分布式架构中一致性解决方案——Zookeeper集群搭建
来源:互联网 发布:做淘宝天猫优惠券 编辑:程序博客网 时间:2024/05/16 01:51
我们需要多台机器共同commit事务,经典的案例当然是银行转账,支付宝转账这种,如果是一台机器的话,这个还是很方便的,windows中自带了一个事务协
调器mstsc,但是呢,你那种很大很牛逼的项目不可能全是windows服务器,对吧,有些人为了解决这个问题,会采用2pc,3pc这种算法,或者是paxos的思
想进行分布式下的一致性处理,当然在这个世界上,真的不需要你自己去开发这种协调性,因为现在已经有了专门解决这种问题的解决方案,比如zookeeper。
一:zookeeper集群搭建
有些人应该明白,zookeeper正是google的chubby的开源实现,使用zookeeper之前,我们先来搭建一个集群。
1. 下载
从官网上,我们可以看到,zookeeper的最新版本是3.4.8,下载地址是:http://apache.fayea.com/zookeeper/zookeeper-3.4.8/,可以下载一下:
2. 文件夹配置
接下来我们解压一下,根目录为zkcluster,下面使用clientport(3000,3001,3002)这样的端口作为文件夹名称,里面就是zookeeper解压包,如下面这样:

3. 配置zoo.cfg
现在我们有三个文件夹,也就是3个zookeeper程序,在3001/conf/下面有一个zoo_sample.cfg文件,现在我们改成zoo.cfg,并且修改如下:
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial # synchronization phase can takeinitLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.dataDir=/root/zkcluster/3001/datadataLogDir=/root/zkcluster/3001/logs# the port at which the clients will connectclientPort=3001# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=6## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1server.1=192.168.161.134:2888:3888server.2=192.168.161.134:2889:3889server.3=192.168.161.134:2890:3890
这里我们要注意的是,红色的部分分别就是:指定zookeeper的data和log文件夹,指定clientport访问的端口和servers的列表。
4. 生成pid文件
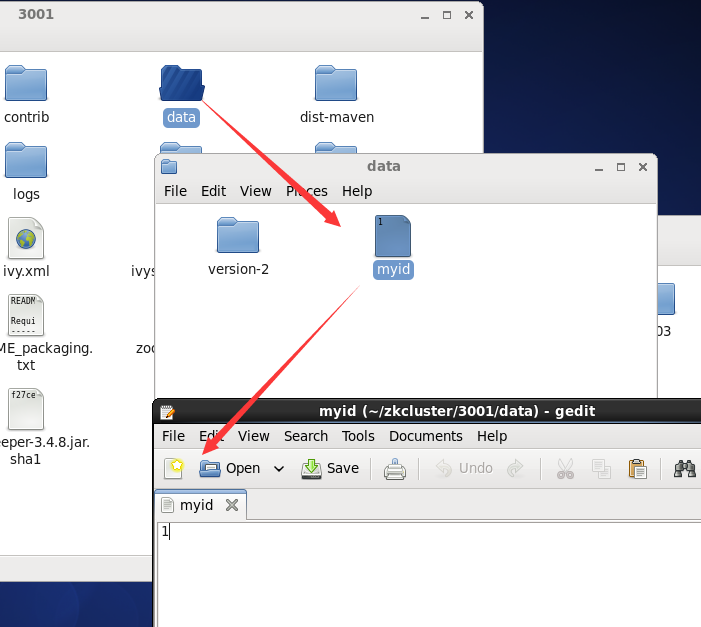
我们在servers列表中,可以看到有server.1 ,server.2, server.3 三个字符串,生成pid文件的内容就取决如此,比如server.1的地址,
我们的pid文件里面就是1,不过要知道的是,pid文件要在data目录下,比如下面这样:
ok,同样的道理,3002和3003的文件夹同3001就可以了,比如他们的zoo.cfg如下:
-------- 3002 --------------
