人工智能-机器学习之梯度学习
来源:互联网 发布:网店淘宝拍拍 编辑:程序博客网 时间:2024/06/13 00:32

引言
梯度下降法 (Gradient Descent Algorithm,GD) 是为目标函数J(θ),如代价函数(cost function), 求解全局最小值(Global Minimum)的一种迭代算法。本文会详细讨论按照准确性和耗费时间(accuracy and time consuming factor)将梯度下降法进行分类。这个算法在机器学习中被广泛用来最小化目标函数,如下图所示。
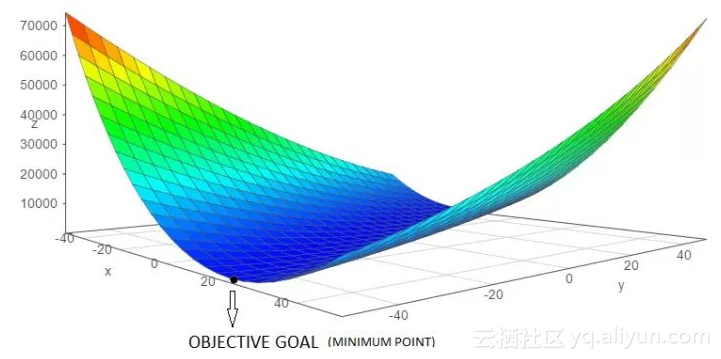
为什么使用梯度下降法
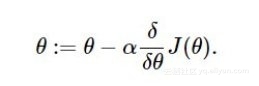
α表示学习速率(learning rate)。
在本文中,考虑使用线性回归(linear regression)作为算法实例,当然梯度下降法也可以应用到其他算法,如逻辑斯蒂回归(Logistic regression)和 神经网络(Neural networks)。在线性回归中,我们使用如下拟合函数(hypothesis function):
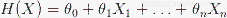
其中, 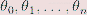 是参数,
是参数,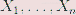 是输入特征。为了求解线性回归模型,需要找到合适的参数使拟合函数能够更好地适合模型,然后使用梯度下降最小化代价函数J(θ)。
是输入特征。为了求解线性回归模型,需要找到合适的参数使拟合函数能够更好地适合模型,然后使用梯度下降最小化代价函数J(θ)。
代价函数(普通的最小平方差,ordinary least square error)如下所示:
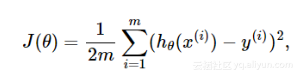
代价函数的梯度(Gradient of Cost function):
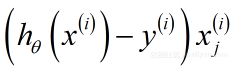
参数与代价函数关系如下图所示:
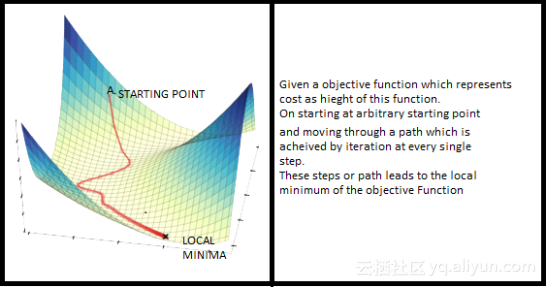
梯度下降法的工作原理
梯度下降法的类型
基于如何使用数据计算代价函数的导数,梯度下降法可以被定义为不同的形式(various variants)。确切地说,根据使用数据量的大小(the amount of data),时间复杂度(time complexity)和算法的准确率(accuracy of the algorithm),梯度下降法可分为:
1. 批量梯度下降法(Batch Gradient Descent, BGD);
2. 随机梯度下降法(Stochastic Gradient Descent, SGD);
3. 小批量梯度下降法(Mini-Batch Gradient Descent, MBGD)。
批量梯度下降法原理
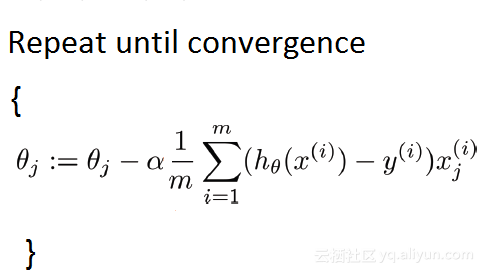
其中,m是训练样本(training examples)的数量。
Note:
1. 如果训练集有3亿条数据,你需要从硬盘读取全部数据到内存中;
