2017/4/3 csp-Markdown
来源:互联网 发布:金石造价软件下载 编辑:程序博客网 时间:2024/06/14 02:19
试题编号:201703-3试题名称:Markdown时间限制:1.0s内存限制:256.0MB问题描述:
问题描述
Markdown 是一种很流行的轻量级标记语言(lightweight markup language),广泛用于撰写带格式的文档。例如以下这段文本就是用 Markdown 的语法写成的:
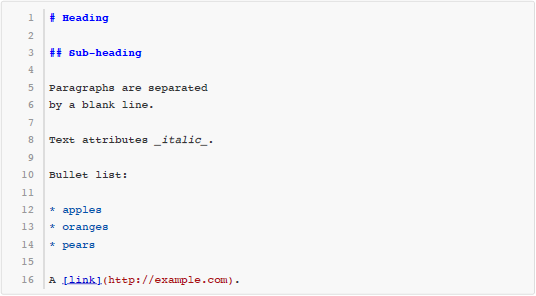
这些用 Markdown 写成的文本,尽管本身是纯文本格式,然而读者可以很容易地看出它的文档结构。同时,还有很多工具可以自动把 Markdown 文本转换成 HTML 甚至 Word、PDF 等格式,取得更好的排版效果。例如上面这段文本通过转化得到的 HTML 代码如下所示:
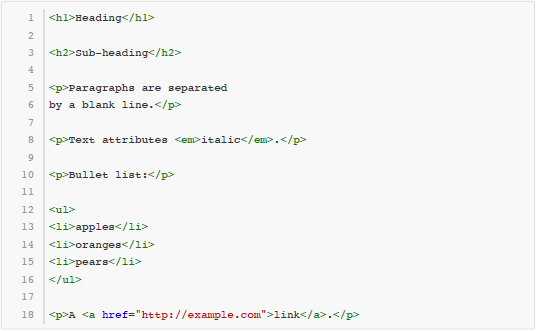
本题要求由你来编写一个 Markdown 的转换工具,完成 Markdown 文本到 HTML 代码的转换工作。简化起见,本题定义的 Markdown 语法规则和转换规则描述如下:
●区块:区块是文档的顶级结构。本题的 Markdown 语法有 3 种区块格式。在输入中,相邻两个区块之间用一个或多个空行分隔。输出时删除所有分隔区块的空行。
○段落:一般情况下,连续多行输入构成一个段落。段落的转换规则是在段落的第一行行首插入 `<p>`,在最后一行行末插入 `</p>`。
○标题:每个标题区块只有一行,由若干个 `#` 开头,接着一个或多个空格,然后是标题内容,直到行末。`#` 的个数决定了标题的等级。转换时,`# Heading` 转换为 `<h1>Heading</h1>`,`## Heading` 转换为 `<h2>Heading</h2>`,以此类推。标题等级最深为 6。
○无序列表:无序列表由若干行组成,每行由 `*` 开头,接着一个或多个空格,然后是列表项目的文字,直到行末。转换时,在最开始插入一行 `<ul>`,最后插入一行 `</ul>`;对于每行,`* Item` 转换为 `<li>Item</li>`。本题中的无序列表只有一层,不会出现缩进的情况。
●行内:对于区块中的内容,有以下两种行内结构。
○强调:`_Text_` 转换为 `<em>Text</em>`。强调不会出现嵌套,每行中 `_` 的个数一定是偶数,且不会连续相邻。注意 `_Text_` 的前后不一定是空格字符。
○超级链接:`[Text](Link)` 转换为 `<a href="Link">Text</a>`。超级链接和强调可以相互嵌套,但每种格式不会超过一层。
这些用 Markdown 写成的文本,尽管本身是纯文本格式,然而读者可以很容易地看出它的文档结构。同时,还有很多工具可以自动把 Markdown 文本转换成 HTML 甚至 Word、PDF 等格式,取得更好的排版效果。例如上面这段文本通过转化得到的 HTML 代码如下所示:
本题要求由你来编写一个 Markdown 的转换工具,完成 Markdown 文本到 HTML 代码的转换工作。简化起见,本题定义的 Markdown 语法规则和转换规则描述如下:
●区块:区块是文档的顶级结构。本题的 Markdown 语法有 3 种区块格式。在输入中,相邻两个区块之间用一个或多个空行分隔。输出时删除所有分隔区块的空行。
○段落:一般情况下,连续多行输入构成一个段落。段落的转换规则是在段落的第一行行首插入 `<p>`,在最后一行行末插入 `</p>`。
○标题:每个标题区块只有一行,由若干个 `#` 开头,接着一个或多个空格,然后是标题内容,直到行末。`#` 的个数决定了标题的等级。转换时,`# Heading` 转换为 `<h1>Heading</h1>`,`## Heading` 转换为 `<h2>Heading</h2>`,以此类推。标题等级最深为 6。
○无序列表:无序列表由若干行组成,每行由 `*` 开头,接着一个或多个空格,然后是列表项目的文字,直到行末。转换时,在最开始插入一行 `<ul>`,最后插入一行 `</ul>`;对于每行,`* Item` 转换为 `<li>Item</li>`。本题中的无序列表只有一层,不会出现缩进的情况。
●行内:对于区块中的内容,有以下两种行内结构。
○强调:`_Text_` 转换为 `<em>Text</em>`。强调不会出现嵌套,每行中 `_` 的个数一定是偶数,且不会连续相邻。注意 `_Text_` 的前后不一定是空格字符。
○超级链接:`[Text](Link)` 转换为 `<a href="Link">Text</a>`。超级链接和强调可以相互嵌套,但每种格式不会超过一层。
