double数据的内存存储方式
来源:互联网 发布:mac openssl devel 编辑:程序博客网 时间:2024/05/21 09:47
任何数据在内存中都是以二进制(0或1)顺序存储的,每一个1或0被称为1位,而在x86CPU上一个字节是8位。比如一个16位(2字节)的short int型变量的值是1000,那么它的二进制表达就是:00000011 11101000。由于Intel CPU的架构原因,它是按字节倒序存储的,那么就因该是这样:11101000 00000011,这就是定点数1000在内存中的结构。
目前C/C++编译器标准都遵照IEEE制定的浮点数表示法来进行float,double运算。这种结构是一种科学计数法,用符号、指数和尾数来表示,底数定为2——即把一个浮点数表示为尾数乘以2的指数次方再添上符号。下面是具体的规格:
````````符号位 阶码 尾数 长度
float 1 8 23 32
double 1 11 52 64
临时数 1 15 64 80
由于通常C编译器默认浮点数是double型的,下面以double为例:
共计64位,折合8字节。由最高到最低位分别是第63、62、61、……、0位:
最高位63位是符号位,1表示该数为负,0正;
62-52位,一共11位是指数位;
51-0位,一共52位是尾数位。
按照IEEE浮点数表示法,下面将把double型浮点数38414.4转换为十六进制代码。
把整数部和小数部分开处理:整数部直接化十六进制:960E。小数的处理:
0.4=0.5*0+0.25*1+0.125*1+0.0625*0+……
小数的处理(http://blog.csdn.net/lin200753/article/details/27952897):
在十进制中小数有些是无法完整用二进制表示的。它们只能用有限位来表示,从而在存储时可能就会有误差。十进制的小数采用乘2取整法进行计算,取掉整数部分后,剩下的小数继续乘以2,直到小数部分全为0.
如0.125变成二进制为
0.125*2=0.25 .....取整0
0.25*2=0.5 ........取整0
0.5*2= 1.0 ………取整1
0.0*2=0
所以0.125的二进制为0.001
如果你够耐心,手工算到53位那么因该是:38414.4(10)=1001011000001110.0110101010101010101010101010101010101(2)
科学记数法为:1.001……乘以2的15次方。指数为15!
于是来看阶码,一共11位,可以表示范围是-1024~1023。因为指数可以为负,为了便于计算,规定都先加上1023,在这里, 15+1023=1038。二进制表示为:100 00001110
符号位:正—— 0 !
合在一起(尾数的表示:去掉小数点前面的1):
01000000 11100010 11000001 11001101 01010101 01010101 01010101 01010101
按字节倒序存储的十六进制数就是:
55 55 55 55 CD C1 E2 40
网址:http://blog.csdn.net/lai123wei/article/details/7220684
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit, 无论是单精度还是双精度在存储中都分为三个部分:
首先说一下原,反,补,移码. 移码其实就等于补码,只是符号相反. 对于正数而言,原,反,补码都一样, 对负数而言,反码除符号位外,在原码的基础上按位取反,补码则在反码的基础之上,在其最低位上加1,要求移码时,仍然是先求补码,再改符号.
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
A,阶码是用移码表示的,这里会有一个127的偏移量,它的127相当于0,小于127时为负,大于127时为正,比如:10000001表示指数为129-127=2,表示真值为2^2,而01111110则表示2^(-1).
有移码表示阶码有是有原因的,主要是移码便于对阶操作,从而比较两个浮点数的大小. 这里要注意的是,阶码不能达到11111111的形式,IEEE规定,当编译器遇到阶码为0XFF时,即调用溢出指令. 总之,阶码化为整数时,范围是:-127~127.
