什么是序列化
来源:互联网 发布:网络视频下载神器 编辑:程序博客网 时间:2024/05/21 08:49
为什么要序列化一个对象,大概出于两个目的。
第一保存对象以便以后再处理,这是出于对象持久化(persist)的要求。这种情况一般需要把对象保存到可以长久保存的介质上,比如磁盘。保存在磁盘上的数据是一系列连续的字节组成的,所以就需要把对象转换成一个连续的字节串以便把对象写入到磁盘。把一个对象当时的完整状态转换成连续的字节串的过程就是对象的序列化(serialize)过程。反过来把表示一个对象的连续的字节串复原成原来的那个对象的过程就是反序列化(deserialize)过程。
第二,自从有了分布式处理技术后,就出现了需要从一个应用传送一个对象到另一个应用的需求。不同的应用大多数情况是不在同一个机器上的,对象需要在网络上进行传输。跟写入到磁盘类似,网络传输数据也可以看做是传输一个连续的字节串。这种需求同样需要把对象先序列化成连续的字节串,经过网络传输到,到达目标应用,再经过反序列化恢复为对象。
Dotnet framework中针对不同的应用场景提供了几类不同的序列化器,主要有三大类,分别是针对不同的技术提供的。
下面分别介绍三大类一个5个序列化器,每个序列化器都是用一个简单的示例说明把一个对象序列化到一个流,然后再从流反序列化为这个对象。
完整的代码(解决方案中包含了本文的所有示例项目)下载地址:DotnetSerialize.rar
二、 为remoting提供的BinaryFormatter和SoapFormatter
这两个序列化器都是由System.Runtime.Remoting.Messaging. IRemotingFormatter接口派生。
这两个序列化器是为remoting准备的,remoting是微软在dotnet中提供的应用程序间远程访问的技术,用以替代com+的技术,在通讯通道方面,remoting既支持tcp,也支持http协议,这样就解决防火墙的限制问题。
Remoting技术考虑进行远程访问的双方都是基于dotnet技术的应用,没有太多的考虑使用更通用的业界标准,所以这两个序列化器带有强烈的dotnet的自身特点。
1、 BinaryFormatter和SoapFormatter两个主要特点
1.1. 序列化数据中包含类型信息
对象序列化后的数据中包含类型信息:类的全限定名、版本、区域、KeyToken,所以反序列化时必须制定同一类型,即类的全限定名、版本、区域、KeyToken必须一致,否则会被认为不是同一类型的对象。
1.2. 具有类型保真(type fidelity)的特性
所有的field都将被序列化(包括私有字段),但是不包括属性(属性只是访问器,本身不保存数据),除非field被标记[NonSerialized]属性。
这样序列化后的数据,再被反序列化回对象,将严格的跟原来的对象一模一样。
2、 SoapFormatter
SoapFormatter序列化器把对象序列化为SOAP形式的xml字符串序列,xml形式便于通过HTTP协议在网络上传输,所以remoting在使用HTTP协议时就采用SoapFormatter序列化器序列化对象。
SoapFormatter所在名称空间和所在assembly:
Namespace: System.Runtime.Serialization.Formatters.Soap
Assembly: system.runtime.serialization.formatters.soap.dll
SoapFormatter序列化器序列化的对象必须是被标记为[Serializable]属性的类。
2.1. 准备需要序列化的类
代码很简单,不需要多加说明,有几点需要强调:
l 类必须被[Serializable]属性标记,否则SoapFormatter序列化器序列化时会抛出异常
l 默认类的所有field,不管是公有还是私用的field都会被序列化,以保证类型保真性。除非把某个field标记[NonSerialized]属性。
///
/// 需要被序列化的类
///
[Serializable]
public class book
{
//私有field将被序列化
private string name;
//构造方法将把下面两个address字段将指向同一个对象
private string address1;
private string address2;
//标识为[NonSerialized]的私有field将被序列化
[NonSerialized]
private string address_invisible = "shenzhen";
//公有field将被序列化
public string author;
//属性只是访问器,不被序列化
public string Name
{
get { return name; }
set { name = value; }
}
public book()
{
string address = "shenzhen";
address1 = address;
address2 = address;
}
}
2.2. 准备需要序列化的对象和流
序列化时针对对象而言的,是把一个对象的当时的状态完整的转换成连续的字节串。
序列化的源是一个[Serializable]属性类的一个实例对象。
序列化的目标是一个Stream对象,或者是文件流,或者是内存流等等。
所以这一步将要准备需要被序列化的对象和序列化后的目标,一个内存流。
///
/// 声明一个流对象,用来保存序列化后的对象
///
private static MemoryStream myMemoryStream;
///
/// 需要序列化的对象
///
private static book mybook;
