python-recsys 4 Algorithms 4 算法
来源:互联网 发布:正版办公软件 编辑:程序博客网 时间:2024/06/10 15:56
pyrecsys提供开箱即用的,一些基本的基于矩阵分解的算法
4.0 SVD
为了分解输入数据(矩阵),pyrecsys使用了SVD算法。一旦矩阵降到低维空间,pyrecsys可以提供预测,推荐和‘元素’(用户或者物品,这取决于你加载数据的问题)的相似度。
4.0.0 加载数据
如何加载数据集(以Movielens 10M为例)?
from recsys.algorithm.factorize import SVDfilename = './data/movielens/ratings.dat'svd = SVD()svd.load_data(filename=filename, sep='::', format={'col':0, 'row':1, 'value':2, 'ids': int}) # About format parameter: # 'row': 1 -> Rows in matrix come from second column in ratings.dat file # 'col': 0 -> Cols in matrix come from first column in ratings.dat file # 'value': 2 -> Values (Mij) in matrix come from third column in ratings.dat file # 'ids': int -> Ids (row and col ids) are integers (not strings)分离数据集(训练和测试):
from recsys.datamodel.data import Datafrom recsys.algorithm.factorize import SVDfilename = './data/movielens/ratings.dat'data = Data()format = {'col':0, 'row':1, 'value':2, 'ids': int}data.load(filename, sep='::', format=format)train, test = data.split_train_test(percent=80) # 80% train, 20% testsvd = SVD()svd.set_data(train)
加载一个文件,执行外部SVDLIBC项目,创建一个SVD实例:
from recsys.utils.svdlibc import SVDLIBCsvdlibc = SVDLIBC('./data/movielens/ratings.dat')svdlibc.to_sparse_matrix(sep='::', format={'col':0, 'row':1, 'value':2, 'ids': int}) # Convert to sparse matrix format [http://tedlab.mit.edu/~dr/SVDLIBC/SVD_F_ST.html]svdlibc.compute(k=100)svd = svdlibc.export()
4.0.1 计算
>>> K=100>>> svd.compute(k=K, min_values=10, pre_normalize=None, mean_center=True, post_normalize=True, savefile=None)
参数:
min_values:以小于min_values的非零值,从输入矩阵中移除列或者行
pre_normalize:
thidf:
rows:
cols:
all:
mean_center:
post_normalize:
savefile:
4.0.2 预测
预测评级, 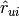 , SVD类重构原始矩阵,
, SVD类重构原始矩阵, 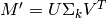
>>> svd.predict(ITEMID, USERID, MIN_RATING=0.0, MAX_RATING=5.0)等价于:
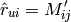
这是Movielens 10M数据集的RMSE和MAE(训练:8000043ratings,测试:2000011),使用5-fold交叉验证,不同的k值或因数(10,20,50,100) for SVD:
K102050100RMSE0.872240.867740.865570.86628MAE0.671140.667190.664840.66513
4.0.3 推荐
推荐也来自
>>> svd.recommend(USERID, n=10, only_unknowns=True, is_row=False)返回
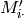
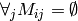 的更高值,同时:
的更高值,同时:>>> svd.recommend(USERID, n=10, only_unknowns=False, is_row=False)返回最适合用户的物品。
4.1 Neighbourhood SVD
经典近邻算法使用相似用户(或物品)的评级来预测输出矩阵M的值
from recsys.algorithm.factorize import SVDNeighbourhoodsvd = SVDNeighbourhood()svd.load_data(filename=sys.argv[1], sep='::', format={'col':0, 'row':1, 'value':2, 'ids': int})K=100svd.compute(k=K, min_values=5, pre_normalize=None, mean_center=True, post_normalize=True)4.1.0 预测
与普通SVD唯一的不同是计算预测值的方式:
>>> svd.predict(ITEMID, USERID, weighted=True, MIN_VALUE=0.0, MAX_VALUE=5.0)为例计算预测值,使用以下方程(u=USERID, i=ITEMID):
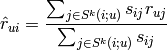
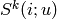 代表被u评级的与i最相似的k个商品的集。
代表被u评级的与i最相似的k个商品的集。 has already rated
has already rated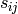 is the similarity between
is the similarity between 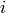 and
and 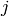 , computed using svd.similarity(i, j)。
, computed using svd.similarity(i, j)。
4.1.2 对比
For those who love RMSE, MAE and the like, here are some numbers comparing both SVD approaches. The evaluation uses the Movielens 1M ratings dataset, splitting the train/test dataset with ~80%-20%。
Note
Computing svd k=100, min_values=5, pre_normalize=None, mean_center=True, post_normalize=True
Warning
Because of min_values=5, some rows (movies) or columns (users) in the input matrix are removed. In fact, those movies that had less than 5 users who rated it, and those users that rated less than 5 movies are removed.
4.1.3 结果
Movielens 1M dataset (number of ratings in the Test dataset: 209,908):
- python-recsys 4 Algorithms 4 算法
- python-recsys Library中文文档
- python-recsys 1 Installation 1 安装
- python-recsys 2 Quickstart 2 快速开始
- python-recsys 3 Data model 3 数据模型
- python-recsys:一款实现推荐系统的python库
- 《算法》第四版《Algorithms》4th Edition 学习环境搭建
- Algorithms Edition 4 chapter 1 percolation 算法第一章课后作业
- STL(4)之Removing Algorithms
- "algorithms 4th"---symbol table
- 【Python学习系列七】Windows下部署Python推荐系统recsys
- Introduction to Algorithms 算法导论 第4章 递归式 学习笔记及习题解答
- 【面试笔试算法】Program 4 : Best Compression Algorithms(网易游戏笔试题)
- 《算法》第4版(Algorithms Fourth Edition)在Eclipse下的重定向与管道问题
- STL算法(Algorithms):极值
- STL算法(Algorithms):排序
- 贪心算法(Greedy Algorithms)
- 压缩算法(Compression algorithms)
- 图的最小生成树
- HUSTOJ搭建执行(LAMP+hustoj+myphpadmin)
- 消除重复元素
- Aladdin and the Flying Carpet LightOJ
- 蓝桥杯 城市建设(kruscal变形)
- python-recsys 4 Algorithms 4 算法
- Lua函数的多个返回值【转】
- Java多线程总结(二)锁、线程池
- 一步一步学ROP之linux_x64篇
- 多线程基础
- C#学习日记 链表
- 33个网站搞定一切中外电子书籍及杂志
- Leetcode——45Jump GameII
- 20170401-leetcode-435-Non-overlapping Intervals


