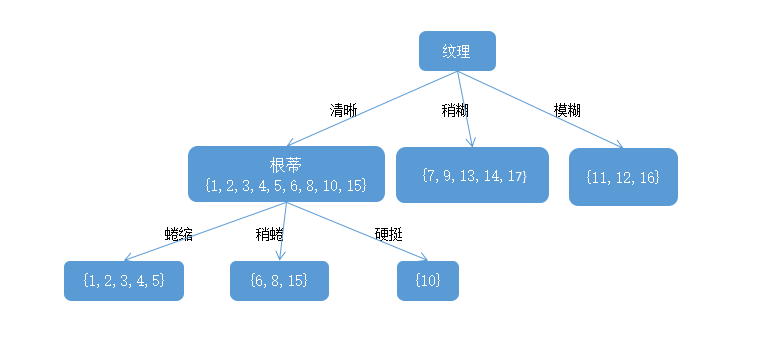
重复上述操作即可得如下图的最终决策树结果:
C4.5
实际上,ID3的信息增益划分法对可取数值较多的属性有所偏好,为减少这种偏好可能带来的不利影响,C4.5算法不采用信息增益,取而代之的是信息增益率来选择最优划分特征属性。信息增益率定义为:
其中,
IV(a)称为属性
与ID3决策树一样,同是选择最大的值作为最优划分。
CART
CART决策树是一棵二叉树,内部节点特征取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。CART决策树使用“基尼系数”来选择划分属性。基尼系数的定义如下:
那么对于属性
直观来说,Gini(D)反映了从数据集
求特征A1(年龄)的基尼系数:
由于Gini(D,青年)和Gini(D,老年)相等且最小,所以都可以作为年龄的最优切分点。
接着求工作,房子的基尼系数:
所以对工作和房子分别取0.32和0.27。接着求信贷的基尼系数:
Gini(D,非常好)最小,所以信贷非常好作为最优切分点。
最后,在年龄(Gini(D,青年)=0.44),工作(Gini(D,有工作)=0.32),房子(Gini(D,有房子)=0.27),信贷(Gini(D,非常好)=0.32)中,房子的基尼系数最小,所以选择房子作为最有特征,有房子作为其最优切分点。于是根节点生出两个子节点,一个是叶节点,对另一个节点继续使用以上方法在年龄,工作,信贷中选择
剪枝处理
剪枝是决策树学习算法对付“过拟合”的主要手段。决策树剪枝的基本策略有“前剪枝”和“后剪枝”。前剪枝是指在决策树生成过程中,对每个节点在划分前先进行预估,若当前节点的划分不能够带来决策树泛化性能的提升,则停止划分并将当前节点标记为叶节点。后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上的对非叶子节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能的提升,则将该子树替换为叶节点。在进行泛化能力考察时,采用的方法是从原数据集中留出“验证集”的方式进行验证。
给出一个数据集,已经分割为“训练集”和“验证集”:
训练集:
验证集:
前剪枝
基于上述给出的不完整的训练集根据信息增益所生成的未剪枝的决策树如下:
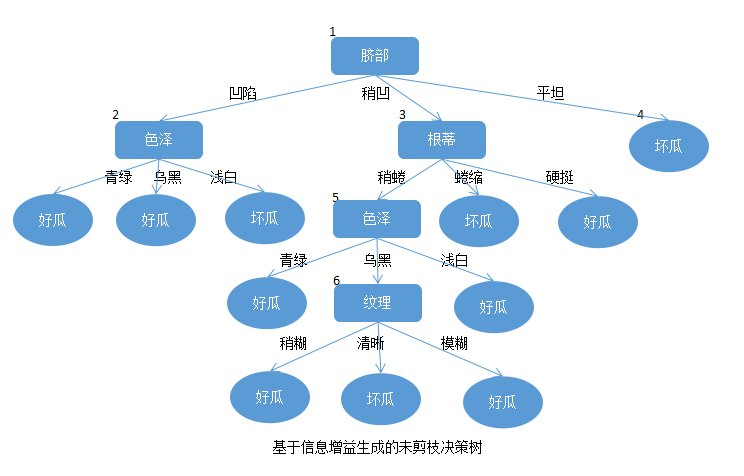
在进行划分时,对于要剪枝的节点需注意的是:
第一步:
对根节点进行剪枝预估,对于根节点来说,所有训练集入选,则根据训练集中类别最多的进行标记,因为训练集中好瓜坏瓜的数量相同,可以任选一个,于是将1节点标记为好瓜。对根节点剪枝后为如图所示:

其意思为,不管你新来的数据的任何属性,只要来一个西瓜我就认为是好瓜,那么这样剪枝在验证集上只有对
在用属性“脐部”划分后2,3,4节点分别包含训练集中数据为
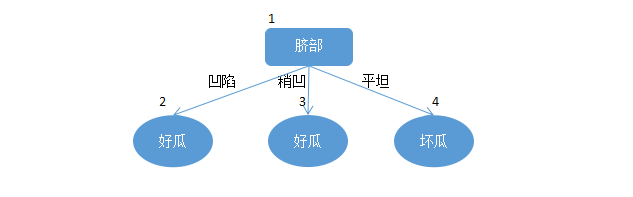
