腾讯面试题
来源:互联网 发布:java 浏览器输入框 编辑:程序博客网 时间:2024/06/07 22:42
1. STL中的内存管理机制
STL的每一个容器都已经指定了缺省的空间配置器为alloc。下面来分析一下这个缺省的空间配置器。
alloc空间分配的策略:
考虑到小型区块可能造成的内存的碎片的问题,SGI设计了双层的配置器,第一层的配置器直接使用的是malloc()和free(),第二层配置器则视情况采用不同的策略。当配置区块超过128字节(Bytes)的时候,视为足够大,调用第一级的配置器;当相应的配置区块小于128bytes时视为过小,为了减少内存碎片,采用相应的Memory pool(内存池)的方式。
memory pool的管理方式:
(1)free-list:一个类似单链表结构的数据结构,链表中的每一个小的区块都是没有正在被用户使用的(正在使用的将会断开和free-list的连接)。
(A)当用户向系统提出使用的需求(M个区块的内存)的时候,系统从free-list中未被使用的区块的得到M个区块的内存,交给用户,并将其断开和区块的连接;
(B)当用户向系统归还(N个区块的内存)的时候,系统将这N个区块连接到相应的free-list上。
(2)为了管理上的方便,SGI第二层配置器会主动的将任何的小额的区块的内存需求上调为8的倍数并维护16个free-lists,各自管理大小分别8,16,24,32,40,48,56,64,72,80,88,96,104,112,120,128bytes的小额区块。
2. TCP协议中的三次握手和四次挥手(图解)
建立TCP需要三次握手才能建立,而断开连接则需要四次握手。整个过程如下图所示:
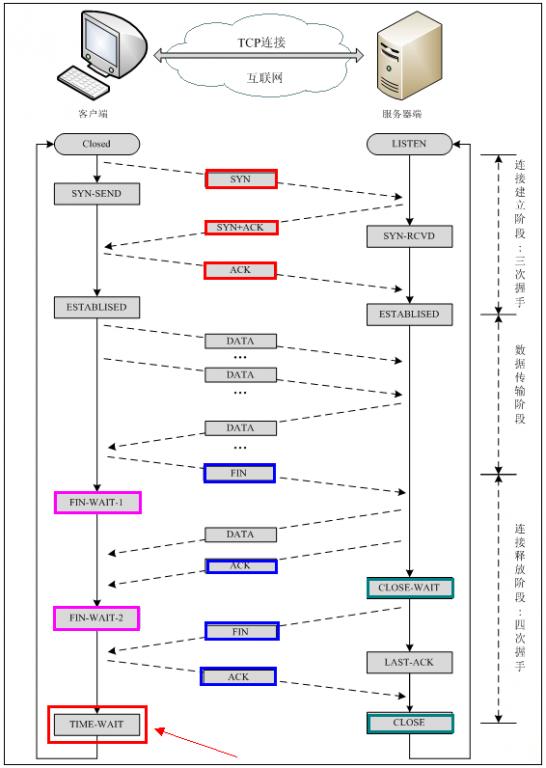
先来看看如何建立连接的。
【更新于2017.01.04 】该部分内容配图有误,请大家见谅,正确的配图如下,错误配图也不删了,大家可以比较下,对比理解效果更好。这么久才来更新,抱歉!!

