机器学习入门了解
来源:互联网 发布:ubuntu下安装mysql 编辑:程序博客网 时间:2024/05/18 15:56
机器学习入门了解
http://blog.jobbole.com/109702/
根据历史数据建立静态的模型,随着数据的增加随时间不断变化的动态模型。用于预测未来的数据
模型
一种机器学习方法的结果以及该方法采用的算法。
可以在监督学习中用来做预测,或者在无监督学习中用来检索聚类。
“在线训练”往一个已经存在的模型中添加训练数据
“离线训练”从头开始建立一个新模型
监督学习
明确定义要使用的特征,以及预期的输出结果
分类
考虑一组标签以及一些已经打上正确标签的数据,我们想要做的就是为新数据预测标签。然而,在把数据考虑为分类问题之前,你应该
分析一下数据的特点。如果数据的结构明显可以让你轻松地画出一条回归线,那么应用回归算法反而会更好。如果数据无法拟合出一条回归线,或者当算法的性能不理想时,那么分类就是一个很好的选择。回归
回归分析预测的是
实际值而不是标签常见的陷阱是过拟合、欠拟合以及对模型如何控制外推法与内插法欠缺考虑。
无监督学习
不需要事先确切地了解输出结果
中心思想是发掘出一个数据集内在的结构
组合过程基于这些特征之间可能隐含的关联。另一个无监督学习的例子是 K-均值聚类。K-均值聚类就是要找出一个数据集中的分组,之后这些分组可以用于其他目的
机器学习的基本流程
1.搜集数据
2.把数据分割为测试集和训练集
3.训练一个模型(应用某种机器学习算法)
4.验证模型,验证方法需要使用模型和测试数据
5.基于模型作出预测 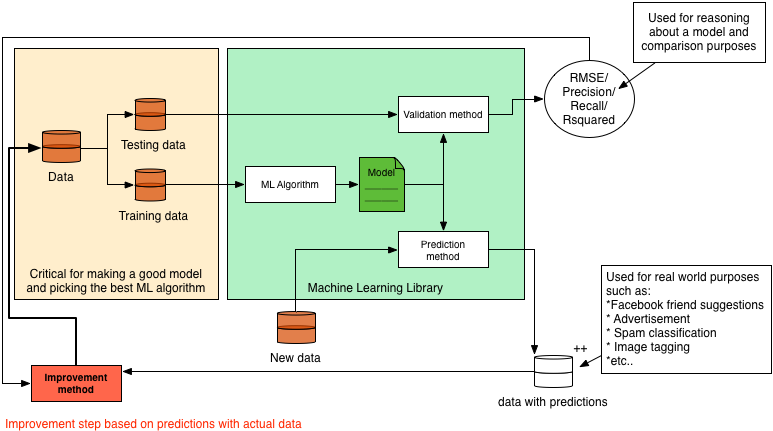
数据集随时间而增大,所以我们要不断更新模型,加入新数据,使预测更准确。不过,在这个过程中,数据的量级及其突变率起着决定性作用。
0 0
- 机器学习入门了解
- 机器学习入门之了解机器学习
- 机器学习入门-了解相关概念
- 机器学习入门了解(好文!)
- 机器学习之入门篇(了解机器学习)
- 了解点机器学习
- 机器学习初步了解
- 3分钟了解入门「机器学习」该学习什么?(下)
- 3分钟了解入门「机器学习」该学习什么?(上)
- 转载-3分钟了解入门「机器学习」该学习什么?(上)
- 转载-3分钟了解入门「机器学习」该学习什么?(下)
- 3分钟了解入门「机器学习」该学习什么?(上)
- 3分钟了解入门「机器学习」该学习什么?(下)
- 机器学习之 了解TensorFlow
- 机器学习需了解“三大法宝”、、、
- 机器学习入门资料
- 机器学习入门
- 机器学习入门
- spring boot整合shiro引用配置文件配置是出现的问题
- Linux学习笔记11
- 社会浮躁,太多女孩一副娼妓面孔
- Jackcard
- Nginx 源码阅读笔记4 启动流程
- 机器学习入门了解
- IOS Block研究
- Axure8.0 页面上下滑动效果实现
- Ubuntu设置系统时间与网络时间同步
- mybatis增强版(mybatis-plus)
- [centos]给予用户sudo命令的权限
- Optional小小总结
- 面向对象设计原则之依赖倒转原则
- secureCRT简介