上面的图是在对“脐部”进行划分后的决策树,其在验证集上分别对
第二步:
对节点2进行剪枝预估。如果对2节点的“色泽”进行剪枝,则剪枝完后的决策树如图:
其在验证集上的精度为:
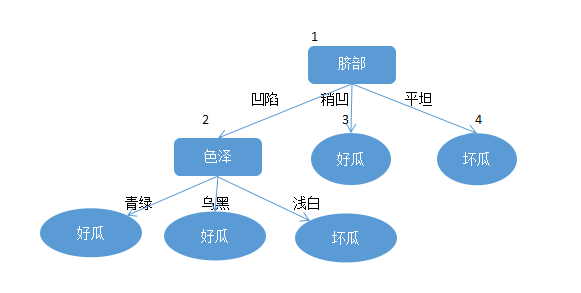
那么未剪枝的决策树在验证集上对
第三步:
对节点3进行剪枝预估。如果对3节点的“根蒂”进行剪枝,则剪枝完后的决策树如图:
其在验证集上的精度为:
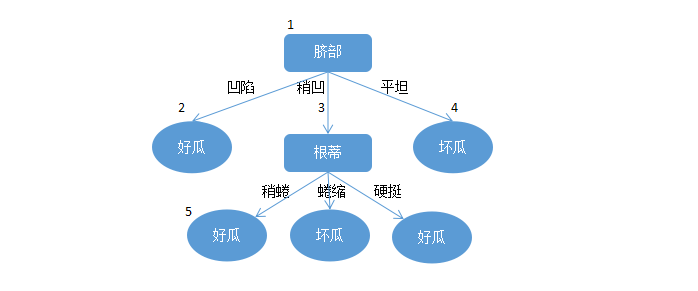
对于5节点,其包含训练集数据
第四步:
对节点4进行剪枝预估。因为4节点已经为一个叶子节点了,所以不再进行剪枝。
于是最终决策树模型为:
可以看出,前剪枝是的决策树的很多分支没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间的开销。但另一方面,在有些分支上虽然暂时不能提高泛化能力,但是在该节点的后续节点上面却能提高泛化能力,而没有得以展开,所以带来了欠拟合的风险。
后剪枝
后剪枝先从训练集生成一棵完整的决策树,如图,该树在验证集上的精度为
后剪枝考虑的策略是对已经生成的决策树自底向上对节点进行考量。
第一步:
首先考虑6节点,将其替换为叶节点,所以该节点包含的训练集数据为
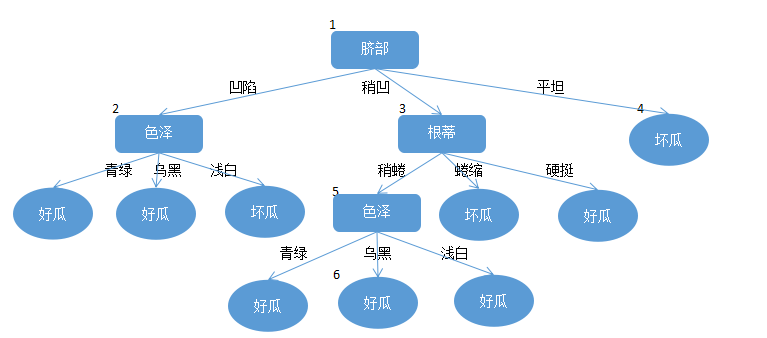
那么该树在验证集上的精度为
第二步:
考虑5节点,如果对其进行剪枝,其节点包含训练集数据
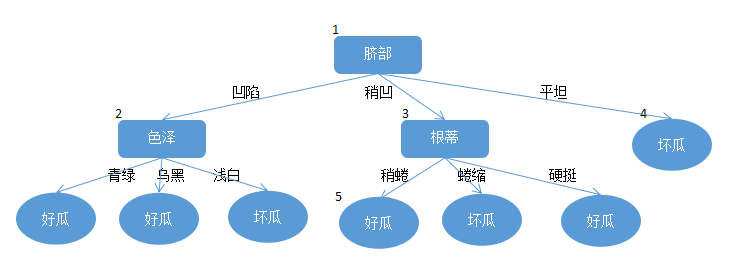
此决策树在验证集上的精度为
第三步:
对节点2进行预估。在该节点的训练数据集为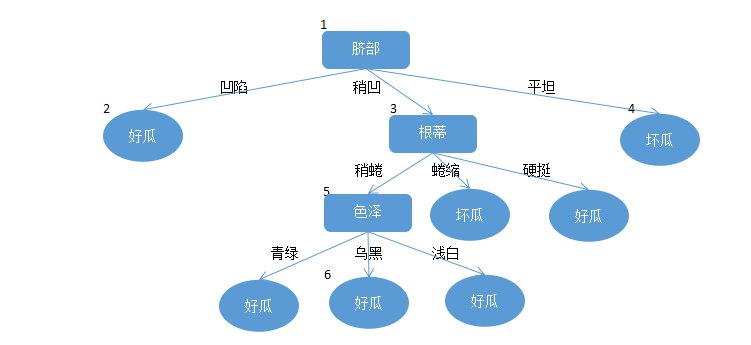
此时在验证集上精度提高到
第四步:
对节点3,1节点进行预估。均未能在验证集上提高精度。所以对3,1节点不进行剪枝处理。第三步生成的决策树即为最终的决策树。
[1]《机器学习》周志华
[2]《统计学习方法》李航
- 决策树梳理
- 梳理
- 梳理
- 梳理
- 梳理
- 梳理
- 梳理
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- 决策树
- windows上搭建mongodb Replica Set
- Week Training: 215 Kth Largest Element in an Array
- 数独问题
- struts2获取界面数据的3种方式
- JAVA面向对象的思想
- 决策树梳理
- Linux文件访问权限
- Mac上tomcat使用https
- 手机充电器电源适配器原理
- 基于jquery,自己编写的基本验证
- MFC设置工具栏按钮Tip方法总结
- thinkphp3.2.3中Class '?' not found的原因以及解决方法
- java类加载器(java.lang.ClassLoader) 与 Class.forName()
- 神经网络入门 ,源码2