错误配图如下:

首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。
那如何断开连接呢?简单的过程如下:
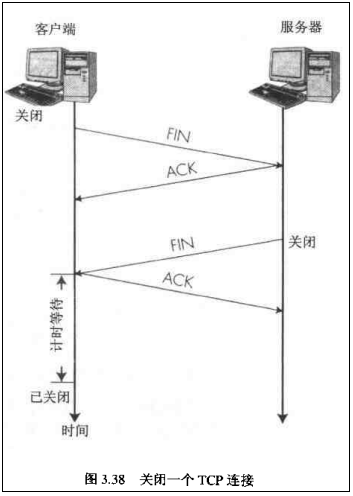
【注意】中断连接端可以是Client端,也可以是Server端。
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"告诉Client端,好了,我这边数据发完了,准备好关闭连接了"。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,"就知道可以断开连接了"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
整个过程Client端所经历的状态如下:
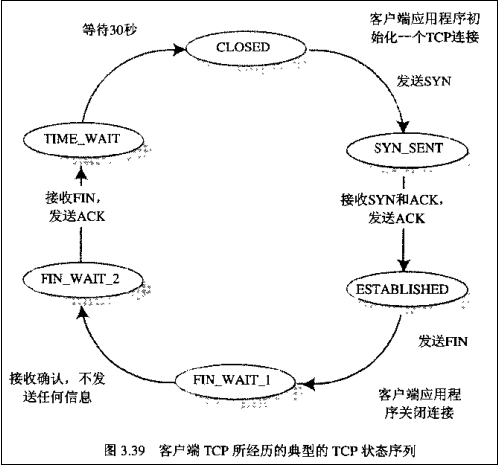
而Server端所经历的过程如下:转载请注明:blog.csdn.net/whuslei

【注意】 在TIME_WAIT状态中,如果TCP client端最后一次发送的ACK丢失了,它将重新发送。TIME_WAIT状态中所需要的时间是依赖于实现方法的。典型的值为30秒、1分钟和2分钟。等待之后连接正式关闭,并且所有的资源(包括端口号)都被释放。
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
3.TCP与UDP的区别TCP和UDP是OSI模型中的运输层中的协议。TCP提供可靠的通信传输,而UDP则常被用于让广播和细节控制交给应用的通信传输。
UDP(User Datagram Protocol)
UDP不提供复杂的控制机制,利用IP提供面向无连接的通信服务。并且它是将应用程序发来的数据在收到的那一刻,立刻按照原样发送到网络上的一种机制。
即使是出现网络拥堵的情况下,UDP也无法进行流量控制等避免网络拥塞的行为。此外,传输途中如果出现了丢包,UDO也不负责重发。甚至当出现包的到达顺序乱掉时也没有纠正的功能。如果需要这些细节控制,那么不得不交给由采用UDO的应用程序去处理。换句话说,UDP将部分控制转移到应用程序去处理,自己却只提供作为传输层协议的最基本功能。UDP有点类似于用户说什么听什么的机制,但是需要用户充分考虑好上层协议类型并制作相应的应用程序。
TCP(Transmission Control Protocol)
TCP充分实现爱呢了数据传输时各种控制功能,可以进行丢包的重发控制,还可以对次序乱掉的分包进行顺序控制。而这些在UDP中都没有。此外,TCP作为一种面向有连接的协议,只有在确认通信对端存在时才会发送数据,从而可以控制通信流量的浪费。
TCP通过检验和、序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输。此处不一一叙述。
TCP与UDP如何加以区分使用?
