DBA的内容挺多啊【转帖】
来源:互联网 发布:手机映射软件下载 编辑:程序博客网 时间:2024/06/10 21:00
DBA Online记录数据库管理过程中的点滴,收集数据库管理相关的技术文档!
超级好用的一键式自动解决黑屏问题的工具
先收藏起来,以备不时之需!来自360,没验证!
你被黑屏了么?为了方便那些使用盗版操作系统的朋友,如果你的系统被黑屏了,如果你不懂得如何关闭windows自动更新,我给你推荐一个超级好用的一键式自动解决黑屏问题的工具,超级好用!这个工具是由安全专家认证的哟
绝对安全无病毒,请放心下载。强烈要求版主设精置顶,各位觉得好的挺一下啊
下载地址:http://baike.360.cn/index.php?c=attach&a=down&id=ad35b083c451.rar
从PowerDesigner概念设计模型(CDM)中的3种实体关系说起
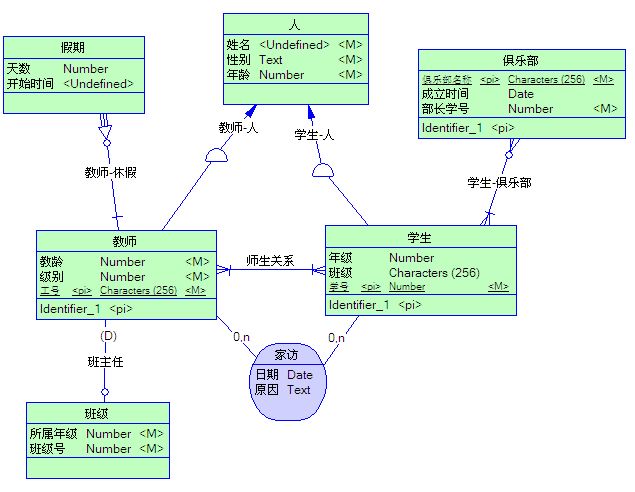
另外,在介绍所有这些CDM中的元素之前,笔者先给出一个很简单的CDM图,是对我们最最熟悉的学校场景的一个建模,下文中提到的所有概念在图中都有体现,大家在看下文的时候可以对照着来看:
一. RelationShip(联系)
先给出PD手册里对联系的定义:“A relationship is a link between entities. For example, in a CDM that manages human resources, the relationship Member links the entities Employee and Team, because employees can be members of teams. This relationship expresses that each employee works in a team and that each team has employees.” 可见,也许联系的概念真的太简单了吧,所以反而不那么好表述,所以PD的文档里也是用一个例子来说明出现了什么样的情况我们就认为两个实体间是有联系的。
当我们提起实体间联系的时候,最先想到的恐怕是one to one,one to many 和many to many这三种联系类型,这些联系类型也是大家最熟悉的。笔者对ER图原本的概念并不精通,但在CDM中,联系还有另外三个可以设置的属性:mandatory(强制性联系), dependent(依赖性联系/标定关联) 和dominant(统制联系)。这些属性对后面PDM的生成都有比较大的影响,需要我们一一有所了解。它们都是在联系的属性控制面板中设定的,见下图: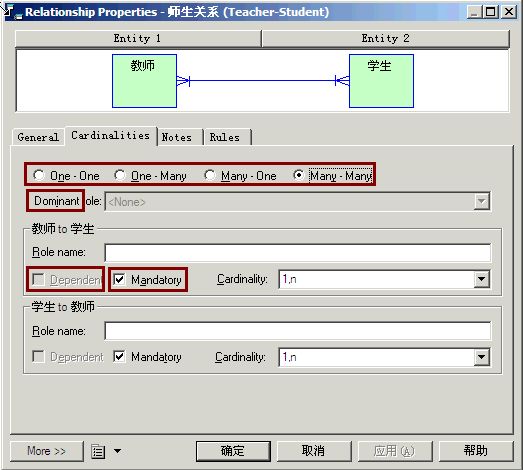
1.mandatory
联系是否具有强制性,指的是实体间是不是一定会出现这种联系;或者换句话说,当我们在谈及一个联系的应用场景的时候,联系对应的那两个实体型的实体实例的个数可不可能为零。也许这样的解释还是有点抽象,让我们举两个联系的例子,一个是对两边的实体都有强制性的,另一个则不然。
(1)教师–学生 联系
这个联系首先是一个多对多联系,因为每个老师可以教多个学生,每个学生也都有多个老师来负责他们的学业。同时,这个联系对教师和学生都是强制性的,也就是说,不存在任何一个老师,他不负责任何一个学生的教学;也不存在任何一个学生,他没有任何一个任课老师。
(2)学生–俱乐部 联系
这个联系也是一个多对多关系,但它对学生这个实体型而言就不是强制的(Optional,可选的)。每个俱乐部都有至少一个学生参加,但并不是每个学生都要去参加俱乐部的活动。完全可以有一些学生,他们什么俱乐部都没参加。
上面的例子主要是从概念的角度来区分了mandatory和optional的区别。实际上如果把这个模型对应到我们最后生成的表,如果A-B间的联系对A是mandatory的话,那么如果在A里面如果包含B的外键,这个外键不能为空值,反之可以为空值。后面我们谈到PDM和实际数据库的时候,大家会看到这一点。
2.dependent
每一个Entity型都有自己的Identifier,如果两个Entity型之间发生关联时,其中一个Entity型的Identifier进入另一个Entity型并与该 Entity型中的Identifier共同组成其Identifier时,这种关联称为标定关联,也叫依赖性关联(dependent relationship)。一个Entity型的Identifier进入另一个Entity型后充当其非Identifier时,这种关联称为非标定关联,也叫非依赖关联。
概念的定义说起来还是有些拗口,说白了其实就是主-从表关系,从表要依赖于主表。比如在我们系统里要记录教师休假的情况,有一个实体型Holiday,其属性包括休假的开始时间和天数,每次有教师休假的时候,都要在这个表留下记录。从我们的场景描述中可以看到,实体型假期必须依附于实体型教师,即对于每一个假期实例,必须指向某一个教师实例。
对于依赖型联系,必须注意它不可能是一个多对多联系,在这个联系中,必须有一个作为主体的实体型。一个dependent联系的从实体可以没有自己的identifier.