输入格式
输入由若干行组成,表示一个用本题规定的 Markdown 语法撰写的文档。
输出格式
输出由若干行组成,表示输入的 Markdown 文档转换成产生的 HTML 代码。
样例输入
# Hello
Hello, world!
Hello, world!
样例输出
<h1>Hello</h1>
<p>Hello, world!</p>
<p>Hello, world!</p>
评测用例规模与约定
本题的测试点满足以下条件:
●本题每个测试点的输入数据所包含的行数都不超过100,每行字符的个数(包括行末换行符)都不超过100。
●除了换行符之外,所有字符都是 ASCII 码 32 至 126 的可打印字符。
●每行行首和行末都不会出现空格字符。
●输入数据除了 Markdown 语法所需,内容中不会出现 `#`、`*`、`_`、`[`、`]`、`(`、`)`、`<`、`>`、`&` 这些字符。
●所有测试点均符合题目所规定的 Markdown 语法,你的程序不需要考虑语法错误的情况。
每个测试点包含的语法规则如下表所示,其中“√”表示包含,“×”表示不包含。
测试点编号
段落
标题
无序列表
强调
超级链接
1
√
×
×
×
×
2
√
√
×
×
×
3
√
×
√
×
×
4
√
×
×
√
×
5
√
×
×
×
√
6
√
√
√
×
×
7
√
×
×
√
√
8
√
√
×
√
×
9
√
×
√
×
√
10
√
√
√
√
√
●本题每个测试点的输入数据所包含的行数都不超过100,每行字符的个数(包括行末换行符)都不超过100。
●除了换行符之外,所有字符都是 ASCII 码 32 至 126 的可打印字符。
●每行行首和行末都不会出现空格字符。
●输入数据除了 Markdown 语法所需,内容中不会出现 `#`、`*`、`_`、`[`、`]`、`(`、`)`、`<`、`>`、`&` 这些字符。
●所有测试点均符合题目所规定的 Markdown 语法,你的程序不需要考虑语法错误的情况。
每个测试点包含的语法规则如下表所示,其中“√”表示包含,“×”表示不包含。
测试点编号
段落
标题
无序列表
强调
超级链接
1
√
×
×
×
×
2
√
√
×
×
×
3
√
×
√
×
×
4
√
×
×
√
×
5
√
×
×
×
√
6
√
√
√
×
×
7
√
×
×
√
√
8
√
√
×
√
×
9
√
×
√
×
√
10
√
√
√
√
√
提示
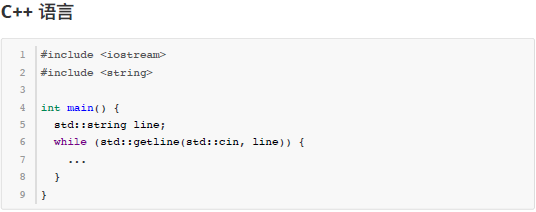
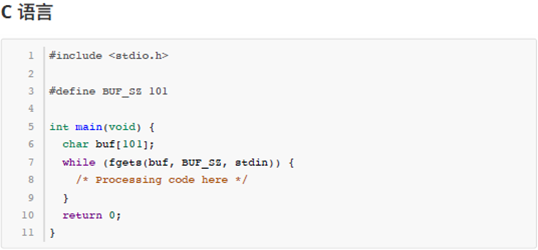
由于本题要将输入数据当做一个文本文件来处理,要逐行读取直到文件结束,C/C++、Java 语言的用户可以参考以下代码片段来读取输入内容。
题目不难 就是对字符串的操作 但是要仔细读题。一开始才60分..后面查了好久突然发现貌似...不是<u1>而是<ul>....然后就100了。我的个苍天
#include<iostream>#include<string>#include<stdio.h>#include<math.h>#include<algorithm>using namespace std;void _Text_(string &line){int i, k; string s;for (i = 0; i < line.length(); i++){if (line[i] == '_'){line.insert(i + 1, "<em>");line.erase(i, 1);for (k = i; k < line.length(); k++){if (line[k] == '_'){line.erase(k, 1);line.insert(k, "</em>");break;}}}}}void href(string &line){int i, k; string s;for (i = 0; i < line.length(); i++){if (line[i] == '['){string str = "";for (k = i + 1; k < line.length(); k++){if (line[k] != ']') str += line[k];else break;}s = "";char ss = '"';s = s + "<a href=" + ss;line.insert(k + 2, s);line.erase(i, str.length() + 3);for (k = i; k < line.length(); k++){if (line[k] == ')'){s = "";char ss = '"';s = s + ss + ">" + str + "</a>";line.erase(k, 1);line.insert(k, s);break;}}}}}int main(){string line, all, s;int size = 0, i, k;//freopen("C:\\Users\\user\\Desktop\\in.txt","r",stdin); 用于测试样例while (getline(cin, line)){if (line.length()==0){if (size == 1) { all += "</ul>";all+='\n'; size = 0; }else if (size == 2) { all += "</p>"; all += '\n'; size = 0; }else if (size == 3) { all += '\n'; size = 0; }}else if (line[0] == '#'){size = 3;int h = 0; s = "";for (i = 0; i < line.length(); i++){if (line[i] == '#') h++;else {if (line[i] != ' '){s = s + "<h" + (char)(h + '0') + ">";line.insert(i, s); s = "";line.erase(0, i);s = s + "</h" + (char)(h + '0') + ">";line.insert(line.length(), s); _Text_(line);href(line);all += line; break;}}}}else if (line[0] == '*'){if (size == 0) {all += "<ul>"; all += '\n';}size = 1;for (i = 0; i < line.length(); i++){if (line[i] != '*'&&line[i] != ' '){line.insert(i, "<li>"); line.erase(0, i);line.insert(line.length(),"</li>");_Text_(line);href(line);all += line;all+= '\n';break; }}}else{if (size == 0) line.insert(0,"<p>");else { all += '\n'; }size = 2;_Text_(line);href(line);//cout << line << endl;all += line;}}if (size == 1) { all += "</ul>"; size = 0; }else if (size == 2) { all += "</p>"; size = 0; }cout << all;return 0;} 2 0
- 2017/4/3 csp-Markdown
- csp 2017_3_3 markdown
- CCF-CSP认证题201703-3 Markdown
- CCF-CSP Markdown JAVA 201703-3
- CCF CSP Markdown JAVA 201703-3
- CCF CSP Markdown
- csp-ccf之Markdown
- CSP之 Markdown java
- csp-2017-3 分蛋糕
- csp-2017-3 学生排队
- CCF-CSP-2017-3-1 分蛋糕
- CCF-CSP-2017-3-2 学生排队
- csp ccf 2017 3修地铁问题
- CCF-CSP-2017-3-4 地铁修建(结构体优先队列)
- CCF CSP 2017年3月第4题 地铁修建(Kruskal算法)
- CSP 2017-09
- CSP 2017-03
- CSP
- 【bzoj2731】[HNOI2012]三角形覆盖问题
- 使用Caffe进行手写数字识别执行流程解析
- Dubbo框架学习笔记(一)
- linux内核部件分析(三)——记录生命周期的kref
- 大数据IMF传奇行动绝密课程第92课:SparkStreaming中Transformations和状态管理解密
- 2017/4/3 csp-Markdown
- 返回数组中的小数组的最大值
- visio粘贴到word中只显示一部分
- CSDN博客自定义栏目——Google、百度、必应站内搜索框
- leetcode 121
- 全排列
- 如何在官网上下载可安装版的MySQL数据库
- java的File类
- Spring MVC @ModelAttribute 使用