2. 每次一次计算完求和后,就进行参数更新;
3. 然后重复上面每一步;
4. 这意味着需要较长的时间才能收敛;
5. 特别是因为磁盘输入/输出(disk I/O)是系统典型瓶颈,所以这种方法会不可避免地需要大量的读取。
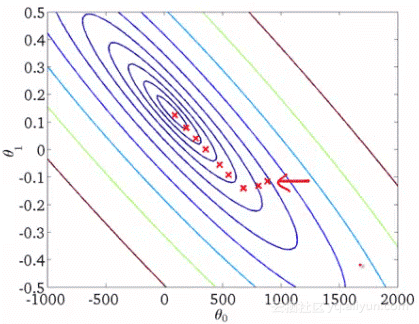
上图是每次迭代后的等高线图,每个不同颜色的线表示代价函数不同的值。运用梯度下降会快速收敛到圆心,即唯一的一个全局最小值。
批量梯度下降法不适合大数据集。下面的Python代码实现了批量梯度下降法:
1.import numpy as np 2.import random 3.def gradient_descent(alpha, x, y, ep=0.0001, max_iter=10000): 4. converged = False 5. iter = 0 6. m = x.shape[0] # number of samples 7. 8. # initial theta 9. t0 = np.random.random(x.shape[1]) 10. t1 = np.random.random(x.shape[1]) 11. 12. # total error, J(theta) 13. J = sum([(t0 + t1*x[i] - y[i])**2 for i in range(m)]) 14. 15. # Iterate Loop 16. while not converged: 17. # for each training sample, compute the gradient (d/d_theta j(theta)) 18. grad0 = 1.0/m * sum([(t0 + t1*x[i] - y[i]) for i in range(m)]) 19. grad1 = 1.0/m * sum([(t0 + t1*x[i] - y[i])*x[i] for i in range(m)]) 20. # update the theta_temp 21. temp0 = t0 - alpha * grad0 22. temp1 = t1 - alpha * grad1 23. 24. # update theta 25. t0 = temp0 26. t1 = temp1 27. 28. # mean squared error 29. e = sum( [ (t0 + t1*x[i] - y[i])**2 for i in range(m)] ) 30. 31. if abs(J-e) <= ep: 32. print 'Converged, iterations: ', iter, '!!!' 33. converged = True 34. 35. J = e # update error 36. iter += 1 # update iter 37. 38. if iter == max_iter: 39. print 'Max interactions exceeded!' 40. converged = True 41. 42. return t0,t1 随机梯度下降法原理

这里m表示训练样本的数量。
如下为随机梯度下降法的伪码:
1. 进入内循环(inner loop);