double:符号位1,阶码11(固定偏移 3FF),尾数52,固定隐含位有
long double:符号位1,阶码15(固定偏移3FFF),尾数64,固定隐含位无
某些编译器中把long double作double处理
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
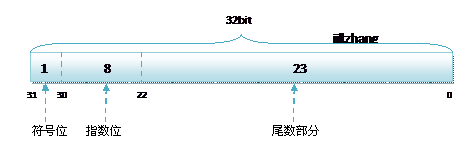
而双精度的存储方式为:

float和double的精度是由尾数的位数来决定的。浮点数在内存中是按科学计数法来存储的,其整数部分始终是一个隐含着的“1”,由于它是不变的,故不能对精度造成影响。
float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;
double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
注:本文在写作过程中,参照了如下资料:
http://www.msdn.net/library/chs/default.asp?url=/library/CHS/vccore/html/_core_why_floating_point_numbers_may_lose_precision.asp
http://blog.csdn.net/ganxingming/archive/2006/12/19/1449526.asp
http://blog.csdn.net/hziee_/archive/2007/01/08/1477427.aspx
http://blog.csdn.net/biblereader/article/details/819428
网址:http://www.cnblogs.com/yaozhongxiao/archive/2010/09/08/1821185.html
float与double类型的内存分布,精度和范围
float与double类型的内存分布,精度和范围
内存分布:
C/c++的浮点数据类型有float和double两种。
float大小为4字节,内存中的存储方式如下:
符号位(1bit)指数(8bit)尾数(23bit)
double大小为8字节,内存中的存储方式如下:
符号位(1bit)指数(11bit)尾数(52bit)
符号位决定浮点数的正负,0正1负。指数和尾数均从浮点数的二进制科学计数形式中获取。
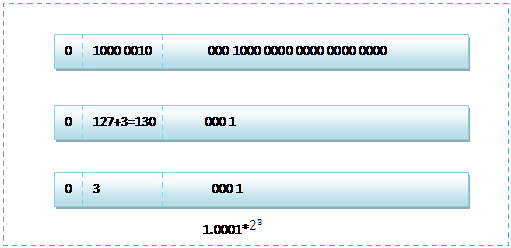
如,十进制浮点数2.5的二进制形式为10.1,转换为科学计数法形式为(1.01)*(10^1)。
由此可知指数为1,尾数(即科学计数法的小数部分)为01。
根据浮点数的存储标准,指数用移码表示。0的float类型移码为127(0111 1111),0的double类型移码为1023(011 1111 1111)。运算时,在0 的移码基础上加指数,得到的就是内存中指数的表示形式。尾数则直接填入,如果空间多余则以0补齐,如果空间不够则0舍1入。
所以float和 double类型分别表示的2.5如下(二进制):
符号位 指数 尾数
0 1000 0000 010 0000 0000 0000 0000 0000
0 100 0000 0000 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
精度:
float和double的精度是由尾数的位数来决定的。
float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字; double:2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
范围:
float类的指数是8位移码,最大为127最小为-127,127用来作2的指数,为2^127,约等于 1.7014*10^38, 而我们知道,floa示数范围约为- 3.4*10^38-------3.4*10^38, 这是因为尾数都为1时,即1.11..11约为2,因此浮点数的范围就出来了.double的情况与float完全相似.
网址:http://blog.csdn.net/rambo_ghaip/article/details/4578760
- double数据的内存存储方式
- double数据的内存存储方式
- 转帖:float型和double型数据的存储方式
- 转帖:float型和double型数据的存储方式
- Double型数据的存储方式和计算方法
- float型和double型数据的存储方式
- float double 的存储方式
- 内存中数据的存储方式
- float和double在的存储方式
- float和double在的存储方式
- float和double在的存储方式
- float和double在的存储方式
- 浮点数据(float/double)在计算机上的存储方式
- double类型内存存储
- 内存的存储方式
- 内存的存储方式
- float和double的数据存储形式
- VS中double的数据存储
- python 匿名函数捕获变量值的问题
- 发现了cntk 2.0 rnn方面的一个bug
- 为什么黑客喜欢攻击中小互联网金融公司
- Mat与IplImage之间的转化
- 小猴子下落
- double数据的内存存储方式
- LeetCode056 Merge Intervals
- 阴阳师手游平民强力式神组合推荐
- web前端编码错误总结
- notify和wait
- 8种常见机器学习算法比较
- 关于使用极光推送报 java.lang.ClassNotFoundException: com.google.gson.Gson”错误记录
- LeetCode057 Insert Interval
- 据说年薪30万的Android程序员必须知道的帖子


