记2017.3.21阿里面试经历,java方向
来源:互联网 发布:医院耗材管理软件 源码 编辑:程序博客网 时间:2024/04/29 19:04
1. Java有什么新特性
- Java语言
- 编译器
- 类库
- 工具
- Java运行时
1. 1 Java语言
- Lambda表达式(闭包)允许把函数作为一个方法的参数,或者把代码看成数据。
Arrays.asList("a","b","d").forEach(e->System.out.println(e));Arrays.asList( "a", "b", "d" ).forEach( e -> { System.out.print( e ); System.out.print( e );} );Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> e1.compareTo( e2 ) );- 增加函数式接口,可以被隐式转换为lambda表达式@FunctionInterface,默认方法与静态方法并不影响函数式接口的契约。
- 接口的默认方法与静态方法,所有实现者将会默认继承它(如果有必要的话,可以覆盖这个默认实现)
- 方法引用:构造器引用Class::new(无参),静态方法引用Class::static_method,特定类的任意对象Class::method,特定对象instance::method
- 重复注解
1. 2 Java编译器的新特性
- 参数名字,方便获取参数名字
1. 3 Java类库的新特性
- Optional 一个容器,可以保存类型T的值,或者仅仅保存null,提供有用的方法,这样我们就不用显示进行空值检。如果Optional类的实例为非空值的话,isPresent()返回true,否则返回false,为了防止Optional为空值,orElseGet()方法通过回调函数来产生一个默认值。map()函数对当前Optional的值进行转换,然后返回一个新的Optional实例。
- Stream 真正的函数式变成风格引入到Java中,极大简化了集合框架的处理。
- Date/Time API Clock类,指定时区,获得当前时刻,日期,时间
- parrellelSort()方法,在多核机器上极大提高数组排序速度。
Optional< String > fullName = Optional.ofNullable( null );System.out.println( "Full Name is set? " + fullName.isPresent() ); System.out.println( "Full Name: " + fullName.orElseGet( () -> "[none]" ) ); System.out.println( fullName.map( s -> "Hey " + s + "!" ).orElse( "Hey Stranger!" ) );
2. synchronized如何实现
- 对象头 Mark
- 偏向锁
- 轻量级锁
- 自旋锁
- 锁的升级过程
- synchronized用法:
- synchronized的缺陷:
- 形象的比喻
打个比方:一个object就像一个大房子,大门永远打开。房子里有 很多房间(也就是方法)。
这些房间有上锁的(synchronized方法), 和不上锁之分(普通方法)。房门口放着一把钥匙(key),这把钥匙可以打开所有上锁的房间。
另外我把所有想调用该对象方法的线程比喻成想进入这房子某个 房间的人。所有的东西就这么多了,下面我们看看这些东西之间如何作用的。
在此我们先来明确一下我们的前提条件。该对象至少有一个synchronized方法,否则这个key还有啥意义。当然也就不会有我们的这个主题了。
一个人想进入某间上了锁的房间,他来到房子门口,看见钥匙在那儿(说明暂时还没有其他人要使用上锁的 房间)。于是他走上去拿到了钥匙,并且按照自己 的计划使用那些房间。注意一点,他每次使用完一次上锁的房间后会马上把钥匙还回去。即使他要连续使用两间上锁的房间,中间他也要把钥匙还回去,再取回来。
因此,普通情况下钥匙的使用原则是:“随用随借,用完即还。”
这时其他人可以不受限制的使用那些不上锁的房间,一个人用一间可以,两个人用一间也可以,没限制。但是如果当某个人想要进入上锁的房间,他就要跑到大门口去看看了。有钥匙当然拿了就走,没有的话,就只能等了。
要是很多人在等这把钥匙,等钥匙还回来以后,谁会优先得到钥匙?Not guaranteed。象前面例子里那个想连续使用两个上锁房间的家伙,他中间还钥匙的时候如果还有其他人在等钥匙,那么没有任何保证这家伙能再次拿到。
再来看看同步代码块。和同步方法有小小的不同。
1.从尺寸上讲,同步代码块比同步方法小。你可以把同步代码块看成是没上锁房间里的一块用带锁的屏风隔开的空间。
2.同步代码块还可以人为的指定获得某个其它对象的key。就像是指定用哪一把钥匙才能开这个屏风的锁,你可以用本房的钥匙;你也可以指定用另一个房子的钥匙才能开,这样的话,你要跑到另一栋房子那儿把那个钥匙拿来,并用那个房子的钥匙来打开这个房子的带锁的屏风。
记住你获得的那另一栋房子的钥匙,并不影响其他人进入那栋房子没有锁的房间。
为什么要使用同步代码块呢?我想应该是这样的:首先对程序来讲同步的部分很影响运行效率,而一个方法通常是先创建一些局部变量,再对这些变量做一些 操作,如运算,显示等等;而同步所覆盖的代码越多,对效率的影响就越严重。因此我们通常尽量缩小其影响范围。
3. 事务介绍
http://blog.csdn.net/zhanghaor/article/details/570843504. Redis与关系型数据库的同步问题

也就是说:我们会先去redis中判断数据是否存在,如果存在,则直接返回缓存好的数据。而如果不存在的话,就会去数据库中,读取数据,并把数据缓存到Redis中。适用场合:如果数据量比较大,但不是经常更新的情况(比如用户排行)
而第二种Redis的使用,跟第一种的情况完成不同,具体的情况请看:
5. 数据库索引
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
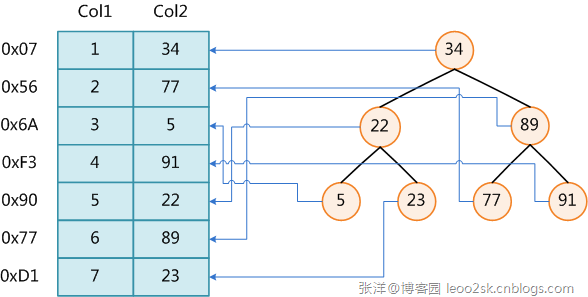
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
一般说来,应该在这些列上建立索引:
在经常需要搜索的列上,可以加快搜索的速度,
在作为主键的列上,强制该列的唯一性和组织表中的排列结构
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度
在需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询的时间
在经常使用where子句中的列上面创建索引,加快条件的判断速度。
- 记2017.3.21阿里面试经历,java方向
- 阿里--java面试经历
- 阿里面试经历及总结(数据研发、Java研发方向)+个人经历
- 阿里面试经历JAVA总结
- 阿里面试经历及总结(数据研发、Java研发方向)
- 阿里面试经历及总结(数据研发、Java研发方向)
- 阿里面试经历及总结(数据研发、Java研发方向)
- 阿里实习面试经历
- 阿里C++面试经历
- 阿里C++面试经历
- 阿里腾讯面试经历
- 阿里实习生面试经历
- 阿里面试经历总结
- 阿里电话面试经历
- 阿里面试经历
- Java Web架构知识整理——记一次阿里面试经历
- Java Web架构知识整理——记一次阿里面试经历
- Java Web架构知识整理——记一次阿里面试经历
- 顺序容器---string详解
- C++模板实现链表队列
- 多标签分类问题
- Resin常用配置
- Js报错Uncaught SyntaxError: Unexpected token <
- 记2017.3.21阿里面试经历,java方向
- L2-013 红色警报 并查集
- 链表反转
- Pandas 分割字符串
- Ubuntu_Hadoop_v2.6环境搭建
- salt内置模块列表
- Linux基础知识了解
- 如何解决谷歌浏览器在安装流氓软件之后被篡改主页的问题
- Linux wget命令用法详解