2. 第一步:挑选第一个训练样本并更新参数,然后使用第二个实例;
3. 第二步:选第二个训练样本,继续更新参数;
4. 然后进行第三步…直到第n步;
5. 直到达到全局最小值
如下图所示,随机梯度下降法不像批量梯度下降法那样收敛,而是游走到接近全局最小值的区域终止。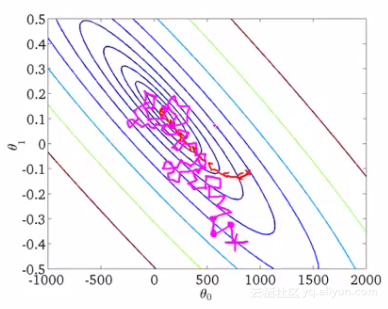
小批量梯度下降法原理
小批量梯度下降法是最广泛使用的一种算法,该算法每次使用m个训练样本(称之为一批)进行训练,能够更快得出准确的答案。小批量梯度下降法不是使用完整数据集,在每次迭代中仅使用m个训练样本去计算代价函数的梯度。一般小批量梯度下降法所选取的样本数量在50到256个之间,视具体应用而定。
1.这种方法减少了参数更新时的变化,能够更加稳定地收敛。
2.同时,也能利用高度优化的矩阵,进行高效的梯度计算。
随机初始化参数后,按如下伪码计算代价函数的梯度: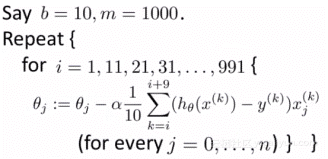
Notes:
1. 实现该算法时,同时更新参数。

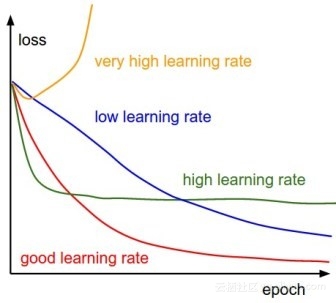
2. 学习速率α(也称之为步长)。如果α过大,算法可能不会收敛;如果α比较小,就会很容易收敛。
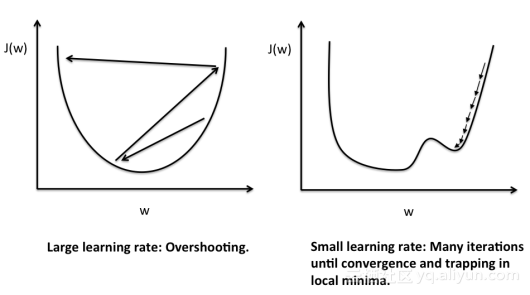
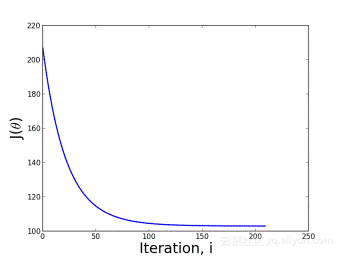
3. 检查梯度下降法的工作过程。画出迭代次数与每次迭代后代价函数值的关系图,这能够帮助你了解梯度下降法是否取得了好的效果。每次迭代后J(θ)应该降低,多次迭代后应该趋于收敛。

4. 不同的学习速率在梯度下降法中的效果
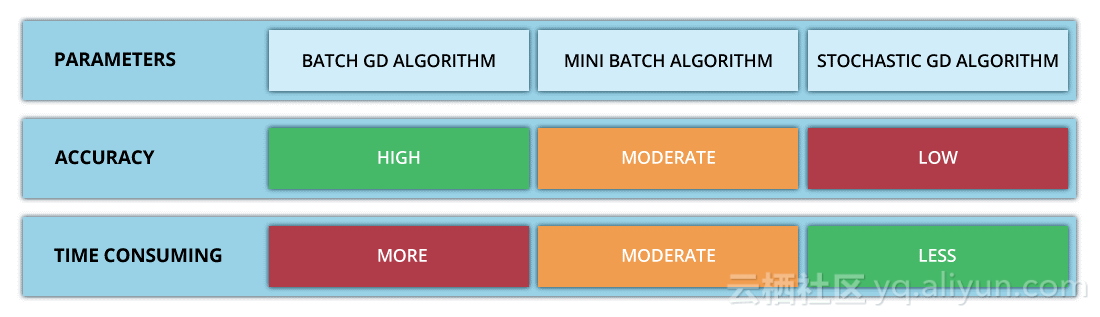
总结
本文详细介绍了不同类型的梯度下降法。这些算法已经被广泛应用于神经网络。下面的图详细展示了3种梯度下降法的比较。
- 人工智能-机器学习之梯度学习
- 机器学习之-梯度下降【人工智能工程师--AI转型必修课】
- 人工智能之机器学习
- 人工智能之机器学习
- 机器学习之梯度下降
- 人工智能之机器学习路线图
- 人工智能之机器学习路线图
- 人工智能之机器学习路线图
- 人工智能之机器学习路线图
- 浅谈人工智能之机器学习
- 人工智能之机器学习路线图
- 人工智能之机器学习路线图
- 机器学习之梯度下降学习笔记
- 机器学习之梯度下降法
- 机器学习系列之梯度下降法
- 机器学习之梯度下降法
- 机器学习之梯度下降算法
- 机器学习笔记之梯度下降
- 微信发送位置源码
- sql查询之左连接,右连接,内连接以及全外连接的使用(测试常见面试题欧)
- 第一篇技术博客
- 使用移动平均的图像阈值处理
- 我行我素购物管理系统(面向对象)
- 人工智能-机器学习之梯度学习
- Docker学习文档之二 搭建环境-Windows环境
- Python及Python第三方包安装
- c++11 获取毫秒数
- redis笔记-常用命令篇(采用与《redis入门指南》)
- 以太网帧格式(TCP/IP详解)
- Docker学习文档之二 搭建环境-Linux环境
- dubbo 请求调用过程分析
- SpringBoot学习-第四章 SpringMVC基础-<Spring Boot 实战>