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial # synchronization phase can takeinitLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.dataDir=/root/zkcluster/3002/datadataLogDir=/root/zkcluster/3002/logs# the port at which the clients will connectclientPort=3002# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=6## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1server.1=192.168.161.134:2888:3888server.2=192.168.161.134:2889:3889server.3=192.168.161.134:2890:3890
-------- 3003 --------------
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial # synchronization phase can takeinitLimit=10# The number of ticks that can pass between # sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just # example sakes.dataDir=/root/zkcluster/3003/datadataLogDir=/root/zkcluster/3003/logs# the port at which the clients will connectclientPort=3003# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=6## Be sure to read the maintenance section of the # administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1server.1=192.168.161.134:2888:3888server.2=192.168.161.134:2889:3889server.3=192.168.161.134:2890:3890
5. 启动各自服务器
到现在为止,我们各个zookeeper程序的配置都结束了,接下来我们到各自目录的bin目录下,通过zkServer.sh来进行启动,比如下面这样: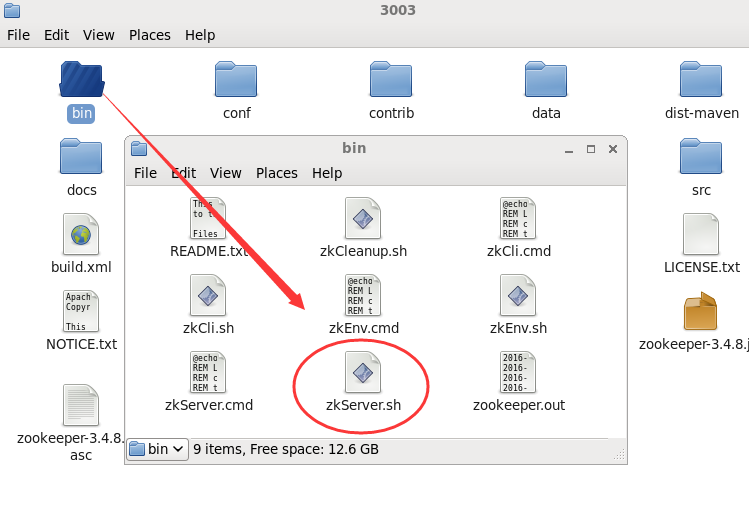
ok,接下来我们来开始启动,通过如下命令即可:
./zkServer.sh start-foreground
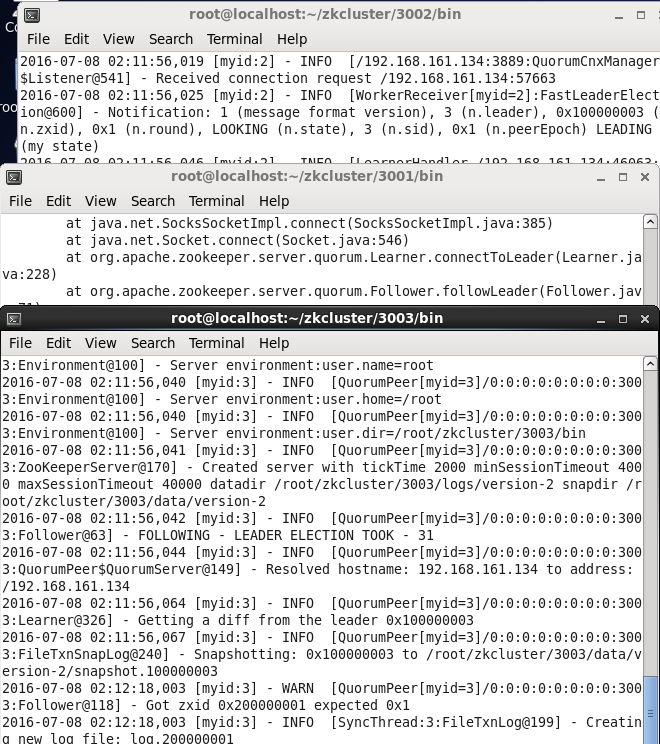
现在我们都启动了,接下来我们可以用命令看下哪个server是leader,哪些是follower。。。