#region 准备需要序列化的对象
mybook = new book();
mybook.Name = "我的第一本书";
mybook.author = "chnking";
#endregion
//准备保存序列化后对象的流
myMemoryStream = new MemoryStream();
2.3. 将准备好的对象序列化到准备好的流对象中
使用SoapFormatter对象的Serialize方法进行序列化:
SoapFormatter.Serialize (Stream, Object)
Object 参数是需要被序列化的对象。
Stream是保存序列化后数据的流对象。
这里有几点需要特别强调的:
l SoapFormatter把对象转换成xml后,从xml到Stream过程默认采用UTF-8编码,而且好像无法改变这个编码。所以,要从Stream转换成字符串需要使用UTF-8进行解码。
l Serialize方法把对象序列化到Stream对象后,Stream的当前位置在最后,使用 Stream的Read方式读取流中数据注时意把Stream当前位置复位到起始位置。
///
/// 将准备好的对象序列化到准备好的流对象中
///
static void Serialize()
{
//准备序列化器SoapFormatter
SoapFormatter formatter = new SoapFormatter();
//序列化mybook对象,序列化到myMemoryStream流对象
formatter.Serialize(myMemoryStream, mybook);
#region 将流中的数据转换为字符串或xmlDocument
byte[] resultByte = myMemoryStream.GetBuffer();
string resultStr = Encoding.UTF8.GetString(resultByte);
//转成xmlDocument对象方便在断点调试时查看结果
XmlDocument myXmlDocument = new XmlDocument();
myXmlDocument.LoadXml(resultStr);
#endregion
}
2.4. 查看序列化的结果
前面的代码把对象序列化后保存数据的MemoryStream中的数据转换成字符串,然后读入到一个XmlDocument中以方便查看,看一下结果

可以看出以下几点:
l 包含对象的完整的类型信息,包括类的类名、名称空间、版本号、区域、KeyToken,甚至还有所在Assembly的名称,参看上图中的标识。
l 只有field被序列化,不管是私有的还是公有的,除非这个字段被标记[NonSerialized]属性,本例中address_invisible字段就被标记为[NonSerialized],序列化后的结果能看到,address_invisible没有被序列化。
l 对象中几个字段为同一个对象时,在序列化后,只有一个副本,其它的字段指向这个副本。本例中address1字段和address2字段被赋给了同一个字符串对象,在序列化后,address1字段保留了一个副本,address2字段通过引用address1的id来引用这个副本。
2.5. 将流对象中数据反序列化为对象
使用SoapFormatter对象的Deserialize方法进行反序列化
反序列化比较简单,把前面步骤生成的保存序列化后的对象的流直接使用Deserialize方法
///
/// 将Serialize方法序列化到流中的数据反序列化为对象
///
static void Deserialize()
{
myMemoryStream.Position = 0;
SoapFormatter formatter = new SoapFormatter();
mybook = (book)formatter.Deserialize(myMemoryStream);
}
看一下反序列化后得到的对象的状态:

除了被标记为[NonSerialized]的address_invisible字段,这个字段没有被序列化,当然反序列化后的这个字段的值就被丢了,别的字段的状态都被恢复了。
3、 BinaryFormatter
BinaryFormatter序列化器把对象序列化为二进制格式的数据,这样的数据格式最精简、效率最高,但也最不具交互性,适合在局域网内用TCP协议传输,所以remoting在使用TCP协议时就采用BinaryFormatter序列化器序列化对象。
BinaryFormatter在功能上跟SoapFormatter想对应,只是SoapFormatter把对象序列化为Soap形式,BinaryFormatter把对象序列化二进制形式。还有点不同是,SoapFormatter在序列化对象是可以在对象之外增加一些附加信息放入到soap的head部分。
BinaryFormatter所在名称空间和所在assembly:
Namespace: System.Runtime.Serialization.Formatters.Binary
Assembly: mscorlib.dll
同样BinaryFormatter序列化器序列化的对象必须是被标记为[Serializable]属性的类。
下面的示例还是处理前面SoapFormatter同样的例子,只是把SoapFormatter换成BinaryFormatter看看是什么样的结果。
准备需要序列化的类和对象,准备序列化的目标流步骤跟前面SoapFormatter的例一摸一样,参看前面的例子。
3.1. 将准备好的对象序列化到准备好的流对象中
使用BinaryFormatter对象的Serialize方法进行序列化:
BinaryFormatter.Serialize (Stream, Object)