3.dominant
这个联系属性是最为简单的,它仅作用于一对一联系,并指明这种联系中的主从表关系。在A,B两个实体型的联系中,如果A–>B被指定为dominant,那么A为这个一对一联系的主表,B为从表,并且在以后生成的PDM中会产生一个引用(如果不指定dominant属性的话会产生两个引用)。比如老师和班级之间的联系,因为每个班级都有一个老师做班主任,每个老师也最多只能做一个班级的班主任,所以是一个一对一关系。同时,我们可以将老师作为主表,用老师的工号来唯一确定一个班主任联系。
二.Association(关联)
先来看一下PD给association的定义:“An association is a connection between entities. In the Merise modeling methodology an association is used to connect several entities that each represents clearly defined objects, but are linked by an event, which may not be so clearly represented by another entity.”。
在上一小段提到的那些RelationShip,在很多情况下(特别是多对多关系中),我们会把联系专门提出来,作为一个实体型放在两个需要被关联的实体型中间(在PD中,选中任何一个联系,在右键的弹出菜单中选择“Change to Entity”命令即可完成联系转实体的操作)。但有的时候,把若干个实体型之间的联系抽象为一个实体型可能不太合适,这个时候你可以选择为这些实体型建立一个association,那么在生成PDM的时候,所有这些相关实体型的identifier都会被加入到association对应生成的表模型中。所以,说白了,其实association就是实体型的一种特例,用来在建模的时候更确切的表达实体间的关联信息。在PD的文档中举了一个录音带、顾客、商店三个实体型在租借录音带这个场景上发生关联,然后把租借定义为上述三个实体型之间的association的例子,非常确切。在我们的学校模型里,我定义了家访做为老师和学生实体型中间的一个association,在接下来产生的PDM中大家就可能看到这种定义所产生的效果。
三.Inheritance(继承)
这种关系在概念层面是最容易理解的了,本文就不赘述了。
前面已经介绍了CDM中关于实体间关系的主要内容,接下来我们就来看看根据这个CDM所生成的PDM是一个什么样子:
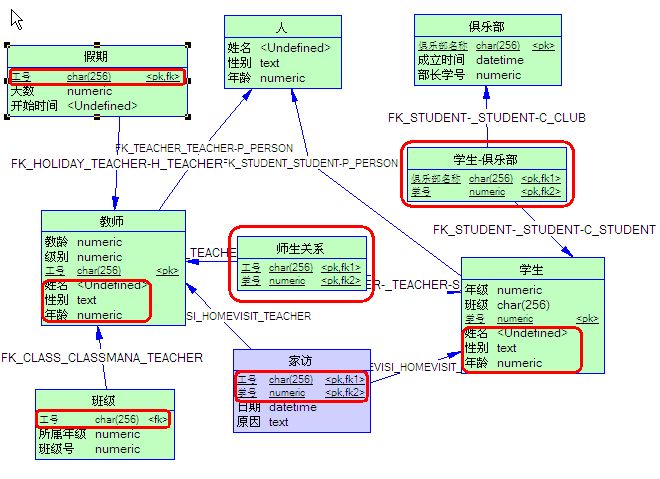
上图中所有标红的部分是我们最应该关注的内容,因为他们都是由于我们对实体型间的关系的定义而产生的,下面给出一些简单的说明。
1. “师生关系”和“学生俱乐部”这两个表是由于我们的多对多关系而产生的。
2. “假期”表的“工号”字段是由于我们将教师-假期关系指定为dependent而产生的。
3. “班级”表的“工号”字段是由于我们将教师-班级关系制定为dominant而产生的。
4. “家访”表中的“工号”和“学号”字段是由于家访是教师和学生实体型的association而产生的。
另外,记得我们在提到dominant属性的时候说过,一个没指定dominant方向的一对一联系将产生两个引用,下面我们就把原本的CDM中的教师-班级关系进行一个小小的修改,去掉这个relationship的dominant定义,那么最终产生的PDM中教师表和班级表将互相包含对方的主键(由于我们的班级表没有自己的主键,所以只能在班级表中看到多出来的列),截图如下:
对照这个PDM截图和上一个PDM截图之间的区别,大家可以很容易得看出dominant属性对一个一对一关系的作用。
百度做事怎么这么粗心呢?
最近百度C2C平台有啊搞得如火如荼,大有和淘宝一决高下的势头。
本人对有啊并不感冒,持观望态度!当然本人也未在网上开店,就是对百度没什么好感。
今天一如既往的打开news.baidu.com看新闻,说百度的有啊平台开始测试,遂跟了过去看过究竟。
却发现了这么大的别字:
欢迎抢先体验百度有啊beta版,与我们共同开启网购时代的新篇章!
请使用您受到邀请的百度账号登录
精彩稍后继续..
有图为证:

null
通过数据字典视图查询锁的信息
Oracle将当前的锁的信息存储在动态性能视图v$lock和v$locked_object中,并通过catblock.sql脚本创建了查询这些视图的dba_locks视图;通过dbmslock.sql脚本创建了分配锁名称、申请一个模式的锁、将锁从一个模式转换成另一个模式、释放锁的各个过程;通过utllockt.sql脚本提供了一种按树形图的格式显式等待锁的各个会话的查询方式。如表20.6所示,显式了与锁相关的各个视图。
表20.6 与锁相关的视图
视图 | 说明 |
所有由系统、由所有连接的会话所保持的锁的信息 | |
V$LOCKED_OBJECT | 所有会话锁定的对象以及使用的锁的模式 |
DBA_LOCKS | 所有会话保持或申请的锁的信息 |
DBA_WAITERS | 显示所有被阻塞会话及其申请的锁和阻塞该会话的会话保持的锁的信息 |
DBA_BLOCKERS | 显示阻塞了其他会话的那些会话,而不是正在等待锁的会话 |
下面在会话C中,由sys用户通过查询上面这些视图来了解锁,及其会话、被锁定的对象等信息。
20.3.1.1查询V$LOCK视图
V$LOCK视图的各个列,及其说明如表20.7所示。
表20.7 V$LOCK视图的各个列及其说明
列名 | 数据类型 | 说明 |
ADDR | RAW(4) | 在内存中锁定的对象的地址 |
KADDR | RAW(4) | 在内存中锁的地址 |
SID | NUMBER | 保持或申请锁的会话的标识号 |
TYPE | VARCHAR2(2) | 锁的类型。 TX=行锁或事务锁;TM=表锁或DML锁;UL=PL/SQL用户锁 |
ID1 | NUMBER | 锁的第1标识号。 如果锁的类型是TM,该值表示将要被锁定的对象的标识号; 如果锁的类型是TX,该值表示撤销段号码的十进制值 |
ID2 | NUMBER | 锁的第2标识号。 如果锁的类型是TM,该值为0; 如果锁的类型是TX,该值表示交换次数 |
LMODE | NUMBER | 会话保持的锁的模式。 0=None;1=Null;2=Row-S (SS);3=Row-X (SX); 4=Share;5=S/Row-X (SSX);6=Exclusive |
REQUEST | NUMBER | 会话申请的锁的模式。与LMODE中的模式相同 |
CTIME | NUMBER | 以秒为单位的,获得当前锁(或转换成当前锁的模式)以来的时间 |
BLOCK | NUMBER | 当前锁是否阻塞另一个锁。 0=不阻塞;1=阻塞 |
查询V$LOCK视图的一个例子如图20.19所示。

图20.19 查询V$LOCK视图
“交叉参考”TYPE列的简写所代表的详细内容,请参见后面的“查询DBA_LOCKS视图”中的LOCK_TYPE列中的对应内容。
20.3.1.2查询V$LOCKED_OBJECT视图