TCP用于在传输层有必要实现可靠性传输的情况。由于它是面向有连接并具备顺序控制、重发控制等机制的。所以它可以为应用提供可靠传输。
另一方面,UDP主要用于那些对高速传输和实时性有较高要求的通信或广播通信。举一个IP电话进行通话的例子。如果使用TCP,数据在传送途中如果丢失会被重发,但是这样无法流畅地传输通话人的声音,会导致无法进行正常交流。而采用UDP,它不会进行重发处理。从而也就不会有声音大幅度延迟到达的问题。即使有部分数据丢失,也只是影响某一小部分的通话。此外,在多播与广播通信中也使用UDP而不是TCP。RIP、DHCP等基于广播的协议也要依赖于UDP。
TCP与UDP区别总结:
1)、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2)、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3)、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4)、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5)、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6)、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
4、 Linux进程间通信方式简介
Linux下的进程通信手段基本上是从Unix平台上的进程通信手段继承而来的。而对Unix发展做出重大贡献的两大主力AT&T的贝尔实验室及BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。前者对Unix早期的进程间通信手段进行了系统的改进和扩充,形成了“system V IPC”,通信进程局限在单个计算机内;后者则跳过了该限制,形成了基于套接口(socket)的进程间通信机制。Linux则把两者继承了下来,如图示:

其中,最初Unix IPC包括:管道、FIFO、信号;System V IPC包括:System V消息队列、System V信号灯、System V共享内存区;Posix IPC包括: Posix消息队列、Posix信号灯、Posix共享内存区。有两点需要简单说明一下:1)由于Unix版本的多样性,电子电气工程协会(IEEE)开发了一个独立的Unix标准,这个新的ANSI Unix标准被称为计算机环境的可移植性操作系统界面(PSOIX)。现有大部分Unix和流行版本都是遵循POSIX标准的,而Linux从一开始就遵循POSIX标准;2)BSD并不是没有涉足单机内的进程间通信(socket本身就可以用于单机内的进程间通信)。事实上,很多Unix版本的单机IPC留有BSD的痕迹,如4.4BSD支持的匿名内存映射、4.3+BSD对可靠信号语义的实现等等。
图一给出了linux 所支持的各种IPC手段,在本文接下来的讨论中,为了避免概念上的混淆,在尽可能少提及Unix的各个版本的情况下,所有问题的讨论最终都会归结到Linux环境下的进程间通信上来。并且,对于Linux所支持通信手段的不同实现版本(如对于共享内存来说,有Posix共享内存区以及System V共享内存区两个实现版本),将主要介绍Posix API。
linux下进程间通信的几种主要手段简介:
- 管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
- 信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
- 报文(Message)队列(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
- 信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
- 套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
下面将对上述通信机制做具体阐述。
附1:参考文献[2]中对linux环境下的进程进行了概括说明:
一般来说,linux下的进程包含以下几个关键要素:
- 有一段可执行程序;
- 有专用的系统堆栈空间;
- 内核中有它的控制块(进程控制块),描述进程所占用的资源,这样,进程才能接受内核的调度;
- 具有独立的存储空间
进程和线程有时候并不完全区分,而往往根据上下文理解其含义。
5、Session和Cookie的区别和联系cookie机制:
Cookies是服务器在本地机器上存储的小段文本并随每一个请求发送至同一个服务器。IETF RFC 2965 HTTP State Management Mechanism 是通用cookie规范。网络服务器用HTTP头向客户端发送cookies,在客户终端,浏览器解析这些cookies并将它们保存为一个本地文件,它会自动将同一服务器的任何请求缚上这些cookies 。
具体来说cookie机制采用的是在客户端保持状态的方案。它是在用户端的会话状态的存贮机制,他需要用户打开客户端的cookie支持。cookie的作用就是为了解决HTTP协议无状态的缺陷所作的努力。
正统的cookie分发是通过扩展HTTP协议来实现的,服务器通过在HTTP的响应头中加上一行特殊的指示以提示浏览器按照指示生成相应的cookie。然而纯粹的客户端脚本如JavaScript也可以生成cookie。而cookie的使用是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器。