这里有几点需要特别强调的:
BinaryFormatter把对象转换成二进制的序列数据,其中总不免会有字符存在,比如字符串类型的字段,对字符同样在序列化过程默认采用UTF-8编码,而且好像无法改变这个编码。
///
/// 将准备好的对象序列化到准备好的流对象中
///
static void Serialize()
{
//准备序列化器BinaryFormatter
BinaryFormatter formatter = new BinaryFormatter();
//序列化mybook对象,序列化到myMemoryStream流对象
formatter.Serialize(myMemoryStream, mybook);
#region 将流中的数据转换为字符串
byte[] resultByte = myMemoryStream.GetBuffer();
string resultStr = Encoding.UTF8.GetString(resultByte);
#endregion
}
3.2. 查看序列化的结果
序列化的流主要是二进制的数据,不过里面也会夹杂的字符,所以还是使用UTF-8编码把流转成字符串查看。
结果是这样的:
/0/0/0/0????/0/0/0/0/0/0/0/f[1]/0/0/0FBinaryFormatter, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null/0/0/0&Serialize.BinaryFormatterTest.App+book /0/0/0
name/baddress1/baddress2author[1]/0/0/0
/0/0/0我的第一本书
/0/0/0/bshenzhen/t
/0/0/0/0/0/0/achnking/v/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0
里面乱码部分是二进制的数据,没法看。不过里面的字符还是可以看出些东西来。
“BinaryFormatter, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null”,这部分是对象的类型的Assembly、版本、区域、KeyToken信息。
“Serialize.BinaryFormatterTest”,这是类所在的名称空间。
“book”,是类型名。
还有其他的field名和他们相关的值,标记为[NonSerialized]的address_invisible字段不会被序列化,所以在这个结果里也没有出现。
3.3. 将流对象中数据反序列化为对象
使用BinaryFormatter对象的Deserialize方法进行反序列化。
跟SoapFormatter一样进行反序列化。
///
/// 将Serialize方法序列化到流中的数据反序列化为对象
///
static void Deserialize()
{
myMemoryStream.Position = 0;
BinaryFormatter formatter = new BinaryFormatter();
mybook = (book)formatter.Deserialize(myMemoryStream);
}
反序列化后得到的对象跟SoapFormatter反序列化的结果一样。
三、 XmlSerializer
XmlSerializer是ASP.NET Web Services使用的序列化器。
Web Services有一系列的业界标准,不只是微软自己的标准, web servces可能跟异构的系统交互,所以,Web Services序列化后的数据只包括对象包含的公有数据,不会包含dotnet的类型信息。
XmlSerializer只转换公共字段和属性,不转换方法、索引、私有字段、只读属性(只读集合除外),XmlSerializer生成的xml的格式受类成员的属性控制,这些属性可以指定类转换成xml后的根节点名称,名称空间,类成员是作为属性形式还是作为节点形式出现等等。
序列化后的数据不包含类型和assembly的信息。
所以XmlSerializer化后得到的xml不是保真的序列化,它只是把对象的一部分公开的数据序列化了,反序列化得到的对象跟原来的对象可能就有些不同了。
建立需要通过XmlSerializer序列化的.net类的两种方式:
l 把一般的.net的自定义类型通过添加相应控制xml序列化的属性来建立序列化的类
l 通过工具把现有xml架构生成带有相关属性的.net类,这样的类的对象序列化后将符合这个架构。当希望序列化后的内容遵从某个已知架构时可以使用这种方式构建类。
XmlSerializer所在名称空间和所在assembly:
Namespace: System.Xml.Serialization
Assembly: system.xml.dll
1、 使用自定义.net类型的序列化
1.1. 定义需要用XmlSerializer序列化的.net类型
自定义个类,这个类要可以通过XmlSerializer序列化器序列化为xml,并且能够根据实际需要控制序列化后的xml的格式。
首先,这个类不需要[Serializable]属性。
其次,用一些Attribute来控制类或类成员如何生成xml。
下面是主要的几个Attribute的作用:
1.1.1. XmlRootAttribute
这个属性必须放在类的前面用来限定需要序列化的类。
[XmlRootAttribute("BOOK", Namespace="http://www.chnking.com", IsNullable = false)]
public class book
{
//定义类代码
}