V$LOCKED_OBJECT视图的各个列,及其说明如表20.8所示。
表20.8 V$LOCKED_OBJECT视图的各个列及其说明
列名 | 数据类型 | 说明 |
XIDUSN | NUMBER | 撤销段号码 |
XIDSLOT | NUMBER | 被锁定的对象在撤销段中的位置 |
XIDSQN | NUMBER | 序列号 |
OBJECT_ID | NUMBER | 被锁定的对象的标识号 |
SESSION_ID | NUMBER | 会话的标识号 |
ORACLE_USERNAME | VARCHAR2(30) | Oracle用户名 |
OS_USER_NAME | VARCHAR2(30) | 操作系统用户名 |
PROCESS | VARCHAR2(12) | 操作系统进程标识号 |
LOCKED_MODE | NUMBER | 对象被锁定的模式。 0=None;1=Null;2=Row-S (SS);3=Row-X (SX); 4=Share;5=S/Row-X (SSX);6=Exclusive |
查询V$LOCKED_OBJECT视图的一个例子如图20.20所示。

图20.20 查询V$LOCKED_OBJECT视图
20.3.1.3查询DBA_LOCKS视图
DBA_LOCKS视图的各个列,及其说明如表20.9所示。
表20.9 DBA_LOCKS视图的各个列及其说明
列名 | 数据类型 | 说明 |
SESSION_ID | NUMBER | 保持或申请锁的会话的标识号 |
LOCK_TYPE | VARCHAR2(26) | 锁的类型 |
MODE_HELD | VARCHAR2(40) | 保持的锁的模式 |
MODE_REQUESTED | VARCHAR2(40) | 申请的锁的模式 |
LOCK_ID1 | VARCHAR2(40) | 锁的第1标识号 |
LOCK_ID2 | VARCHAR2(40) | 锁的第2标识号 |
LAST_CONVERT | NUMBER | 以秒为单位的,获得当前锁(或转换成当前锁的模式) 以来的时间 |
BLOCKING_OTHERS | VARCHAR2(40) | 当前锁是否阻塞另一个锁。 Not Blocking=不阻塞;Blocking=阻塞 |
查询DBA_LOCKS视图的一个例子如图20.21所示。
图20.21 查询DBA_LOCKS视图
20.3.1.4查询DBA_WAITERS视图
DBA_WAITERS视图的各个列,及其说明如表20.10所示。
表20.10 DBA_WAITERS视图的各个列及其说明
列名 | 数据类型 | 说明 |
WAITING_SESSION | NUMBER | 等待锁的会话(被阻塞的会话)的标识号 |
HOLDING_SESSION | NUMBER | 保持锁的会话(阻塞的会话)的标识号 |
LOCK_TYPE | VARCHAR2(26) | 锁的类型 |
MODE_HELD | VARCHAR2(40) | 保持的锁的模式 |
MODE_REQUESTED | VARCHAR2(40) | 申请的锁的模式 |
LOCK_ID1 | NUMBER | 锁的第1标识号 |
LOCK_ID2 | NUMBER | 锁的第2标识号 |
查询DBA_WAITERS视图的一个例子如图20.22所示。

图20.22 查询DBA_WAITERS视图
20.3.1.5查询DBA_BLOCKERS视图
DBA_BLOCKERS视图的各个列,及其说明如表20.11所示。
表20.11 DBA_BLOCKERS视图的各个列及其说明
列名 | 数据类型 | 说明 |
HOLDING_SESSION | NUMBER | 显示阻塞了其他会话的那些会话的标识号 |
查询DBA_BLOCKERS视图的一个例子如图20.23所示。

图20.23 查询DBA_BLOCKERS视图
表数据行数和每个表所占用的空间大小查询
刚到新单位上班,因此想了解一下现在数据库的一些情况。
首先是了解了硬件信息,然后表空间,数据文件,日志文件,归档情况等信息。
然后想进一步了解表里面的数据行数和每个表所占用的空间大小。
数据表数据行查询脚本
create table sa_table_count(
table_name varchar2(30),
rows_count number(10)
);
declare
v_tname varchar2(30);
v_count number(10);
cursor cur_tab is select tname from tab where tabtype=’TABLE’;
begin
open cur_tab;
loop
fetch cur_tab into v_tname;
exit when cur_tab%notfound;
execute immediate ’select count(*) count from ‘||v_tname into v_count;
insert into sa_table_count(table_name,rows_count) values(v_tname,v_count);
end loop;
close cur_tab;
commit;
end;
/
数据表占用空间大小查询脚本:
SELECT s.segment_name,
decode(SUM(BYTES), null, 0, SUM(BYTES) / 1024)
FROM DBA_SEGMENTS S, dba_tables t
where s.owner = ‘you segment owner’
and t.owner = ‘your table owner’
and s.segment_name = t.table_name
and s.blocks is not null
and s.blocks > 0
group by s.segment_name
having SUM(BYTES) > 0
其中有些表的大小为表初始大小,尽管数据行为0,也能包含在其中,因为之前的行被删除,高水位线没下来。
如果要快速计算表大概拥有的行数可以通过DBA_SEGMENTS 中的blocks汇总值和抽样的blocks中的平均行数的乘积来确定。
ORACLE中的等待事件
表:非空闲等待事件的级别含义
Buffer busy wait 表示在等待对数据告诉缓存区的访问,这种等待出现在会话读取数据到buffer中或者修改buffer中的数据时,例如DBWR正在写一些数据块到数据文件的同时,其他进程需要去读取相应的数据块。同时也可能表示在表上设置的freelist太小,不能支持大量并发的INSERT操作。在v$session_wait视图的p1子段值表示相关数据块所在的文件号,p2表示文件上的块编号。通过这些信息与dba_data_files和dba_extents的联合查询就可以很快定位到发生竞争的对象,从而近一步确定问题的根源。
Db file parrle write 于dbwr进程相关的等待,一般都代表了io能力出现问题。通常与配置的多个dbwr进程或者dbwr的io slaves个数有关,当然也可能意味这在设备上出现io竞争!
