机器学习 Python 库 Top 20
来源:互联网 发布:淘宝html代码生成器 编辑:程序博客网 时间:2024/04/30 17:30
如今开源是创新的核心,推动着技术的飞速革新。本文会为你介绍 2016 年机器学习 Top 20 Python 开源项目,同时分析得出一些有趣的见解和发展趋势。
KDnuggets 为您带来 Github 上最新的 Python 机器学习开源项目前 20 名。奇怪的是,去年一些非常活跃的项目渐渐停滞了,因此没能上榜,而 13 个新项目冲进了今年的 top 20(参考贡献 contributions 和提交数 commits)。
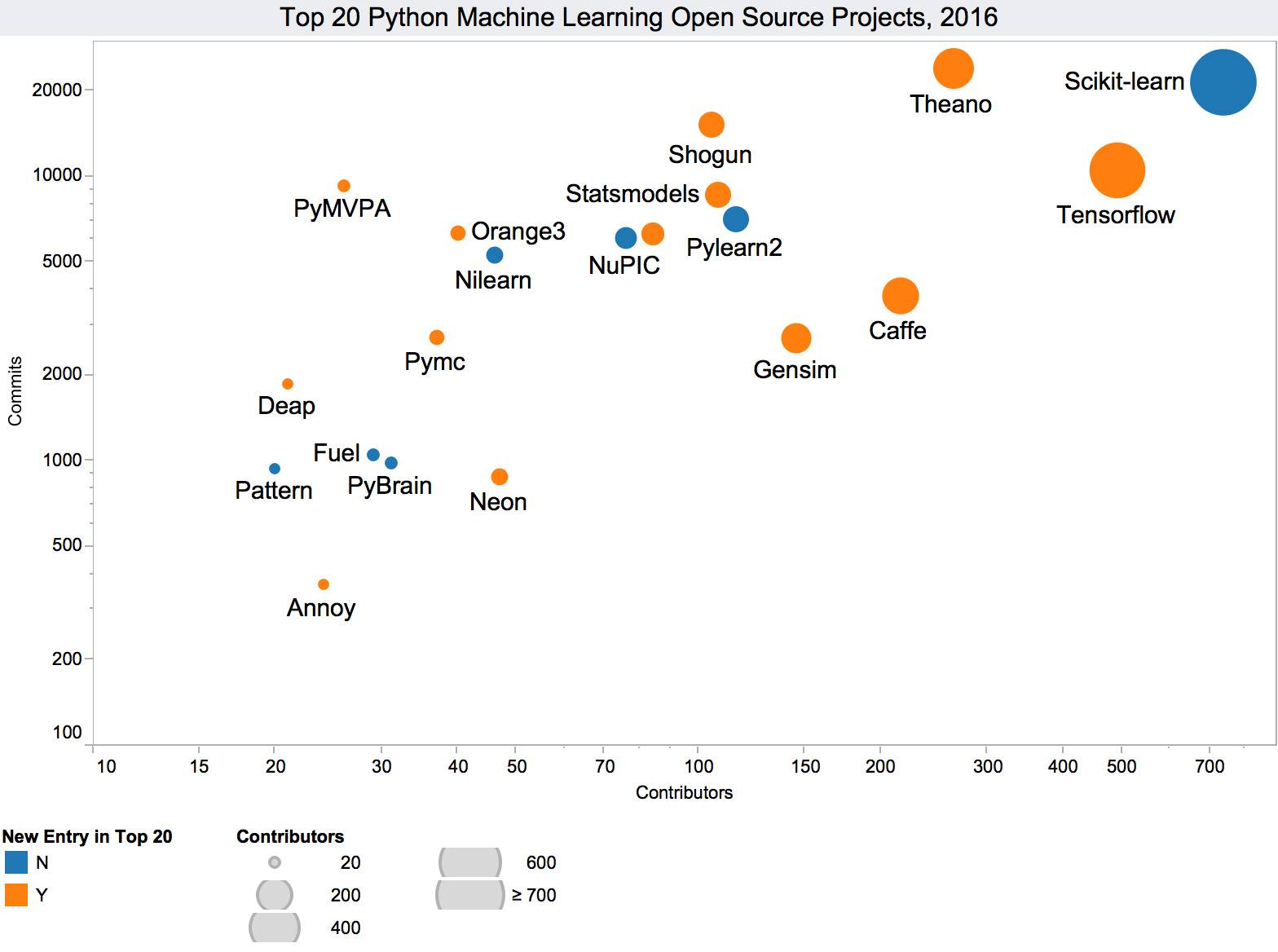
2016 Top 20 Python 机器学习开源项目
1. Scikit-learn是一个简单且高效的数据挖掘和数据分析工具,易上手,可以在多个上下文中重复使用。它基于NumPy, SciPy 和 matplotlib,开源,可商用(基于 BSD 许可)
提交数: 21486, 贡献者: 736, Github 链接: Scikit-learn(http://github.com/scikit-learn/scikit-learn0
2. Tensorflow 最初由谷歌机器智能科研组织中的谷歌大脑团队(Google Brain Team)的研究人员和工程师开发。该系统设计的初衷是为了便于机器学习研究,能够更快更好地将科研原型转化为生产项目。
提交数: 10466, 贡献者: 493, Github 链接: Tensorflow(https://github.com/tensorflow/tensorflow)
3. Theano 允许高效地定义、优化以及评估涉及多维数组的数学表达式. 提交数: 24108, 贡献者: 263, Github 链接: Theano(https://github.com/Theano/Theano)
4. Caffe 是一个基于表达式,速度和模块化原则创建的深度学习框架。它由伯克利视觉学习中心(BVLC, Berkeley Vision and Learning Center)和社区贡献者共同开发。 提交数: 3801, 贡献者: 215, Github 链接: Caffe(https://github.com/BVLC/caffe)
5. Gensim 是一个免费的 Python 库,它包含可扩展的统计语义,分析纯文本文档的语义结构,以及检索相似语义的文档等功能。