[root@localhost bin]# ./zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /root/zkcluster/3001/bin/../conf/zoo.cfgMode: follower[root@localhost bin]# [root@localhost bin]# ./zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /root/zkcluster/3002/bin/../conf/zoo.cfgMode: leader[root@localhost bin]# [root@localhost bin]# ./zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /root/zkcluster/3003/bin/../conf/zoo.cfgMode: follower[root@localhost bin]#
到目前为止,我们的服务端操作都ok啦,,,是不是好吊。。。
二:驱动下载
1. java的驱动就方便了,直接在源代码中就提供了,直接copy一下lib文件夹中的jar包就ok了,真是tmd的方便。
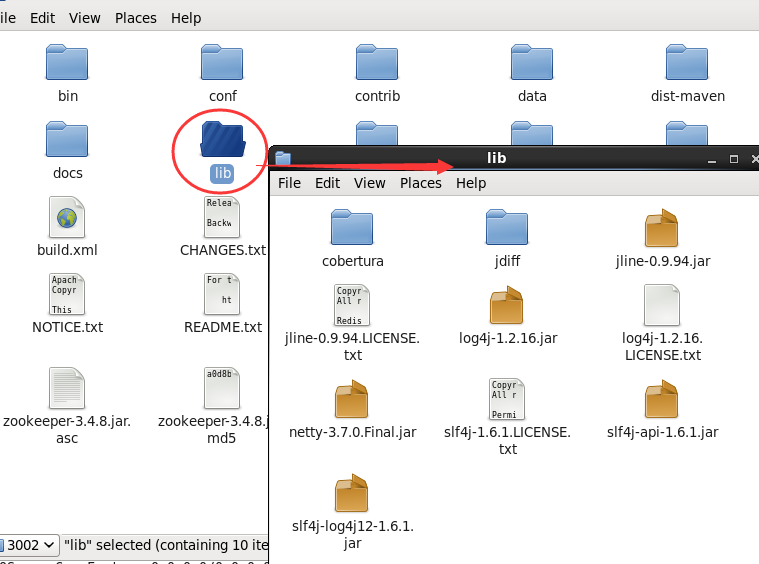
2. 用C#驱动的也不要太烦,要使用也是不难的,我们可以通过nuget下载一下就可以了,转换过来的版本也是3.4.8的最新版本,比如下面这样:
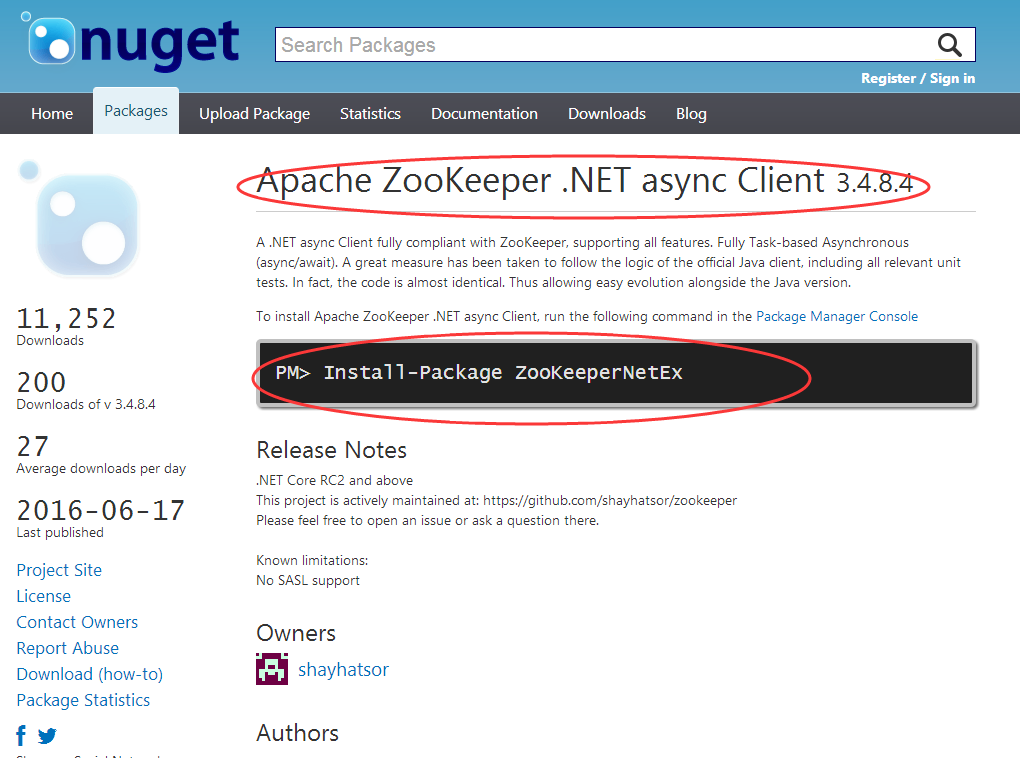
好了,大概就说这么多,希望对你有帮助~~~
- 分布式架构中一致性解决方案——Zookeeper集群搭建
- 分布式架构中一致性解决方案——Zookeeper集群搭建
- 分布式架构中一致性解决方案——Zookeeper集群搭建
- Zookeeper分布式集群搭建
- 搭建zookeeper 分布式集群
- ~搭建JEESZ分布式架构6--ZooKeeper 集群的安装
- ZooKeeper完全分布式集群搭建
- zookeeper伪分布式集群搭建
- 一脸懵逼搭建Zookeeper分布式集群
- Zookeeper源码分析——请求处理与分布式一致性
- 【Memcached】集群搭建——集群,分布式以及分布式集群
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
- zookeeper伪分布式集群环境搭建
- Zookeeper伪分布式集群环境搭建过程
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
- zookeeper伪分布式集群搭建(centOS7)
- HaDoop_分布式集群搭建(zookeeper,hadoop)
- HBase 分布式安装搭建/独立Zookeeper集群
- asp.net mvc 之旅—— 第四站 学会用Reflector调试我们的MVC框架代码
- 搭建高可用的redis集群,避免standalone模式带给你的苦难
- 几个资料地址保存
- 几个开源的视频编解码器介绍
- STL泛型编程
- 分布式架构中一致性解决方案——Zookeeper集群搭建
- java爬虫crawler4j:SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
- asp.net mvc 之旅 —— 第五站 从源码中分析asp.net mvc 中的TempData
- javascript
- linux多进程通讯
- asp.net mvc 之旅 —— 第六站 ActionFilter的应用及源码分析
- mongodb 3.x 之实用新功能窥看[1] ——使用TTLIndex做Cache处理
- bzoj1045: [HAOI2008] 糖果传递
- Linux(Centos)安装tomcat


