[TensorFlow]修炼tfboy入门学习笔记-1
来源:互联网 发布:网络公开课 编辑:程序博客网 时间:2024/06/06 15:36
TensorFlow 入门学习
最近开始学习TensorFlow,看到在github上tf持续升温。自己也努力修炼成一个tfboy吧。
TensorFlow使用图来表示计算任务,使用tensor表示数据,在session中执行图,通过变量维护图的状态,使用feed和fetch 在图中赋值或者获取数据
在我自己的理解,tensorflow本身是一个数据流图的形式,每个节点称为op(operation),每个op可以获得或者输出多个tensor,而tensor是一个类型化的多维数据。官方文档中的例子是:你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels]。这就是tensor(张量)。
下面是我理解的大体步骤
- 创建图
- 源op创建。即没有输出,但是有返回值。
- 计算op创建。用其他传递进来的tensor进行计算
- 创建过程中,预留输入用placeholder留占位符
- op自己的变量用tf.Variable
- 创建session(会话)
- 在session中启动图session.run()
使用完毕用session.close()关闭会话
给出隐式调用过程,方便以后自己使用。
with tf.Session() as sess: result = sess.run([product]) print resultFetch与Feed
在使用 Session 对象的 run() 调用 执行图时, 传入一些 tensor, 这些 tensor 会帮助你取回结果. 注意!run调用的是一个执行图,而图中tensor fetch到的结果。当需要获取的多个 tensor 值,在 op 的一次运行中一起获得。而feed类似于补丁形式,先以placeholder的形式给要输入的变量占位符,然后在run()的过程中给予feed_dict。可以临时替换到输入的tensor的结果,感觉可以起到调试的作用。然后每个feed进的数据只在调用它的方法内有效, 方法结束, feed 就会消失。
在正式实战之前,先深入了解几个概念。一直都在用,但是一直都没有深入的从数学角度理解。
Tensor and rank,shape,type
TensorFlow 程序使用 tensor 数据结构来代表所有的数据, 计算图中, 操作间传递的数据都是 tensor.张量的阶、形状、数据类型是很重要的概念。
张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述。一阶张量可以认为是一个向量.对于一个二阶张量你可以用语句t[i, j]来访问其中的任何元素.而对于三阶张量你可以用’t[i, j, k]’来访问其中的任何元素.



softmax回归
Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 y 可以取两个以上的值。对于给定的测试输入x,我们想用假设函数针对每一个类别j估算出概率值 p(y=j | x)。
假设函数: 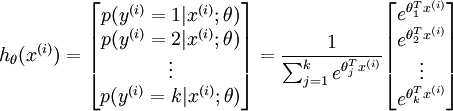
softmax函数需要输入输入的证据:

然后用softmax将证据转化为概率值,这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数:

之后正则化,保证输出的概率和为1:

给出图的形式:

交叉熵,相对熵
1.熵的本质是香农信息量(log(1/p) )的期望。
为什么信息量 是 log(1/p) 呢? 因为:一个事件结果的出现概率越低,对其编码的bit长度就越长。 以期在整个随机事件的无数次重复试验中,用最少的 bit 去记录整个实验历史。 即无法压缩的表达,代表了真正的信息量。
2.现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布。按照真实分布p来衡量识别一个样本的所需要的编码长度的期望(即平均编码长度)为:
因为用q来编码的样本来自分布p,所以期望H(p,q)中概率是p(i)。H(p,q)我们称之为“交叉熵”。
比如含有4个字母(A,B,C,D)的数据集中,真实分布p=(1/2, 1/2, 0, 0),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算H(p)为1,即只需要1位编码即可识别A和B。如果使用分布Q=(1/4, 1/4, 1/4, 1/4)来编码则得到H(p,q)=2,即需要2位编码来识别A和B(当然还有C和D,尽管C和D并不会出现,因为真实分布p中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。
可以看到上例中根据非真实分布q得到的平均编码长度H(p,q)大于根据真实分布p得到的平均编码长度H(p)。事实上,根据Gibbs’ inequality可知,H(p,q)>=H(p)恒成立,当q为真实分布p时取等号。我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为“相对熵”:D(p||q)=H(p,q)-H(p),其又被称为KL散度(Kullback–Leibler divergence,KLD) Kullback–Leibler divergence。它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。注意,KL散度的非对称性。
*交叉熵:编码方案不一定完美时,平均编码长度的是多少
H(p,q) = 信息熵(entropy) + 相对熵(DL散度)*
作用:交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
参考知乎高票答案
下面给出MINST入门全部代码,跑下来在0.91左右,input_data去TensorFlow里下载。
import tensorflow as tfimport input_data#data readmnist = input_data.read_data_sets("MNIST_data/", one_hot=True)#build modelx = tf.placeholder("float", [None, 784])W = tf.Variable(tf.zeros([784,10]))b = tf.Variable(tf.zeros([10]))y = tf.nn.softmax(tf.matmul(x,W) + b)#model paramsy_ = tf.placeholder("float", [None,10])cross_entropy = -tf.reduce_sum(y_*tf.log(y))train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)#init all variablesinit = tf.initialize_all_variables()#build sessionsess = tf.Session()sess.run(init)#batch trainfor i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})#evaluate model and print accuracycorrect_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})- [TensorFlow]修炼tfboy入门学习笔记-1
- TensorFlow学习笔记1:入门
- TensorFlow学习笔记1:入门
- tensorflow入门学习笔记
- Tensorflow入门学习笔记
- Tensorflow入门学习笔记
- TensorFlow学习笔记:入门
- TensorFlow学习笔记(二):TensorFlow入门
- TensorFlow 学习笔记-入门篇
- tensorflow学习笔记【1】——入门 MINST
- TensorFlow学习笔记(1):最简单的入门程序
- Spark系列修炼---入门笔记1
- TensorFlow学习笔记-1
- TensorFlow学习笔记1
- Tensorflow学习笔记(1)
- TensorFlow学习笔记1
- TensorFlow学习笔记1
- tensorflow学习笔记1
- 20170412
- HTML5第五课时,背景图片
- 嵌入式编译器
- Java 多态
- 进程与线程
- [TensorFlow]修炼tfboy入门学习笔记-1
- 【CQOI2017】 bzoj4814 小Q的草稿
- Linux系统编程——生产者与消费者(二)
- C语言实现简单24点游戏
- HTML5第五课时,雪碧图的应用!!
- 将Mininet中host与外部虚拟机连接
- nyoj241 最长单调递增子序列二
- 动态规划练习一 09:移动路线
- Mybatis多表联结查询底层配置