Db file scattered read 表示发生了于全表扫描的等待。通常意味者全表扫描过多,或者io能力不足,或者io竞争
Db file sequential read 表示发生了于索引扫描有关的等待。同样意味者io出现了问题,表示io出现了竞争和io需求太多
Db file single write 表示在检查点发生时与文件头写操作相关的等待。通常于检查点同步数据文件时文件号的紊乱有关
Direct path read 表示于直接io读相关的等待。当直接读数据到pga内存时,direct path read出现。这种类型的读请求典型的作为:排序io并行slave查询或者预先读请求等。通常这种等待于io能力或者io竞争有关
Direct path write 同上
Enqueue 表示于内部队列机制有关的等待,例如保护内部资源或者组件的锁的请求等,一种并发的保护机制
Free buffer inspected 表示在将数据读入数据告诉缓冲区的时候等待进程找到足够大的内存空间。通常这种等待表示数据缓冲区偏小。
Free buffer waits 表述数据告诉缓存区缺少内存空间。通常于数据高速缓冲区内存太小或者脏数据写出太慢导致。在这种情况下,可以考虑增大高速缓存区或者通过设置更多的dbwr来解决
Latch free 表示某个锁存器发生了竞争。首先应该确保已经提供了足够多的latch数,如果仍然发生这种等待事件,应该进一步确定是那种锁存器上发生了竞争(在v$session_wait上的p2子段表示了锁存器的标号),然后判断是什么引起了这种锁存器竞争。大多数锁存器竞争不是简单的锁存器引起的,而是于锁存器相关的组件引起的,需要找到具体导致竞争的根本。例如,如果发生了library cache latch竞争,那么通常表示库缓存配置不合理,或者sql语句书写不合理,带来了大量的硬分析。
Library cache load lock 表示在将对象装入到库高速缓冲区的时候出现了等待。这种事件通常代表者发生了负荷很重的语句重载或者装载,可能由于sql语句没有共享池区域偏小导致的。
Library cache lock 表示与访问库高速缓存的多个进程相关的等待。通常表示不合理的共享池大小。
Library cache pin 这个等待事件也与库高速缓存的并发性有关,当库高速缓存中的对象被修改或者被检测的时候发生
Log buffer space 表示日志缓冲区出现了空间等待事件。这种等待事件意味者写日志缓冲区的时候得不到相应的内存空间,通常发生在日志缓冲区太小或者LGWR进程写太慢的时候。
Log file parallel write 表示等待LGWR向操作系统请求io开始直到完成io。在触发LGWR写的情况下入3秒,1/3,1MB、DBWR写之前可能发生。这种事件发生通常表示日志文件发生了io竞争或者文件所在的驱动器较慢。
Log file single write 表示写文件头块的时候出现了等待。一般都是发生在检查点发生时。
Log file switch
(archiveing needed) 由于归档过慢造成日志无法进行切换而发生的等待。这种等待事件的原因可能比较多,最主要的原因是归档速度赶不上日志切换的速度。可能的原因包括了重作日志太了,重作日志组太少,归档能力低,归档文件发生了io竞争,归档日志挂起,或者归档日志放在了慢的设备上。
Log file switch
(checkpoint incomplete) 表示在日志切换的时候文件上的检查点还没有完成。一般意味者日志文件太小造成日志切换切换太快或者其他原因。
Log file sync 表示当服务进程发出commit或者rollbabk命令后,直到LGWR完成相关日志写操作这段时间的等待。如果有多个服务进程同时发出这种命令,LGWR不能及时完成日志的写操作,就有可能造成这种等待。
Transaction 表示发生一个阻赛回滚操作的等待
Undo segment extension 表示在等待回滚段的动态扩展。这表示可能事务量过大,同时也意味者可能回滚段的初始大小不是最优,minextents设置偏小。考虑减少事务,或者使用最小区数更多的回滚段。
数据库表结构设计方法及原则
Author: Chancey
在目前的企业信息系统中,数据库还是最佳的数据存储方式,虽然已经有很多的书籍在指导我们进行数据库设计,但应该那种方式是设计数据库的表结构的最好方法、设计时应遵从什么样的原则、四个范式如何能够用一种方式达到顺畅的应用等是我一直在思考和总结的问题,下文是我针对这几个问题根据自己的设计经历准备总结的一篇文章的提纲,欢迎大家一块进行探讨,集思广益。其中提到了领域建模的概念,但未作详细解释,希望以后能够有时间我们针对这个命题进行深入探讨。
1)不应该针对整个系统进行数据库设计,而应该根据系统架构中的组件划分,针对每个组件所处理的业务进行组件单元的数据库设计;不同组件间所对应的数据库表之间的关联应尽可能减少,如果不同组件间的表需要外键关联也尽量不要创建外键关联,而只是记录关联表的一个主键,确保组件对应的表之间的独立性,为系统或表结构的重构提供可能性。
2)采用领域模型驱动的方式和自顶向下的思路进行数据库设计,首先分析系统业务,根据职责定义对象。对象要符合封装的特性,确保与职责相关的数据项被定义在一个对象之内,这些数据项能够完整描述该职责,不会出现职责描述缺失。并且一个对象有且只有一项职责,如果一个对象要负责两个或两个以上的职责,应进行分拆。
3)根据建立的领域模型进行数据库表的映射,此时应参考数据库设计第二范式:一个表中的所有非关键字属性都依赖于整个关键字。关键字可以是一个属性,也可以是多个属性的集合,不论那种方式,都应确保关键字能够保证唯一性。在确定关键字时,应保证关键字不会参与业务且不会出现更新异常,这时,最优解决方案为采用一个自增数值型属性或一个随机字符串作为表的关键字。
4)由于第一点所述的领域模型驱动的方式设计数据库表结构,领域模型中的每一个对象只有一项职责,所以对象中的数据项不存在传递依赖,所以,这种思路的数据库表结构设计从一开始即满足第三范式:一个表应满足第二范式,且属性间不存在传递依赖。
5)同样,由于对象职责的单一性以及对象之间的关系反映的是业务逻辑之间的关系,所以在领域模型中的对象存在主对象和从对象之分,从对象是从1-N或N-N的角度进一步主对象的业务逻辑,所以从对象及对象关系映射为的表及表关联关系不存在删除和插入异常。
6)在映射后得出的数据库表结构中,应再根据第四范式进行进一步修改,确保不存在多值依赖。这时,应根据反向工程的思路反馈给领域模型。如果表结构中存在多值依赖,则证明领域模型中的对象具有至少两个以上的职责,应根据第一条进行设计修正。第四范式:一个表如果满足BCNF,不应存在多值依赖。
7)在经过分析后确认所有的表都满足二、三、四范式的情况下,表和表之间的关联尽量采用弱关联以便于对表字段和表结构的调整和重构。并且,我认为数据库中的表是用来持久化一个对象实例在特定时间及特定条件下的状态的,只是一个存储介质,所以,表和表之间也不应用强关联来表述业务(数据间的一致性),这一职责应由系统的逻辑层来保证,这种方式也确保了系统对于不正确数据(脏数据)的兼容性。当然,从整个系统的角度来说我们还是要尽最大努力确保系统不会产生脏数据,单从另一个角度来说,脏数据的产生在一定程度上也是不可避免的,我们也要保证系统对这种情况的容错性。这是一个折中的方案。
8)应针对所有表的主键和外键建立索引,有针对性的(针对一些大数据量和常用检索方式)建立组合属性的索引,提高检索效率。虽然建立索引会消耗部分系统资源,但比较起在检索时搜索整张表中的数据尤其时表中的数据量较大时所带来的性能影响,以及无索引时的排序操作所带来的性能影响,这种方式仍然是值得提倡的。
9)尽量少采用存储过程,目前已经有很多技术可以替代存储过程的功能如“对象/关系映射”等,将数据一致性的保证放在数据库中,无论对于版本控制、开发和部署、以及数据库的迁移都会带来很大的影响。但不可否认,存储过程具有性能上的优势,所以,当系统可使用的硬件不会得到提升而性能又是非常重要的质量属性时,可经过平衡考虑选用存储过程。
10)当处理表间的关联约束所付出的代价(常常是使用性上的代价)超过了保证不会出现修改、删除、更改异常所付出的代价,并且数据冗余也不是主要的问题时,表设计可以不符合四个范式。四个范式确保了不会出现异常,但也可能由此导致过于纯洁的设计,使得表结构难于使用,所以在设计时需要进行综合判断,但首先确保符合四个范式,然后再进行精化修正是刚刚进入数据库设计领域时可以采用的最好办法。
