UFLDL阅读笔记1—Multi-Layer Neural Network
来源:互联网 发布:动漫死神知乎 编辑:程序博客网 时间:2024/05/21 14:08
背景
问题
有一组数据形式为
单个神经元
- 示意图
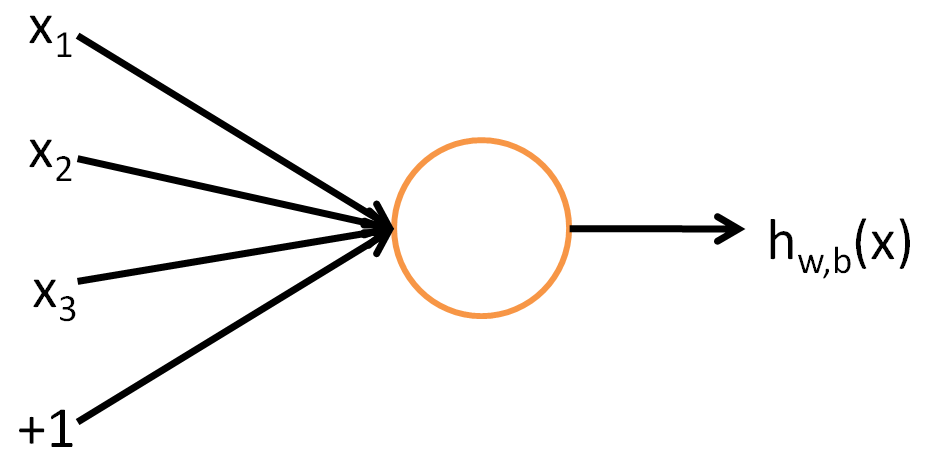
- 实质
先把输入向量x 的各个分量进行线性组合加一个偏移成为∑ni=1Wixi+b ,再将这个结果通过activation functionf ,就会得到单个神经元的输出hW,b(x) - activation function
常见的activation function有3种类型:- sigmoid
f(z)=11+exp(−z) - tanh
f(z)=tanh(z)=ez−e−zez+e−z - rectified linear
f(z)=max(0,x)
- sigmoid
3个函数的图像如下: 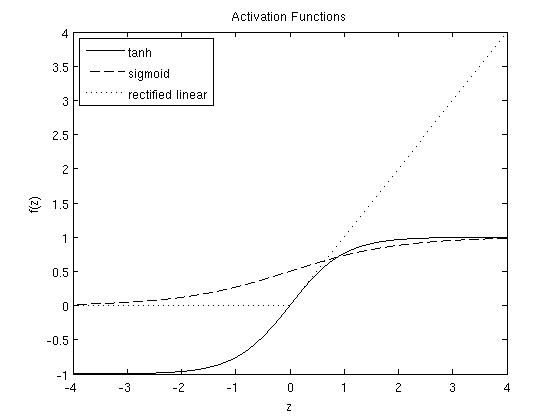
Neural Network model
定义
单个神经元结构分层全链接。其中,最左边为input layer,最右边是output layer ,中间是hidden layer ,层内标注为“+1”的节点表示的是一个偏移量,叫做bias units 。以下是一个简单的神经网络模型
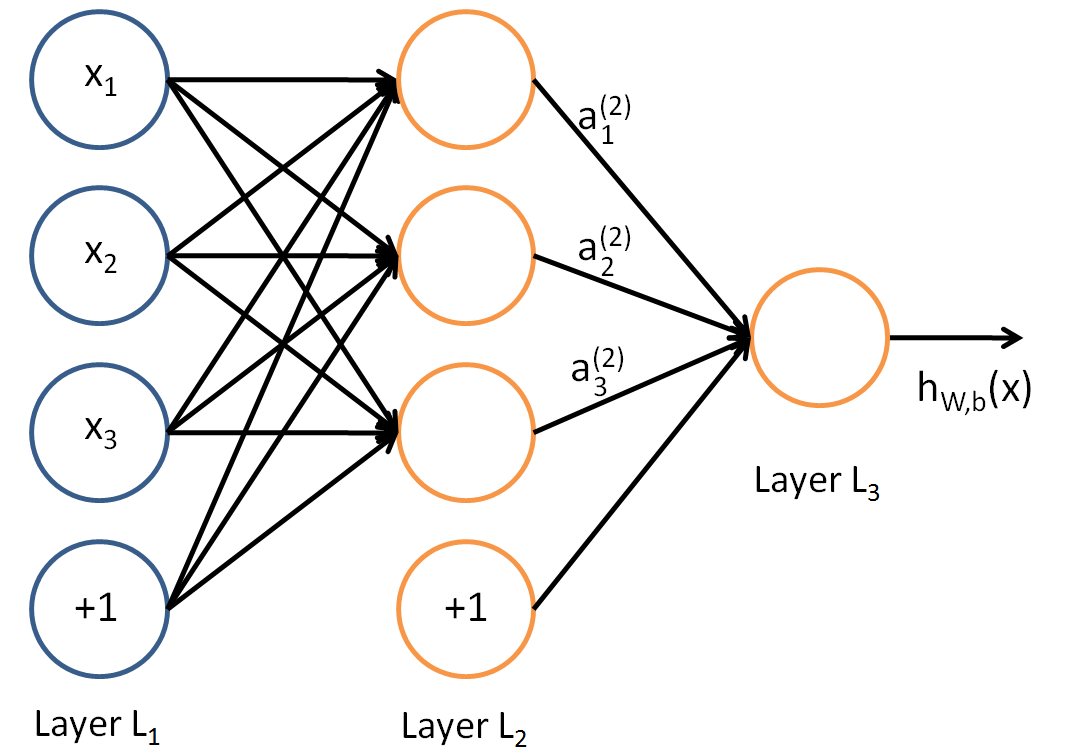
参数说明
其实任意两个节点之间的连接线上都对应了一个参数,每层都是上一层的线性组合作为输入传到下一层,因此每层配有各自的
- 对于每两层之间的
- 对于每两层之间的
从以上的参数分析我们可以得出,
forward propagation表达式
容易看出,把以上形式简写成矩阵形式即为:
这里的参数
以上是一个简单的神经网络的前向传播过程。事实上,一个神经网络的架构中,隐含层可以有很多层,输出层也可以有不止一个节点。
Backpropagation算法
cost function
对于一个测试用例,cost function代表网络输出值和真实值的平方误差的二分之一,用下面的式子表示:
对于所有的测试用例,cost function代表每一个用例的cost的平均+正则项(W中的每一个元素的和再乘正则系数)。表达式如下:
说明:
1. 正则项的作用是约束W不要太大(因为优化的目标就是让J尽可能小),防止过拟合的发生。
2. 用神经网络进行分类,若用的是sigmoid神经元,标签应该采用(0, 1);若采用tanh神经元,标签应采用(-1,1)
3. 用神经网络进行拟合,应在保证输出在[0,1](sigmoid),或-1,1
0 0
- UFLDL阅读笔记1—Multi-Layer Neural Network