cookie的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成cookie的作用范围。若不设置过期时间,则表示这个cookie的生命期为浏览器会话期间,关闭浏览器窗口,cookie就消失。这种生命期为浏览器会话期的cookie被称为会话cookie。会话cookie一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。若设置了过期时间,浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie仍然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存里的cookie,不同的浏览器有不同的处理方式。
session机制:
session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个客户端的请求创建一个session时,服务器首先检查这个客户端的请求里是否已包含了一个session标识(称为session id),如果已包含则说明以前已经为此客户端创建过session,服务器就按照session id把这个session检索出来使用(检索不到,会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存。
1).存取方式的不同
Cookie中只能保管ASCII字符串,假如需求存取Unicode字符或者二进制数据,需求先进行编码。Cookie中也不能直接存取Java对象。若要存储略微复杂的信息,运用Cookie是比拟艰难的。
而Session中能够存取任何类型的数据,包括而不限于String、Integer、List、Map等。Session中也能够直接保管Java Bean乃至任何Java类,对象等,运用起来十分便当。能够把Session看做是一个Java容器类。
2 ).隐私策略的不同
Cookie存储在客户端阅读器中,对客户端是可见的,客户端的一些程序可能会窥探、复制以至修正Cookie中的内容。而Session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。
假如选用Cookie,比较好的方法是,敏感的信息如账号密码等尽量不要写到Cookie中。最好是像Google、Baidu那样将Cookie信息加密,提交到服务器后再进行解密,保证Cookie中的信息只要本人能读得懂。而假如选择Session就省事多了,反正是放在服务器上,Session里任何隐私都能够有效的保护。
3).有效期上的不同
使用过Google的人都晓得,假如登录过Google,则Google的登录信息长期有效。用户不用每次访问都重新登录,Google会持久地记载该用户的登录信息。要到达这种效果,运用Cookie会是比较好的选择。只需要设置Cookie的过期时间属性为一个很大很大的数字。
由于Session依赖于名为JSESSIONID的Cookie,而Cookie JSESSIONID的过期时间默许为–1,只需关闭了阅读器该Session就会失效,因而Session不能完成信息永世有效的效果。运用URL地址重写也不能完成。而且假如设置Session的超时时间过长,服务器累计的Session就会越多,越容易招致内存溢出。
4).服务器压力的不同
Session是保管在服务器端的,每个用户都会产生一个Session。假如并发访问的用户十分多,会产生十分多的Session,耗费大量的内存。因而像Google、Baidu、Sina这样并发访问量极高的网站,是不太可能运用Session来追踪客户会话的。
而Cookie保管在客户端,不占用服务器资源。假如并发阅读的用户十分多,Cookie是很好的选择。关于Google、Baidu、Sina来说,Cookie或许是唯一的选择。
5 ).浏览器支持的不同
Cookie是需要客户端浏览器支持的。假如客户端禁用了Cookie,或者不支持Cookie,则会话跟踪会失效。关于WAP上的应用,常规的Cookie就派不上用场了。
假如客户端浏览器不支持Cookie,需要运用Session以及URL地址重写。需要注意的是一切的用到Session程序的URL都要进行URL地址重写,否则Session会话跟踪还会失效。关于WAP应用来说,Session+URL地址重写或许是它唯一的选择。
假如客户端支持Cookie,则Cookie既能够设为本浏览器窗口以及子窗口内有效(把过期时间设为–1),也能够设为一切阅读器窗口内有效(把过期时间设为某个大于0的整数)。但Session只能在本阅读器窗口以及其子窗口内有效。假如两个浏览器窗口互不相干,它们将运用两个不同的Session。(IE8下不同窗口Session相干)
6).跨域支持上的不同
Cookie支持跨域名访问,例如将domain属性设置为“.biaodianfu.com”,则以“.biaodianfu.com”为后缀的一切域名均能够访问该Cookie。跨域名Cookie如今被普遍用在网络中,例如Google、Baidu、Sina等。而Session则不会支持跨域名访问。Session仅在他所在的域名内有效。
仅运用Cookie或者仅运用Session可能完成不了理想的效果。这时应该尝试一下同时运用Cookie与Session。Cookie与Session的搭配运用在实践项目中会完成很多意想不到的效果。