提交数: 2702, 贡献者: 145, Github 链接: Gensim(https://github.com/RaRe-Technologies/gensim)
6. Pylearn2 是一个机器学习库。它的大多数功能都是构建于Theano 之上的。这意味着你可以利用数学表达式自己写 Pylearn2 插件(新模型,算法等等),Theano 会为你优化这些表达式使其更加稳定,你还可以选择将其编译到后端(CPU 或 GPU)。
提交数: 7100, 贡献者: 115, Github 链接: Pylearn2(http://github.com/lisa-lab/pylearn2)
7. Statsmodels 是一个 Python 模块,可以用来探索数据,估计统计模型,进行统计测试。对于不同类型的数据和模型估计,都有描述性统计,统计测试,绘图功能和结果统计的详细列表可用。
提交数: 8664, 贡献者: 108, Github 链接: Statsmodels(https://github.com/statsmodels/statsmodels/)
8. Shogun 是一个机器学习工具箱,它提供了很多统一高效的机器学习方法。这个工具箱允许多个数据表达,算法类和通用工具无缝组合。
提交数: 15172 贡献者: 105, Github 链接: Shogun(https://github.com/shogun-toolbox/shogun)
9. Chainer 是一个基于 Python 的独立的深度学习模型开源框架。Chainer 提供了灵活、直观且高性能的方法实现全方位的深度学习模型,包括循环神经网络 (recurrent neural networks) 和变分自编码器(variational autoencoders)这些最新的模型 。
提交数: 6298, 贡献者: 84, Github 链接: Chainer(https://github.com/pfnet/chainer)
10. NuPIC 是一个基于 HTM 算法 (Hierarchical Temporal Memory) 的开源项目。HTM 的一部分已经通过实践、测试和应用,另一部分仍在开发之中。
提交数: 6088, 贡献者: 76, Github 链接: NuPIC(http://github.com/numenta/nupic)
11. Neon 是 Nervana 公司一个基于 Python 的深度学习库。它易于使用且具有超高的性能。
提交数: 875, 贡献者: 47, Github 链接: Neon(https://github.com/NervanaSystems/neon)
