2017华为codecraft 《大视频时代布局》
来源:互联网 发布:mt4软件使用视频教程 编辑:程序博客网 时间:2024/05/16 10:25
2017华为codecraft 《大视频时代布局》
标签(空格分隔): 学习笔记
一名渣渣的参赛经历,这篇博文,我会把自己试探过的所有想法,写过的所有可行的代码贴上来(然而在竞争激烈的西北赛区,我并没能冲进64强,所以代码大家看看就行了,欢迎拍砖);
3.3 — 3.7
华为在3月3号在官网上正式发布的赛题(其实提前就已经泄题了,可是提前泄题对我这种渣渣并没有什么卵用,23333) 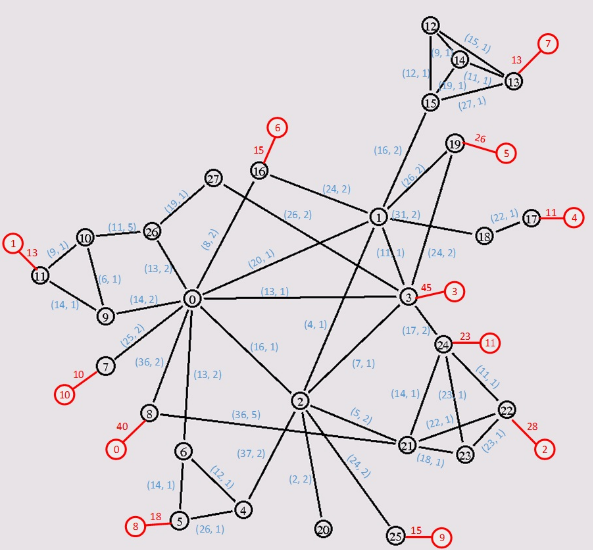
图中黑色的结点表示一些网络结点,表示可以在这些结点上建立提供输出的服务器,通过黑色的网络边来流向红色的结点,每条边上跑的流量不能超过该条边的容量,且边上的流量上下行互不影响。最终的设计方案需要在总花费最小的情况下满足图中所有消费结点(红色)的消费需求。
说一说我对题目本身的理解:服务器的个数,服务器的位置都是未知数,所以这是一个组合爆炸的问题。但是一旦服务器的位置个数确定,这个问题又可以转化为一个较为简单的多源多汇问题,目前多源多汇的较为主流的求解方法有规划方法(线性规划,整数规划),图论的方法(spfa求增广路)。
我一开始拿到这个问题感觉无从下手,但是由于我有比较熟悉线性规划和整数规划,所以初期的思路一致在往这上面靠。
3.7 — 3.15(前k条最短路 + 整数规划)
第一个解题思路已经形成: 该解题思路基于这样一个事实,假设服务器结点到消费结点有3条路径,那么最优解总是先走满代价最小的路径之后再走其他路径。 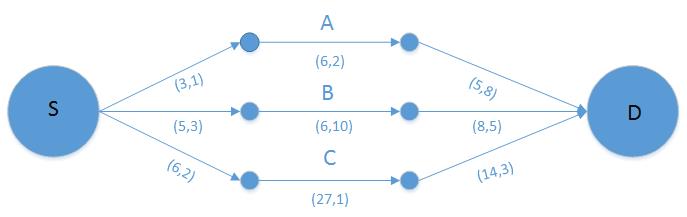
如上图所示,服务器结点S到消费结点D有3条路径,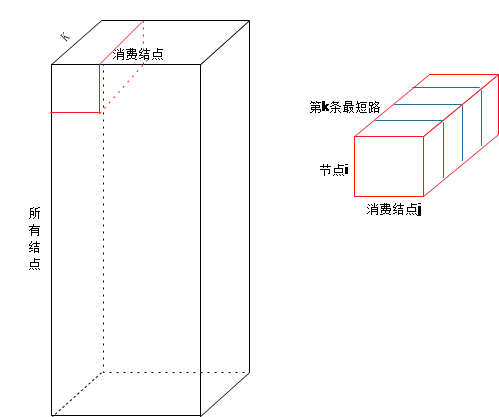
举一个具体的例子:50个结点,9个消费结点,上述的数据立方体k_path_cube中的k取5,即就是k_path_cube里面存储50个结点到9个消费结点的前5条最短路径。建立K_path_cube的时候,我们把每条路径存储起来,同时我们可以计算出每条路径的单位代价,记为
<=pathMaxFlow_{i,j,k} & & \ \sum_{i,j\in
edge_{i,j}}<=edgeCapcity_{i,j} & & \ \sum_i x_{i,j,k}*y_i =
consumerRequire_i & & \ \end{aligned} \right.