6.数据库事务的四大特征
(1) 原子性(Atomicity)
事务的原子性指的是,事务中包含的程序作为数据库的逻辑工作单位,它所做的对数据修改操作要么全部执行,要么完全不执行。这种特性称为原子性。
例如银行取款事务分为2个步骤(1)存折减款(2)提取现金。不可能存折减款,却没有提取现金。2个步骤必须同时完成或者都不完成。
(2)一致性(Consistency)
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。这种特性称为事务的一致性。假如数据库的状态满足所有的完整性约束,就说该数据库是一致的。
例如完整性约束a+b=10,一个事务改变了a,那么b也应随之改变。
(3)分离性(亦称独立性Isolation)
分离性指并发的事务是相互隔离的。即一个事务内部的操作及正在操作的数据必须封锁起来,不被其它企图进行修改的事务看到。假如并发交叉执行的事务没有任何控制,操纵相同的共享对象的多个并发事务的执行可能引起异常情况。
(4)持久性(Durability)
持久性意味着当系统或介质发生故障时,确保已提交事务的更新不能丢失。即一旦一个事务提交,DBMS保证它对数据库中数据的改变应该是永久性的,即对已提交事务的更新能恢复。持久性通过数据库备份和恢复来保证。
7.数据库索引
顺序索引,B+树索引,hash索引,也就是散列索引等;
由于B+tree的性质, 它通常被用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引,因为B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度(B+ 树元素自底向上插入)。
索引的实现通常使用B树及其变种B+树。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
唯一索引 :
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
主键索引:
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引:
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
1)B树
B树中每个节点包含了键值和键值对应的数据对象存放地址指针,所以成功搜索一个对象可以不用到达树的叶节点。
成功搜索包括节点内搜索和沿某一路径的搜索,成功搜索时间取决于关键码所在的层次以及节点内关键码的数量。
在B树中查找给定关键字的方法是:首先把根结点取来,在根结点所包含的关键字K1,…,kj查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查的关键字在某个Ki或Ki+1之间,于是取Pi所指的下一层索引节点块继续查找,直到找到,或指针Pi为空时查找失败。
2)B+树
B+树非叶节点中存放的关键码并不指示数据对象的地址指针,非叶节点只是索引部分。所有的叶节点在同一层上,包含了全部关键码和相应数据对象的存放地址指针,且叶节点按关键码从小到大顺序链接。如果实际数据对象按加入的顺序存储而不是按关键码次数存储的话,叶节点的索引必须是稠密索引,若实际数据存储按关键码次序存放的话,叶节点索引时稀疏索引。
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
所以 B+树有两种搜索方法:
一种是按叶节点自己拉起的链表顺序搜索。
一种是从根节点开始搜索,和B树类似,不过如果非叶节点的关键码等于给定值,搜索并不停止,而是继续沿右指针,一直查到叶节点上的关键码。所以无论搜索是否成功,都将走完树的所有层。
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
这两种处理索引的数据结构的不同之处:
a,B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中。而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡。
b,因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,但使得在插入、删除操作复杂度明显增加。B+树相比来说是一种较好的折中。
c,B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),最小时间复杂度为1(在根结点的时候)。而B+树的时候复杂度对某建成的树是固定的。
8.HTTP返回码总结
HTTP协议状态码表示的意思主要分为五类 ,大体是 :
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1×× 保留
2×× 表示请求成功地接收
3×× 为完成请求客户需进一步细化请求
4×× 客户错误
5×× 服务器错误
100 Continue
指示客户端应该继续请求。回送用于通知客户端此次请求已经收到,并且没有被服务器拒绝。
客户端应该继续发送剩下的请求数据或者请求已经完成,或者忽略回送数据。服务器必须发送
最后的回送在请求之后。
101 Switching Protocols
服务器依照客服端请求,通过Upgrade头信息,改变当前连接的应用协议。服务器将根据Upgrade头立刻改变协议
在101回送以空行结束的时候。
Successful
=================================
200 OK
指示客服端的请求已经成功收到,解析,接受。