11)设计出的表要具有较好的使用性,主要体现在查询时是否需要关联多张表且还需使用复杂的SQL技巧。
12)设计出的表要尽可能减少数据冗余,确保数据的准确性,有效的控制冗余有助于提高数据库的性能。
WordPress永久链接或固定链接设置技巧
一个网站的永久链接可谓网站的门牌号,好的永久链接可以更受搜索引擎的欢迎,同时也能为你带来更多的流量。那么如何设置永久链接或固定链接才好呢? 我想这个问题也是仁者见仁,智者见智,各有各的看法。下面介绍了WordPress 中,永久链接或固定链接设置技巧,算是我的一家之言吧。
1. 如何设置WordPress 永久链接
登陆WordPress,单击“选项”。然后单击“选项”的下级分类‘永久链接’在常规设置中选择“自定义”,然后在“自定义结构”中填入你想设置的永久链接结构就可以了。
WordPress 永久链接结构主要是通过结构标签来构成的,你只要了解了这些标签就可以任意设置你的永久链接了。WordPress 永久链接结构标签主要有如下这些:
%year% 年,四位数,如:2004
%monthnum% 月,如: 05
%day% 日,如:28
%hour% 时,更精确的时间,如:15
%minute% 分,如:43
%second% 秒,如:33
%postname% 文章名,这是WordPress 永久链接比较常用的标签。如一片文章的标题为“This Is A Great Post”,则使用这个标签的永久链接就会出现“this-is-a-great-post”。中文版的WordPress 显示的则是文章的“日志缩略名”。
%post_id% 文章的唯一标识,如:423
%category% 分类
%author% 文章作者名
2. 尽早修改wordpress的默认永久链接方式
一般是博客刚开通就得修改wordpress的默认永久链接方式,不然等你的博客做了一段时间后,再来修改就很麻烦了。不单以前被搜索引擎收录的网页变成无效网页,而且由于文章内容已经被搜索引擎收录过,新链接被搜索引擎收录的机会将会大大降低。
3. 最好不要让中文出现在链接中
虽然现在搜索引擎已经能支持识别URL,可是中文在URL上还是显示为乱码,对人而言完全没有可读性。中文标题可以使用WordPress的“日志缩略名”,来实现URL英文化。
4. 链接不宜过深
网站的链接过深对于搜索引擎优化是十分的不利的,一般URL的深度不要超过10层。
5.使用伪静态(HTML)链接
总所周知,相对于动态链接搜索引擎更喜欢静态的链接。WordPress默认的链接都是动态的,没关系,我们可以利用WordPress的URL重写功能来轻松实现链接的静态化。只需要在“自定义结构”后加上“.html”就可以搞定了。
6.采用www.web.com/abc/的链接形式
这种链接形式在国外的网站中比较常见,据说这种链接路径比静态的更具有排名优势。
当初选择WordPress的一个很重要的原因,就是看中了WordPress可以自定义永久链接或固定链接。不过这需要你的服务器支持URL Rewrite,一般的服务器商都会开通这个功能,如果你的服务器商没有开通这个功能的话,为了更好的发挥WorPress的优势,我劝你还是换一个服务 器商为好。
sqlplus使用技巧集锦
附录B SQL*PLUS
Sql*plus 中使用绑定变量:sql> variable x number;
sql> exec :x := 7788;
sql> SELECT empno,ename from scott.emp where empno=:x;
SQL*PLUS 是Oracle提供的一个工具程序,它不仅可以用于测试,运行SQL语句和PL/SQL块,而且还可以用于管理Oracle数据库,
1.启动sql*plus
为了使用sql*plus,必须首先要启动sql*plus。Oracle不仅提供了命令行和图形界面的sql*plus,而且还可以在web浏览器中
运行.
(1)在命令运行sql*plus
在命令行运行sql*plus是使用sqlplus命令来完成的,该命令适用于任何操作系统平台,
语法如下:
sqlplus [username]/[password][@server]
如上所示:username用于指定数据库用户名,password用于指定用户口令,server则用于指定主机字符串(网络服务名).
当连接到本地数据时,不需要提供网络服务名,如果要连接到远程数据库,则必须要使用网络服务名.
(2)在windows环境中运行sql*plus
如果在windows环境中安装了oralce数据库产品,那么可以在窗口环境中运行sql*plus
具体方法: “开始->程序->oracle-oradb10g_home1->application development->sql*plus”
2.连接命令
(1)conn[ect]
该命令用于连接到数据库。注意,使用该命令建立新会话时,会自动断开先前会话,示例如下:
sql>conn scott/yhai1981@demo
(2)disc[onnect]
该命令用于断开已经存在的数据库连接。注:该命令只是断开连接会话,而不会退出sql*plus,示例如下:
sql>disc
(3)passw[ord]
该命令用于修改用户的口令。注,任何用户都可以使用该命令修改其自身口令,但如果要修改其他用户的口令时,
则必须以DBA身份(sys和system)登录,在sql*plus中,当修改用户口令时,可以使用该命令取代sql命令alter user,
示例如下:
sql>passw
更改scott的口令
旧口令:******
新口令:******
重新键入新口令:******
口令已更改
sql>
(4)exit
该命令用于退出 sql*plus,另外你也可以使用quit命令退出sql*plus.使用该命令不仅会断开连接,而且也会退出sql*plus
注:默认情况下,当执行该命令时会自动提交事务。
3,编辑命令
(1)l[ist]
该命令用于列出sql缓冲区的内容,使用该命令可以列出sql缓冲某行,某几行或所有行的内容。在显示结果中,数据字为具体
的行号,而”*”则表示当前行。
示例一:列出sql缓冲区所有内容
sql>l
示例二:列出sql缓冲区首行内容:
sql>l1
(2)a[ppend]
该命令用于在sql缓冲区的当前行尾部添加内容。注:该命令将内容追加到标记为”*”的行的尾部,示例如下:
sql>l
1 select empno,ename,sal,hiredate,comm,deptno
2 from emp
3* where deptno=10
sql>a and job=’CLERK’
sql>l
SQL> list
1 select empno,ename,sal,hiredate,comm,deptno
2 from emp
3* where deptno=10 and job=’CLERK’
(3)c[hange]
该命令用于修改sql缓冲区的内容。如果在编写sql语句时写错了某个词,那么使用该命令可以进行修改,
sql>select ename from temp where deptno=10;
SQL> c /temp/emp
1* select ename from emp where deptno=10
(4)del
该命令用于删除sql缓冲区中内容,使用它可以删除某行,某几行或所有行,在默认情况下,当直接执行
del时,只删除当前行的内容,示例如下:
SQL> l
1 select ename
2 from emp
3* where deptno=20
sql>del
SQL> l
1 select ename
2* from emp
如果一次要删除多行,则指定起始行号和终止行号,例如”del 3 5″
(5)i[nput]
该命令用于在sql缓冲区的当前行后新增加一行。示例如下:
SQL> l
1 select ename
2* from emp
sql>i where deptno=30
如果要在首行前增加内容,则使用”0文本”
sql>0 create table temp as
SQL> l
1 create table temp as
2 select ename
3 from emp
4* where deptno=30
(6) n
该数值用于定位sql缓冲区的当前行,示例如下:
(7)edi[t]
该命令用于编辑sql缓冲区的内容。当运行该命令时,在windows平台中会自动启动”记事本”,以编辑sql缓冲区