属性的第一个参数 ElementName = “BOOK” ,表示序列化后的xml的根元素是BOOK,缺省的话,根元素名就是类名。
参数Namespace,表示根元素的名称空间,这个名称空间是根元素的默认名称空间,表现为:xmlns=”http://www.chnking.com” 这样的形式。
参数IsNullable,值为true时表示如果这个对象实例为Null,生成的xml在根元素的用属性xsi:nil="true"表示。
1.1.2. XmlAttribute
此属性放在类的公有字段和可读写属性前,表示这个字段或属性在xml中以element的属性形式出现。
[XmlAttribute("Author", Namespace = "http://www.chnkingAttr.com",DataType = "NMTOKEN")]
public string author;
属性的第一个参数AttributeName = "Author",表示这个成员被序列化为Attribute的属性名。
参数Namespace,表示根元素的名称空间,这个名称空间只是这个属性名称空间。
参数DataType,表示这个成员转换为xml的XML Schema类型。一般的,很多XML Schema类型,比如int 、decimal,在.net framework都有相应的数据类型相对应,但也有很多XML Schema类型类型在.net framework中没有,就可以通过[XmlAttribute]的DataType参数来指示转成xml后的XML Schema数据类型。上面的DataType = "NMTOKEN",表示要把.net framework中的string类型转换到XML Schema中的NMTOKEN数据类型。根据W3C XML Schema 中数据类型的定义,NMTOKEN类型中只能包含数字、字母、下划线、冒号,如果不在此范围内的字符都以十六进制的ASCII码表示。比如,如果字符串“^chnking”中包含了NMTOKEN类型不允许出现的^字符,所以这个字符串转成xml后会变成这样:"_x005E_chnking",x005E是字符^的ASCII码。
1.1.3. XmlElementAttribute
此属性放在类的公有字段和可读写属性前,表示这个字段或属性在xml中以element形式出现。这是XmlSerializer序列化器的默认行为,如果这个公有字段或可读写属性前没有相关Attribute约束,那这个公有字段或可读写属性在序列化后的xml中就以element形式出现。
但是[XmlElementAttribute]还是可以为控制序列化的xml提供更多的控制。
[XmlElementAttribute(ElementName = "NamePro", Namespace = "http://www.chnkingName.com", DataType = "NMTOKEN",IsNullable = true)]
public string Name
{
get { return name; }
set { name = value; }
}
属性的第一个参数ElementName = "NamePro",表示这个成员被序列化后element的名称。
第二和第三个参数Namespace和DataType跟上面[XmlAttribute]含义一样。
第四个参数IsNullable = true,这个属性描述相关公有字段或可读写属性的值为null时生成xml的行为。
如果这个属性的值为true,相应的element依然会在序列化后的xml中出现,只是没有值,在element中会有一个xsi:nil="true"属性,表示此元素为null值,比如:
<NamePro xsi:nil="true" xmlns="http://www.chnkingName.com" />
如果这个属性的值为false,相应的element将不会在序列化后的xml中出现。
下面是准备需要序列化的类,跟前面两个BinaryFormatter和SoapFormatter中的例子基本上一样。只是改成了适合XmlSerializer的样子:
[XmlRootAttribute(ElementName = "BOOK", Namespace = "http://www.chnking.com", IsNullable = true)]
public class book
{
//私有field将不被序列化
private string name;
//构造方法将把下面两个address字段将指向同一个对象
public string address1;
public string address2;
//[XmlAttribute]属性将指示把类的成员序列化为一个element的属性
[XmlAttribute(AttributeName = "Author", Namespace = "http://www.chnkingAttr.com", DataType = "NMTOKEN")]
public string author;
[XmlElementAttribute(ElementName = "NamePro", Namespace = "http://www.chnkingName.com", DataType = "NMTOKEN", IsNullable = true)]
public string Name
{
get { return name; }
set { name = value; }
}
public book()
{
string address = "shenzhen";
address1 = address;
address2 = address;
}
}
1.2. 准备需要序列化的对象和流