edge_{i,j}}<=edgeCapcity_{i,j} & & \\ \sum_i \sum_k x_{i,j,k} =
consumerRequire_j& & \\ \frac{\sum_i \sum_k x_{i,j,k}}{capacity_i}
<= y_i & & \ \end{aligned} \right
解释一下改变的第二个和第三个约束,第二个约束表示,流向第j个结点的所有路径上的流量总和要满足第j个结点的消费需求;第三个约束表示,只要有流量从第i个结点流出,那么第i个结点上就需要建立一个服务器。
约束方程写好,我们先用了线性规划的一个常用库lp_solver进行求解。
总结来说,我们的第一个基于整数规划的数学模型已经建立完成,所有的初级case(50个结点,9个消费结点)都在1000ms左右求除了全局最优解。
此时由于还没有放出高级case,我们还没评估整数规划模型对大规模case的求解情况,我们把优化目标转向了k_path_cube上,当网络结构变得复杂的时候,k_path_cube的建立是一个相当费时的过程,而k值估计要取到10-20之间才能包含全局最优解。先不说其他,50个结点,9个消费结点,求取前5条最短路径,那么这个整数规划的模型就有2250个未知数,这对于阶乘复杂度的整数规划来说,一旦数据量增加,求解时间将无限上升。果然,我们用上述模型求解了一个400点的网络,在程序运行3小时后,我们直接放弃了第一条路—–整数规划。
3.15 — 3.21 (多源多汇 + 无约束整数优化)
第一个模型建立算是失败,究其原因是因为该模型未知数变量太多,数据量稍微增加,该模型的复杂度直线上升。为此,我们建立了第二个基于多源多汇的整数模型。多源多汇的思想:将图中的每一个结点通过一条带宽为无穷大,路径代价为0的边直接与每一个虚拟源节点相连,如果该源节点有流量流向相连的结点,那么源节点就必须建立服务器。这样未知数就从k_path直接减少到了
边数 + 两倍的结点数。对网络的约束也可以这样来写:
1)普通结点的约束:流入普通结点的流量 = 流出普通结点的流量
2)消费结点的约束:流入消费结点的流量 - 流出消费结点的流量 = 该消费结点的需求 3)对边的约束:任一条边上走过的流量 <=该条边的容量
4)网络的约束:从虚拟源节点流出的流量和 = 消费结点的总需求
根据上述4个约束条件,我还是先用整数规划进行了算法验证,所有初级case均在600ms以内求出了最优解。正如上文所提到的,我们并没有打算用整数规划的方法来求解复杂网络。通过查阅相关文献,我们发现整数规划可以转换为无约束的优化问题,
对于无约束问题的求解,常见的方法有梯度下降法以及各种启发式算法。但由于只有目标函数时凸函数的情况下,梯度下降法才能取得最优解,并且优化目标里包含了这一函数:
3.21 — 4.3 (遗传算法 + 最小费用最大流)
上述两个模型的失败,有一个很重要的原因,即就是未知数维度一直没能下降太多,导致最优解搜寻的时候解空间的范围太大,且无论是模型一以路径为变量还是模型二以网络的边为变量,他们的取值范围相对来说还比较大,加之局部最优解太多,导致了启发式算法收敛太慢甚至不收敛。
我们建立的最后一个数学模型从根本上缩减了未知数的维度,以结点为未知数,则每个结点上存在着建立或者不建立服务器,对应的是该点的取值为{0,1},对于这种天然0,1编码的未知数来说,我们想到了遗传算法。用遗传算法确定服务器的位置,一旦服务器位置确定,那么该问题就变成了一个典型的多源多汇问题。 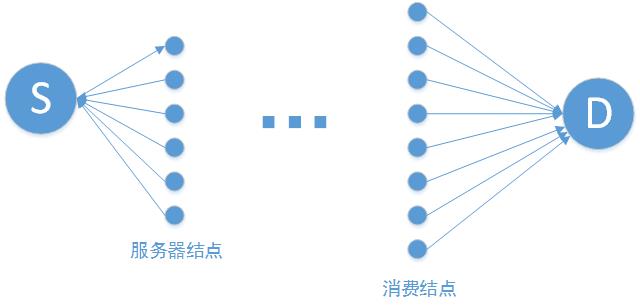