(8)run和/
run的/命令都可以用于运行sql缓冲区中的sql语句。注:当使用run命令时,还会列出sql缓冲区内容,eg:
SQL> run
1* select ename from emp where deptno=20
4.文件操纵命令
(1)save
该命令用于将当前sql缓冲区的内容保存到sql脚本中。当执行该命令时,默认选项为create,即建立新文件。
eg:
SQL> save c:/a.sql create
已创建 file c:/a.sql
当执行命令之后,就会建立新脚本文件a.sql,并将sql缓冲区内容存放到该文件中。如果sql已经存在,使用
replace选项可以替撚已存在的sql脚本,如果要给已存在的sql脚本追加内容,可以使用append选项。
(2)get
该命令与save命令作用恰好相反,用于将sql脚本中的所有内容装载到sql缓冲区中。
eg:
SQL> get c:/a.sql
1* select ename from emp where deptno=20
(3)start和@
start和@命令用于运行sql脚本文件。注:当运行sql脚本文件时,应该指定文件路径.eg:
SQL> @c:/a.sql
ENAME
———-
SMITH
JONES
SCOTT
ADAMS
FORD
(4)@@
该命令与@命令类似,也可以运行脚本文件,但主要作用是在脚本文件中嵌套调用其它的脚本文件。当使用该命令
嵌套脚本文件时,可在调用文件所在目录下查找相应文件名。
(5)ed[it]
该命令不仅可用于编辑sql缓冲区内容,也可以用于编辑sql脚本文件。当运行该命令时,会启动默认的系统编辑
器来编辑sql脚本。运行方法为:
sql>edit c:/a.sql
(6)spool
该命令用于将sql*plus屏幕内容存放到文本文件中。执行该命令时,应首先建立假脱机文件,并将随后sql*plus
屏幕的所有内容全部存放到该文件中,最后使用spool off命令关闭假脱机文件。eg:
sql>spool c:/a.sql
5.格式命令
sql*plus不仅可以用于执行sql语句、pl/sql块,而且还可以根据select结果生成报表。使用sql*plus的格式命令
可以控制报表的显示格式,例如使用column命令可以控制列的显示格式,使用ttitle命令可以指定页标题;使用
btitle命令可以指定页脚注。
(1)col[umn]
该命令用于控制列的显示格式。column命令包含有四个选项,其中clear选项用于清除已定义列的显示格式:
heading选项用于指定列的显示标题;justify选项用于指定列标题的对齐格式(left,center,right);format选项用于
指定列的显示格式,其中格式模型包含以下一些元素。
An:设置char,varchar2类型列的显示宽度;
9: 在number类型列上禁止显示前导0;
0: 在number类型列上强制显示前导0;
$: 在number类型列前显示美元符号;
L: 在number类型列前显示本地货币符号;
.: 指定number类型列的小数点位置;
,: 指定number类型列的千分隔符;
eg1:使用column设置列显示格式
sql>col ename heading ‘name’ format a10
sql>col sal heading ’sal’ format L99999.99
sql>select ename,sal,hiredate from emp
sql>where empno=7788;
name sal HIREDATE
———- ——————- ——————-
SCOTT ¥3000.00 04/19/1987 00:00:00
sql>col ename clear
sql>col sal clear
sql>select ename,sal,hiredate from emp
sql>where empno=7788;
(2)title
该命令用于指定页标题,页标题会自动显示在页的中央。如果页标题由多个词组成,则用单引号引住。如果要将页
标题分布在多行显示,则用”|”分开不同单词。如果不希望显示页标题,则使用”ttitle off”命令,禁止显示,eg:
SQL> set linesize 40
SQL> ttitle ‘employee report’
SQL> select ename,sal,hiredate from emp where empno=7788;
星期二 5月 20 第 1
employee report
ENAME SAL
———- ———-
HIREDATE
——————-
SCOTT 3000
04/19/1987 00:00:00
(3)btitle
该命令用于指定页脚注,页脚注会自动显示在页的中央。如果页脚注由多个词组成,则用单引号引注。如果要将页脚注
分布在多行显示,则用”|”分开不同单词。如果不希望显示页脚注,则使用”btitle off”命令,禁止显示。eg:
SQL> btitle ‘page end’
SQL> select ename,sal,hiredate from emp where empno=7788
ENAME SAL
———- ———-
HIREDATE
——————-
SCOTT 3000
04/19/1987 00:00:00
page end
(4)break
该命令用于禁止显示重复行,并将显示结果分隔为几个部分,以表现更友好的显示结果,通常应该在order by 的排序列上
使用该命令。eg:
SQL> set pagesize 40
SQL> break on deptno skip 1
SQL> select deptno,ename,sal from emp order by deptno
2 ;
DEPTNO ENAME SAL
———- ———- ———-
10 CLARK 2450
KING 5000
MILLER 1300
20 JONES 2975
FORD 3000
ADAMS 1100
SMITH 800
SCOTT 3000
30 WARD 1250
TURNER 1500
ALLEN 1600
JAMES 950
BLAKE 2850
MARTIN 1250
6.交互式命令
如果经常要执行某些sql语句和sql*plus命令,可以将这些语句和命令存放到sql脚本中。通过使用sql脚本,
一方面可以降低命令输入量,另一方面可以避免用户的输入错误。为了使得sql脚本可以根据不同输入获得
不同结果,需要在sql脚本中包含交互式命令。通过使用交互式命令,可以在sql*plus中定义变量,并且在运行
sql脚本时可以为这些变量动态输入数据。下面介绍sql*plus的交互命令,以及引用变量所使用的标号。
(1)&
引用替代变量(substitution variable)时,必须要带有该标号。如果替代变量已经定义,则会直接使用其数据,
如果替代变量没有定义,则会临时定义替代变量(该替代变量只在当前语句中起作用),并需要为其输入数据。
注:如果替代变量为数字列则提供数据,则可以直接引用;如果替代变量为字符类型列或日期类型列提供数据,
则必须要用单引号引注。eg:
SQL> select ename,sal from emp where deptno=&no and job=’&job’;
输入 no 的值: 20
输入 job 的值: CLERK
原值 1: select ename,sal from emp where deptno=&no and job=’&job’
新值 1: select ename,sal from emp where deptno=20 and job=’CLERK’
(2)&&
该标号类似于单个&标号。但需要注意,&标号所定义的替代变量只在当前语句中起作用;而&&标号所定义的变量
会在当前sql*plus环境中一直生效。eg:
SQL> select ename,sal from emp where deptno=&&no and job=’&&job’ –定义了no变量
输入 no 的值: 20
输入 job 的值: CLERK
原值 1: select ename,sal from emp where deptno=&&no and job=’&&job’
新值 1: select ename,sal from emp where deptno=20 and job=’CLERK’
