核方法以及核函数讲解
来源:互联网 发布:明底线知规矩守纪律 编辑:程序博客网 时间:2024/05/18 18:20
核方法的主要思想是基于这样一个假设:“在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很有可能变为线性可分的” ,例如下图
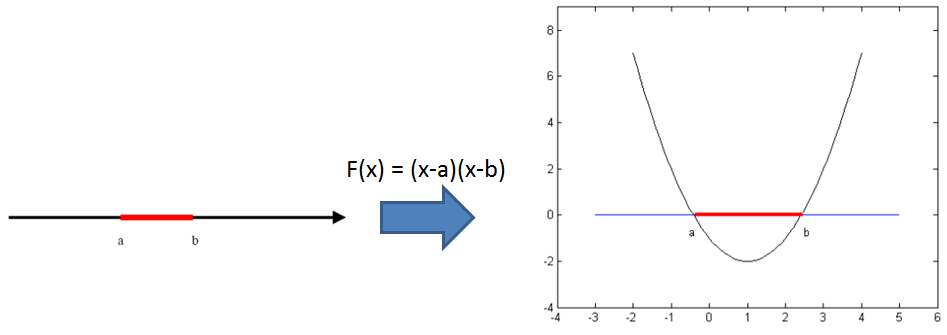
左图的两类数据要想在一维空间上线性分开是不可能的,然而通过F(x)=(x-a)(x-b)把一维空间上的点转化为右图上的二维空间上,就是可以线性分割的了。
然而,如果直接把低维度的数据转化到高维度的空间中,然后再去寻找线性分割平面,会遇到两个大问题,一是由于是在高维度空间中计算,导致curse of dimension问题;二是非常的麻烦,每一个点都必须先转换到高维度空间,然后求取分割平面的参数等等;怎么解决这些问题?答案是通过核戏法(kernel trick)。
(pku, shinningmonster, sewm)
Kernel Trick: 定义一个核函数K(x1,x2) = <\phi(x1), \phi(x2)>, 其中x1和x2是低维度空间中点(在这里可以是标量,也可以是向量),\phi(xi)是低维度空间的点xi转化为高维度空间中的点的表示,< , > 表示向量的内积。
这里核函数K(x1,x2)的表达方式一般都不会显式地写为内积的形式,即我们不关心高维度空间的形式。核函数巧妙地解决了上述的问题,在高维度中向量的内积通过低维度的点的核函数就可以计算了。这种技巧被称为Kernel trick。这里还有一个问题:“为什么我们要关心向量的内积?”,一般地,我们可以把分类(或者回归)的问题分为两类:参数学习的形式和基于实例的学习形式。
参数学习的形式就是通过一堆训练数据,把相应模型的参数给学习出来,然后训练数据就没有用了,对于新的数据,用学习出来的参数即可以得到相应的结论;
而基于实例的学习(又叫基于内存的学习)则是在预测的时候也会使用训练数据,如KNN算法。而基于实例的学习一般就需要判定两个点之间的相似程度,一般就通过向量的内积来表达。从这里可以看出,核方法不是万能的,它一般只针对基于实例的学习。
紧接着,我们还需要解决一个问题,即核函数的存在性判断和如何构造? 既然我们不关心高维度空间的表达形式,那么怎么才能判断一个函数是否是核函数呢?
Mercer 定理:任何半正定的函数都可以作为核函数。所谓半正定的函数f(xi,xj),是指拥有训练数据集合(x1,x2,...xn),我们定义一个矩阵的元素aij = f(xi,xj),这个矩阵式n*n的,如果这个矩阵是半正定的,那么f(xi,xj)就称为半正定的函数。这个mercer定理不是核函数必要条件,只是一个充分条件,即还有不满足mercer定理的函数也可以是核函数。常见的核函数有高斯核,多项式核等等,在这些常见核的基础上,通过核函数的性质(如对称性等)可以进一步构造出新的核函数。SVM是目前核方法应用的经典模型。
1 核方法的作用
目的:找出并学习一组数据中的相互的关系。用途较广的核方法有支持向量机、高斯过程等。核方法是解决非线性模式分析问题的一种有效途径。
2 核方法的思想
核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。
3 核方法的优势
知识。
4 核方法的提出和详解
5 问题待解决
一个矩阵是半正定,正定本质上起了什么作用呢?我将会对这个问题讨论。
核函数方法简介
(1)核函数发展历史
(2)核函数方法原理
(3)核函数特点
(4)常见核函数
1)高斯核函数K(x,xi) =exp(-||x-xi||2/2σ2;
(5)核函数方法实施步骤
特征空间;
(6)核函数在模式识别中的应用
- 核方法以及核函数讲解
- 核函数的深入浅出讲解
- SVM的核函数生动讲解
- 转载SVM讲解二(SVM核函数)
- python字符串内建函数方法讲解
- MySQL日期和时间函数讲解(以及时间转换)
- Opencv中的copyMakeBorder和borderInterpolate以及getRectSubPix函数讲解
- opencv 计时函数,以及方法
- 了解Oracle补丁以及应用方法(案例讲解)
- 内部类的概述讲解以及访问方法
- 核函数方法简介
- 核函数方法
- 核函数方法简介
- 核函数方法
- 核函数方法简介
- 核函数方法简介
- 基于API函数的串口通信(方法讲解)
- SVM原理---公式推导以及核函数
- TDD(一)
- ACM所有算法
- linux用户权和用户组
- Azure Messaging-ServiceBus Messaging消息队列技术系列4-复杂对象消息是否需要支持序列化和消息持久化
- 硬币配凑-动态规划-无
- 核方法以及核函数讲解
- java 基础知识部分提炼
- Spring Bean注入、销毁时执行指定行为
- 解析Linux下文件和目录权限。。。
- hadoop的安装
- 用WinHex在NTFS分区中恢复被删除的文件
- li onclick事件获取index JQuery
- ExpendListView箭头移动到右边的解决方案
- java迭代器