12. Nilearn 是一个 Python 模块,用于在神经成像 (NeuroImaging) 数据上进行快速简单的统计学习。它利用 scikit-learn Python 工具箱来处理多变量统计信息,包括预测建模,分类,解码或连接分析.
提交数: 5254, 贡献者: 46, Github 链接: Nilearn(http://github.com/nilearn/nilearn)
13. Orange3 是一个同时适用于新手和数据专家的机器学习和数据可视化开源软件,支持拥有大型工具箱的交互式数据分析工作流程。
提交数: 6356, 贡献者: 40, Github 链接: Orange3(https://github.com/biolab/orange3)
14. Pymc 是一个Python 模块,它能实现贝叶斯统计模型和拟合算法,包括马尔科夫链蒙特卡罗(Markov chain Monte Carlo)算法。它非常灵活,具有可扩展性,适用于处理一系列大规模问题。
提交数: 2701, 贡献者: 37, Github 链接: Pymc(https://github.com/pymc-devs/pymc)
15. PyBrain 是一个模块化的 Python 机器学习库。它致力于为机器学习任务提供灵活易上手但功能强大的算法,和一系列用于测试和比较算法的预定义环境。
提交数: 984, 贡献者: 31, Github 链接: PyBrain(http://github.com/pybrain/pybrain)
16. Fuel 是一个数据管道框架(data pipeline framework),它为机器学习模型提供所需的数据。Blocks 和 Pylearn2 这两个神经网络库都有计划使用 Fuel。
提交数: 1053, 贡献者: 29, Github 链接: Fuel(http://github.com/mila-udem/fuel)
17.PyMVPA 是一个 Python 包,旨在简化大型数据集的统计学习分析。它提供了一个可扩展的框架和一个用于分类,回归,特征选择,数据导入导出等算法的高级接口。
提交数: 9258, 贡献者: 26, Github 链接: PyMVPA(https://github.com/PyMVPA/PyMVPA)
18. Annoy (Approximate Nearest Neighbors Oh Yeah)是一个带有 Python 绑定的 C++ 库,用于在空间中找到和已知的查询点临近的点。它还可以创建大型的基于文件的只读数据结构,并映射至内存,以便多个进程能共同使用相同的数据。
提交数: 365, Contributors: 24, Github 链接: Annoy(https://github.com/spotify/annoy)
19. Deap 是一个创新的,仍在发展中的计算框架,用于快速构建原型和测试方法。它旨在使算法和数据结构更加清晰透明。它与并行机制(如多进程和 SCOOP 模块)完美协调。
提交数: 1854, 贡献者: 21, Github 链接: Deap(https://github.com/deap/deap)