201 Created
请求已经完成并一个新的返回资源被创建。被创建的资源可能是一个URI资源,通常URI资源在Location头指定。回送应该包含一个实体数据
并且包含资源特性以及location通过用户或者用户代理来选择合适的方法。实体数据格式通过煤体类型来指定即content-type头。最开始服务 器
必须创建指定的资源在返回201状态码之前。如果行为没有被立刻执行,服务器应该返回202。
202 Accepted
请求已经被接受用来处理。但是处理并没有完成。请求可能或者根本没有遵照执行,因为处理实际执行过程中可能被拒绝。
203 Non-Authoritative Information
204 No Content
服务器已经接受请求并且没必要返回实体数据,可能需要返回更新信息。回送可能包含新的或更新信息由entity-headers呈现。
205 Reset Content
服务器已经接受请求并且用户代理应该重新设置文档视图。
206 Partial Content
服务器已经接受请求GET请求资源的部分。请求必须包含一个Range头信息以指示获取范围可能必须包含If-Range头信息以成立请求条件。
Redirection
==================================
300 Multiple Choices
请求资源符合任何一个呈现方式。
301 Moved Permanently
请求的资源已经被赋予一个新的URI。
302 Found
通过不同的URI请求资源的临时文件。
303 See Other
304 Not Modified
如果客服端已经完成一个有条件的请求并且请求是允许的,但是这个文档并没有改变,服务器应该返回304状态码。304
状态码一定不能包含信息主体,从而通常通过一个头字段后的第一个空行结束。
305 Use Proxy
请求的资源必须通过代理(由Location字段指定)来访问。Location资源给出了代理的URI。
306 Unused
307 Temporary Redirect
Client Error
=====================
400 Bad Request
因为错误的语法导致服务器无法理解请求信息。
401 Unauthorized
如果请求需要用户验证。回送应该包含一个WWW-Authenticate头字段用来指明请求资源的权限。
402 Payment Required
保留状态码
403 Forbidden
服务器接受请求,但是被拒绝处理。
404 Not Found
服务器已经找到任何匹配Request-URI的资源。
405 Menthod Not Allowed
Request-Line 请求的方法不被允许通过指定的URI。
406 Not Acceptable
407 Proxy Authentication Required
408 Reqeust Timeout
客服端没有提交任何请求在服务器等待处理时间内。
409 Conflict
410 Gone
411 Length Required
服务器拒绝接受请求在没有定义Content-Length字段的情况下。
412 Precondition Failed
413 Request Entity Too Large
服务器拒绝处理请求因为请求数据超过服务器能够处理的范围。服务器可能关闭当前连接来阻止客服端继续请求。
414 Request-URI Too Long
服务器拒绝服务当前请求因为URI的长度超过了服务器的解析范围。
415 Unsupported Media Type
服务器拒绝服务当前请求因为请求数据格式并不被请求的资源支持。
416 Request Range Not Satisfialbe
417 Expectation Failed
Server Error
===================================
500 Internal Server Error
服务器遭遇异常阻止了当前请求的执行
501 Not Implemented
服务器没有相应的执行动作来完成当前请求。
502 Bad Gateway
503 Service Unavailable
因为临时文件超载导致服务器不能处理当前请求。
504 Gateway Timeout
505 Http Version Not Supported
- 腾讯面试题
- 腾讯笔试面试题
- 腾讯面试题
- 腾讯面试题
- 腾讯经典面试题
- 腾讯面试题
- 腾讯面试题
- 腾讯面试题PHP
- 腾讯PHP面试题
- 腾讯面试题解答
- 腾讯 百度 面试题
- 腾讯iphone面试题
- 腾讯面试题
- 一道腾讯面试题
- 腾讯等面试题
- 腾讯面一个试题
- 腾讯面试题
- 腾讯2011面试题
- 终于等到你——基于深度学习的应用创新
- 聊天室服务器基本代码分享
- 输入字符串反转
- 【2017/4/10】Oracle 11g修改MEMORY_TARGET
- 如何判断文件是否读到文件结尾
- 腾讯面试题
- C++批量生成大规模随机数中种子值设置的总结——解决随机数序列重复问题
- 栈、堆、方法区、本地方法区、寄存器
- Android蓝牙通信
- VS2010/MFC 配置Halcon12 并显示图片
- QT入门
- Server responded "Algorithm negotiation failed"【SSH Secure链接服务器错误】
- Java.SE01.多线程_案例01
- 良好的微服务架构能够取代企业服务总线吗?