- UFLDL学习笔记4——Multi-Layer Neural Network
- ufldl学习笔记与编程作业:Multi-Layer Neural Network(多层神经网络+识别手写体编程)
- Multi-Layer Neural Network
- Multi-Task Convolutional Neural Network for Face Recognition阅读笔记
- Principles of training multi-layer neural network using backpropagation
- Principles of training multi-layer neural network using backpropagation
- Principles of training multi-layer neural network using backpropagation
- UFLDL Exercise: Convolutional Neural Network
- ufldl学习笔记与编程作业:Convolutional Neural Network(卷积神经网络)
- cs231n:assignment1——Q4: Two-Layer Neural Network
- 论文阅读笔记(一)——Deep Convolutional Neural Network with Independent
- Distilling the Knowledge in a Neural Network 阅读笔记
- 深度学习笔记(1)——神经网络(neural network)
- 机器学习笔记——Neural Network
- Neural Network 笔记
- 神经网络笔记(Neural Network)
- cs231n neural network 笔记
- 【BZOJ 1856】【SCOI 2010】字符串
- jxls导入excel
- linux之间共享目录挂载
- android静态广播添加权限
- quartz集成spring集群部署
- UFLDL阅读笔记1—Multi-Layer Neural Network
- docker 学习笔记---如何将docker 镜像上传到docker hub仓库
- iOS 照片人脸识别
- quartz执行卡死--强制中断线程
- 基于druid和spring的动态数据库以及读写分离
- postgre 第一次登录
- opencv-3-computer-vision-application-programming-cookbook-third-edition.pdf
- apache FTPClient返回当前目录的路径
- 最大化对数似然函数——牛顿方法(The Newton's method)