SQL> select ename,sal from emp where deptno=&no;
原值 1: select ename,sal from emp where deptno=&no –直接引用no变量
新值 1: select ename,sal from emp where deptno=20
ENAME SAL
———- ———-
SMITH 800
JONES 2975
SCOTT 3000
ADAMS 1100
FORD 3000
如例所示,当第一次引用no变量时,使用&&标号需要为其输入数据;当第二次引用no变量时,
使用&标号直接引用其原有值,而不需要输入数据。
(3)define
该命令用于定义类型为char的替代变量,而且该命令的定义的替代变量只在当前sql*plus环境中起作用。
当使用该命令定义变量时,如果变量值包含空格或区分大小写,则用引号引注。另外,使用”define变量名”可以检查变量
是否已经定义。eg:
sql>set verify off
sql>define title=CLERK
sql>select ename,sal from where job=’&title’;
(4)accept
该命令可以用于定义char,number和date类型的替代变量。与define命令相比,accept命令更加灵活。当使用该命令定义替代
变量时,还可以指定变量输入提示、变量输入格式、隐藏输入内容。
eg1:指定变量输入提示
SQL> accept title prompt ‘请输入岗位:’
请输入岗位:CLERK
SQL> select ename,sal from emp where job=’&title’;
原值 1: select ename,sal from emp where job=’&title’
新值 1: select ename,sal from emp where job=’CLERK’
ENAME SAL
———- ———-
SMITH 800
ADAMS 1100
JAMES 950
MILLER 1300
eg2:隐藏用户输入
sql>accept pwd hide
(5)undefine
该命令用于清除替代变量的定义。eg:
sql>undefine pwd
SQL> disc
从 Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With the Partitioning, OLAP and Data Mining options 断开
SQL> conn scott/&pwd
输入 pwd 的值: yhai1981
已连接
(6)prompt的pause
prompt命令用于输出提示信息,而pause命令则用于暂停脚本执行。在sql脚本中结合使用这两条命令,可以控制sql脚本
的暂停的执行。假定在a.sql脚本中包含以下命令:
prompt ‘按<Return>键继续’
pause
当运行该sql脚本时,会暂停执行,eg:
sql>@c:/a.sql
‘按<Return>键继续’
(7)variable
该命令用于在sql*plus中定义绑定变量。当在sql语句或pl/sql块中引用绑定变量时,必须要在绑定变量前加冒号(:);
当直接给绑定变量赋值时,需要使用execute命令(类似于调用存储过程).示例如下:
sql>var no number
sql>exec :no:=7788
sql>select ename from emp where empno=:no;
ename
——————
scott
(8)print
该命令用于输出绑定变量结果,eg:
SQL> print no
NO
———-
7788
7.显示和设置环境变量
使用sql*plus的环境变量可以控制其运行环境,例如设置行显示宽度,设置每页显示的行数、
设置自动提交标记、设置自动跟踪等等。使用show命令可以显示当前sql*plus的环境变量设置
:使用set命令可以修改当前sql*plus的环境变量设置。下面介绍常用的sql*plus环境变量。
(1)显示所有环境变量
为了显示sql*plus的所有环境变量,必须要使用show all命令。示例如下:
SQL> show all
appinfo 为 OFF 并且已设置为 “SQL*Plus”
arraysize 15
autocommit OFF
autoprint OFF
autorecovery OFF
autotrace OFF
blockterminator “.” (hex 2e)
btitle OFF 为下一条 SELECT 语句的前几个字符
cmdsep OFF
colsep ” ”
compatibility version NATIVE
concat “.” (hex 2e)
copycommit 0
COPYTYPECHECK 为 ON
define “&” (hex 26)
describe DEPTH 1 LINENUM OFF INDENT ON
echo OFF
editfile “afiedt.buf”
embedded OFF
escape OFF
用于 6 或更多行的 FEEDBACK ON
flagger OFF
flush ON
heading ON
headsep “|” (hex 7c)
instance “local”
linesize 80
lno 4
loboffset 1
logsource “”
long 80
longchunksize 80
SPOOL OFF ENTMAP ON PREFORMAT OFF
newpage 1
null “”
numformat “”
numwidth 10
pagesize 14
PAUSE 为 OFF
pno 1
recsep WRAP
recsepchar ” ” (hex 20)
release 1002000100
repfooter OFF 为 NULL
repheader OFF 为 NULL
serveroutput OFF
shiftinout INVISIBLE
showmode OFF
spool ON
sqlblanklines OFF
sqlcase MIXED
sqlcode 0
sqlcontinue “> ”
sqlnumber ON
sqlpluscompatibility 10.2.0
sqlprefix “#” (hex 23)
sqlprompt “SQL> ”
sqlterminator “;” (hex 3b)
suffix “sql”
tab ON
termout ON
timing OFF
trimout ON
trimspool OFF
ttitle OFF 为下一条 SELECT 语句的前几个字符
underline “-” (hex 2d)
USER 为 “SCOTT”
verify ON
wrap : 将换至下一行
SQL> spool off
(2)arraysize
该环境变量用于指定数组提取尺寸,其默认值为15.该值越大,网络开销将会越低,但占用内存会增加。假定使用默认值,
如果查询返回行数为50行,则需要通过网络传送4将数据;如果设置为25,则网络传送次数只有两次。eg:
SQL> show arraysize
arraysize 15
SQL> set arraysize 25
(3)autocommit
该环境变量用于设置是否自动提交dml语句,其默认值为off(表示禁止自动提交)。当设置为ON时,每次执行DML
语句都会自动提交。eg:
SQL> show autocommit
autocommit OFF
SQL> set autocommit on
SQL> show autocommit
autocommit IMMEDIATE
(4)colsep
该环境变量用于设置列之间的分隔符,默认分隔符为空格。如果要使用其它分隔符,则使用set命令进行设置。eg:
sql>set colsep |
SQL> select ename,sal from emp where empno=7788
ENAME | SAL
———-|———-
SCOTT | 3000
(5)feedback
该环境变量用于指定显示反馈行数信息的最低行数,其默认值为6。如果要禁止显示行数反馈信息,则将feedback
设置为off。假设只要有查询结果就返回行数,那么可以将该环境变量设置为1.eg:
sql>set feedback 1