20. Pattern 是一个 Python 的网络挖掘模块。它绑定了数据挖掘(Google + Twitter + Wikipedia API, 网络爬虫, HTML DOM 解析器),自然语言处理 (词性标记, n-gram 搜索, 语义分析, WordNet),机器学习(向量空间模型, k-means 聚类, Naive Bayes + k-NN + SVM 分类器) 和网络分析(图核心性 graph centrality 和可视化)等工具。
提交数: : 943, Contributors: 20 , Github 链接: Pattern(http://github.com/clips/pattern)
在下面的图表中,可以看到 PyMVPA 相较于其他项目拥有最高的贡献率(contribution rate)。令人吃惊的是,Scikit-learn 虽然拥有最多的贡献者,但是贡献率却很低。这种现象背后的原因可能是:PyMVPA 是新项目,正处于开发的早期阶段,新功能开发,漏洞修补和重构等都能够引导更多的提交。而 Scikit-learn 属于比较旧且非常稳定的项目,改进和修复的空间更小。

在比较同时上榜 2015 和 2016 Top 20 的项目时,可以发现,Pattern,PyBrain 和 Pylearn2 没有新的贡献者(contributors)也没有新的贡献代码。同时,还可以发现贡献者数和提交数之间有显著关联。贡献者数的增长可能会导致提交数的增长,我认为这是开源项目和社区的魔力——引领头脑风暴,激发更多创意,开发更好的软件工具。
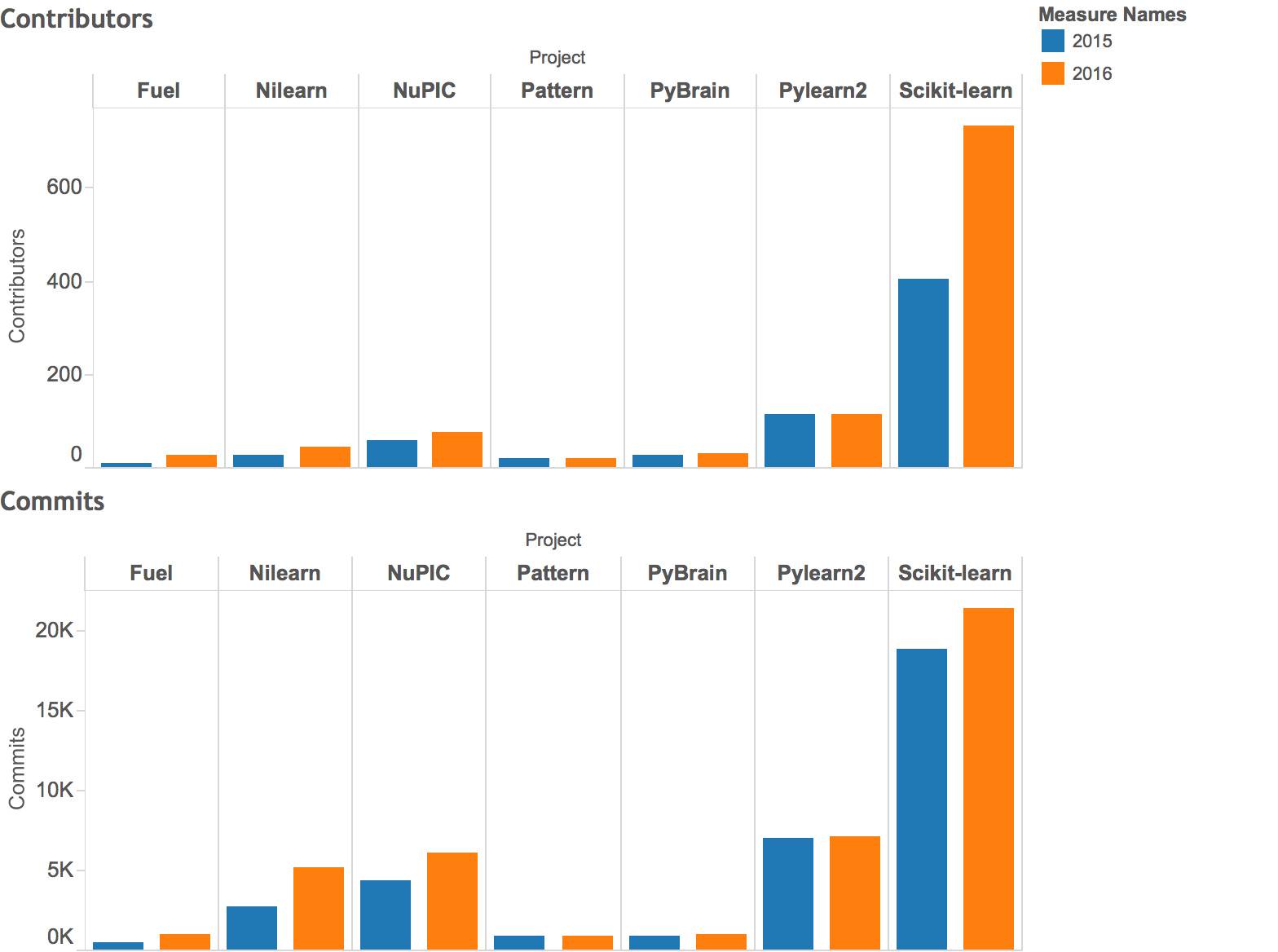
以上是对 2016 Python 机器学习开源项目所做的分析,该分析基于项目贡献者和提交数,作者是 KDnuggets 团队的 Prasad 和 Gregory。
- 机器学习 Python 库 Top 20
- 机器学习 Python 库 Top 20
- 机器学习 Python 库 Top 20
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python 机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- Python机器学习库
- mysql中union的用法
- Win32 SDK 学习笔记4
- svn: E220000: Not authorized to open root of edit operation
- cas 入门之十三:ticket 存储方案之简介
- python3使用pillow库为图片添加滤镜
- 机器学习 Python 库 Top 20
- driver: Linux设备模型之input子系统详解
- Caffe示例程序测试mnist数据集
- MySQL优化细节分析
- 【codevs1034】星际转移问题(家园)(网络流)
- IntelliJ IDEA和JBOSS配置及部署
- Interesting Calculator (最短路,广搜+优先队列,dp)(简单题)
- FileInputStream
- GPU共享内存问题