将所有服务器结点与一个超级源节点相连,其中边的带宽为无穷大,代价为0;再将所有消费结点与一个超级汇点相连,其中变得带宽为该消费结点的消费需求,代价为0。那么该多元多汇问题就转化为一个典型的单源单汇问题,而此问题可以通过构建一个最小费用最大流的模型,用spfa算法找增广路径进行求解(当用例图像过大,图较为稠密的时候,spfa算法可能效率上不如zkw算法)。
在说说我们用于遗传算法的技巧:
1)初始解的选取:启发式算法对初始解的选取特别敏感,好的初始解可以加快这类算法的收敛性。遗传算法的初始种群包含很多初始解。所以在我们初始解的选取原则有以下几条:a)直接将服务器放置在消费结点上;b)服务器大概率建在出度较大的点上
2)选择算子:我们采用的是赌轮盘选择算子
3)交叉算子:根据结点的规模采用双点交叉算子(经测试,双点交叉算子的稳定性优于单点交叉算子)。
4)变异算子:3-opts变异算子,对种群中的某个解向量的3个连续位置进行3点变异(3个点有000,001,…,111等8种组合,3-opts变异算子将挑选8中组合当中的最优组合进行变异)。
5)适应度函数:适应度函数和遗传算法的收敛性关联最大,适应度函数的取值范围为[0,1],代表着种群中该个体的适应能力。即就是适应度函数越大,该种群存活的概率越大,所以适应度函数的斜率决定着遗传算法的收敛性,斜率越高,收敛越快,但是过高会陷入局部最优解。结合适应度函数的这些特性,我们创新性的提出了改进的sigmoid函数作为适应度函数
前期的适应度函数为
基于这样的算法框架,我们试了试初级case(50个结点),所有case在50ms内收敛到了全局最优解,当时还有点小兴奋呢。
无奈自己搞的最小费用最大流不够优,导致大case的时候,迭代次数太少,总是还没收敛就到时间了。最终页没能进前64(西北赛区竞争太大了)。
本文中的三个版本的代码,我将在随后整理贴出来,欢迎拍砖呀。
说一说比赛的感想:实验室催活也比较紧,只能利用周末来搞这个,干些队友们和我一起讨论各种算法,做各种尝试。最为一个渣渣感觉这次参赛无论是从算法还是代码力上,都有一定的提升。
下面贴出三个版本的代码: 链接:http://pan.baidu.com/s/1hszHx4K 密码:m8ms
- 2017华为codecraft 《大视频时代布局》
- 2017华为CodeCraft回顾
- 华为codecraft算法大赛---寻路
- 华为日本设立研发中心,4大“X实验室”布局5G+物联网时代
- 2017codecraft错误总结
- 大数据时代的网络视频营销
- 布局大数据时代,电商如何取势DSP?
- 新华社评论员:用好大数据 布局新时代
- 新华社评论员:用好大数据 布局新时代
- 大数据时代给视频监控带来的革新
- 安防如何迎接视频大数据时代挑战?
- 赢在大视频时代:基于U-vMOS的视频承载网
- HTML5<video>背景大视频响应式布局完美支持
- 视频时代的反思
- 从三大互联网巨头布局,看移动时代的商业逻辑
- 大屏时代的生态变迁,看平板手机的拇指热键与界面布局
- 大屏时代的生态变迁_看平板手机的拇指热键与界面布局
- 大视频时代,网络电视台建设运营思路&技术基础架构建议
- Machine Learning逻辑回归(Logistic Regression)
- 黑客与画家摘录
- 主存到Cache直接映射、全相联映射和组相联映射
- Hive调用Java类ReflectUDF
- HOG特征
- 2017华为codecraft 《大视频时代布局》
- 题目1096:日期差值
- Tone mapping进化论
- fopen、fwrite、fread 函数——读写结构体类型数据详解
- Visual Stdio中的断点
- 题目1097:取中值
- Maven 使用profile来区分开发、测试、生产环境
- HTML常用标签使用(二)
- JAVA求学之路第十九天(多线程)