sql>select ename,sal from emp where empno=7788;
ENAME | SAL
———-|———-
SCOTT | 3000
已选择 1 行。
(6)heading
该环境变量用于设置是否显示标题,其默认值为on。如果不显示列标题,则设置为off。eg:
sql>set heading off
sql>select ename,sal from emp where empno=7788
SCOTT | 3000
(7)linesize
该环境变量用于设置行宽度,默认值为80。在默认情况下,如果数据长度超过80个字符,那么在sql*plus中会折
行显示数据结果。要在一行中显示全部数据,应该设置更大的值。eg:
(8)pagesize
该环境变量用于设置每页所显示的行数,默认值为14
set pagesize 0; //输出每页行数,缺省为24,为了避免分页,可设定为0。
(9)long
该环境变量用于设置long和lob类型列的显示长度。默认值为80,也就是说当查询long或lob列时,只会显示该列的前80个字符,
应该设置更大的值。eg:
sql>show long
long 80
sql>set long 300
(10)serveroutput
该环境变量用于控制服务器输出,其默认值为off,表示禁止服务器输出。在默认情况下,当调用dbms_output包时,
不会在sql*plus屏幕上显示输出结果。在调用dbms_output包时,为了在屏幕上输出结果,必须要将serveroutput设置
为on。eg:
sql>set serveroutput on
sql>exec dbms_output.put_line(’hello’)
(11)termout
该环境变量用于控制sql脚本的输出,其默认值为ON。当使用默认值时,如果sql脚本有输出结果,则会在屏幕上输出
显示结果,如果设置为OFF,则不会在屏幕上输出sql脚本。eg:
SQL> set termout off
SQL> @c:/a
(12)time
该环境变量用于设置在sql提示符前是否显示系统时间,默认值为off,表示禁止显示系统时间。如果设置为on,
则在sql提示符前会显示系统时间.eg:
SQL> set time on
12:09:59 SQL>
(13)timing
该环境变量用于设置是否要显示sql语句执行时间,默认值为off,表示不会显示sql语句执行时间。如果设置为
ON,则会显示sql语句执行时间。eg:
sql>set timing on
SQL> select count(*) from emp;
COUNT(*)
———-
14
已选择 1 行。
已用时间: 00: 00: 00.03
(14)trimspool
set trimout on; //去除标准输出每行的拖尾空格,缺省为off
set trimspool on; //去除重定向(spool)输出每行的拖尾空格,缺省为off
如果trimspool设置为on,将移除spool文件中的尾部空格 ,trimout同trimspool功能相似,只不过对象是控制台。
If trimspool is set to on, it will remove trailing blanks in spooled files.
See also trimout which does the same thing to the output to the console (terminal).
eg:
set trimspool off
spool c:/temp/trimspool.txt
declare
v_name varchar2(30);
begin
SELECT table_name into v_name
FROM all_tables
WHERE rownum =1;
dbms_output.put_line(v_name);
end;
/
set trimspool on
declare
v_name varchar2(30);
begin
SELECT table_name into v_name
FROM all_tables
WHERE rownum =1;
dbms_output.put_line(v_name);
end;
/
spool off
10个Wordpress上最受欢迎的SEO插件
搜索引擎的地位越来越重要,那么SEO(搜索引擎优化)对于大型网站来说就很重要,但对博客来说,也是很重要的。但如果你像我一样,对SEO不了解,那借助于现成的工具是个非常好的做法。这篇文章将介绍10个Wordpress上最受欢迎的SEO插件,让你能更好地利用“长尾”。
这个插件能优化文章的标题,比如可以方便地设置文章标题与博客名之间的连接符,例如“|”和“-”。也可以使在首页显示博客的描述而在其它页面不显示。
实现的功能和SEO Title Tag相同,对标题进行优化,但功能相对弱一点。
这个插件能自动在文章代码里加入Meta描述,这样能让搜索引擎更好地对文章归类关键字。由于大多数搜索引擎对meta描述的限制是160个字符,安装后可能需要修改插件的代码。
这是一个非常优秀的标签插件,在编辑文章的时候为文章加上标签,标签就会出现在meta 关键字里。在Wordpress2.3还未推出的时候,几乎所有人都会安装。除了对SEO有用,对于直接浏览者来说也是相当有用的,最直接的作用是可以用来显示相关文章。
多合一SEO包,相信大多数wp使用者都会安装这个插件,因为这个插件能完成上述4个插件的SEO功能。包括标题优化、生成meta描述和meta关键字。但All In One不一定是最好的,第3个和第4个插件还是非常推荐安装的。
如果你在Wordpress里启动了Permalink,那么这个插件将是必须的,因为规范化URL是很有用的。例如http://www.dbaol.cn/?p=321 和http://www.dbaol.cn/post/321.html将指向通一个页面。使用这个插件能让这两个地址通过301转向统一到一个地址上。
这个插件基于Ajax,操作极为方便。插件可以让你自如地管理博客里的301转向,包括创建和修改。在新版本里,不但可以设置301转向,302和307都是允许的。
又一个301转向插件,除了能实现Permalink Migration的功能之外,还可以实现将带有www和没有www的地址重定向在一起,还可以把feed转向到feedburner,即便后者已经被和谐。
这个插件的重要性不言而喻,你不能总等搜索引擎自己去发现你博客上的链接吧?何不做一个网站地图告诉搜索引擎博客上有什么链接呢?
你是否需要了解浏览者在你的blog上搜索了什么呢?这个插件能帮助你,它会记录浏览者的搜索记录。
这些插件都是从搜索引擎里收集的,找到后再筛选出10个,终于写完了,累了。
- DBA的内容挺多啊【转帖】
- DBA的工作内容
- 管理DBA的工作内容和责任
- Oracle DBA日常工作内容
- DBA需要知道的Oracle 10g的审计内容
- DBA需要知道的Oracle 10g的审计内容
- DBA需要知道的Oracle 10g的审计内容
- SQL Server 数据库管理员(DBA)的工作内容
- 【SQL Server DBA】SQL Server DBA工作内容、工作清单
- Oracle需要学习的内容(Programmer方向和DBA方向)
- SQL Server DBA工作内容详解
- SQL Server数据库DBA工作内容详解
- SQL Server DBA工作内容详解
- SQL Server DBA工作内容详解
- SQL Server DBA工作内容详解
- SQL Server DBA工作内容详解
- 【Vegas转帖】DBA日常工作职责 - eygle对DBA的七点建议
- 【Vegas转帖】DBA日常工作职责 - eygle对DBA的七点建议
- 在c#中,利用npgsql连接postgresql
- Eclipse JDBC 驱动程序设置
- 页面传值
- WARNING 15 (MULTIPLE CALL TO SEGMENT)---keil_52
- 2005 分頁 新利器 row_Number()
- DBA的内容挺多啊【转帖】
- 关于DSP6000 CCS BOIS 的原子操作-数据保护
- Hyper-V,虚拟多元化
- 闰年因果分析图
- 三十岁以后程序员的发展之路
- vc 动态菜单
- 字符串流
- Ant 學習資源
- 实现在sql中的类型转换