这部分跟BinaryFormatter和SoapFormatter中的例子一样。
不过这里mybook.author属性的值为"^chnking",里面的^符号是author属性被限定为xml的NMTOKEN类型不允许的字符,注意在转换为xml后如何转换这个字符的。
///
/// 声明一个流对象,用来保存序列化后的对象
///
private static MemoryStream myMemoryStream;
///
/// 需要序列化的对象
///
private static book mybook;
mybook = new book();
mybook.Name = "我的第一本书";
mybook.author = "^chnking";
//准备保存序列化后对象的流
myMemoryStream = new MemoryStream();
1.3. 将准备好的对象序列化到准备好的流对象中
跟BinaryFormatter和SoapFormatter不一样,这两个序列化器都有缺省构造函数,XmlSerializer构造函数必须要提供序列化对象的类型参数。
同样也是使用Serialize方法把需要序列化的对象序列化到一个流中。
跟SoapFormatter类似,XmlSerializer把对象转换成xml后,从xml到Stream过程默认采用UTF-8编码,而且好像无法改变这个编码。所以,要从Stream转换成字符串需要使用UTF-8进行解码。
static void Serialize()
{
//准备序列化器XmlSerializer
XmlSerializer formatter = new XmlSerializer(typeof(book));
//序列化mybook对象,序列化到myMemoryStream流对象
formatter.Serialize(myMemoryStream, mybook);
#region 将流中的数据转换为字符串或xmlDocument
byte[] resultByte = myMemoryStream.GetBuffer();
string resultStr = Encoding.UTF8.GetString(resultByte);
//转成xmlDocument对象方便在断点调试时查看结果
XmlDocument myXmlDocument = new XmlDocument();
myXmlDocument.LoadXml(resultStr);
#endregion
}
1.4. 查看序列化的结果
前面的代码把对象序列化后保存数据的MemoryStream中的数据转换成字符串,然后读入到一个XmlDocument中以方便查看,看一下结果:

这个结果里面有几点需要注意:
l 类中Author共有字段标识了XmlAttribute属性,,所以它在xml中表现为根元素的一个属性,同时它的值为"^chnking",是NMTOKEN类型,所以字符^被转换成^字符十六进制的ACSII码X005E。
l 公有字段address1和address2是指向同一个对象,跟在BinaryFormatter中address2使用id引用到address1不同,这里这两个字段都被赋给了同一个值。这是因为BinaryFormatter是基于对象的,在序列化成xml依然要体现对象的特性,要反映出序列化前的对象引用关系,而XmlSerializer是面向数据的,它只关心最后形成的数据,所以它不必一定要保留对象直接的引用关系,直接都给他们赋予同一个值。
1.5. 将流对象中数据反序列化为对象
使用XmlSerializer对象的Deserialize方法进行反序列化。
static void Deserialize()
{
myMemoryStream.Position = 0;
XmlSerializer formatter = new XmlSerializer(typeof(book));
mybook = (book)formatter.Deserialize(myMemoryStream);
}
查看反序列化后的对象:

1.6. 测试在web services中序列化对象是否跟XmlSerializer一致
前面讲过,XmlSerializer是dotnet中用于web services序列化对象的序列化器,所以这里就来测试一下在web services中使用前面的那个示例中我们自己用XmlSerializer序列化的对象,看看得到的序列化的结果是不是完全一样。
在解决方案中新建一个web services的项目,引用前面XmlSerializer的项目,为了使用项目中定义的需要序列化的那个book类。
Web services的代码很简单:
[WebService(Namespace = "http://chnking.com/")]
[WebServiceBinding(ConformsTo = WsiProfiles.BasicProfile1_1)]
public class BookService : System.Web.Services.WebService
{
[WebMethod]
public book GetBook()
{
book mybook = new book();
mybook.Name = "我的第一本书";
mybook.author = "^chnking";
return mybook;
}
}
在浏览器中直接浏览这个web services,测试GetBook方法,得到的结果是:
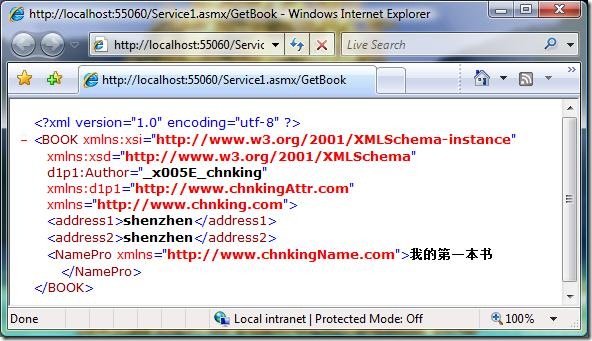
跟前面XmlSerializer例子得到的序列化的结果比较一下,一模一样。
2、 使用工具把现有xml架构转换成.net类
在XmlSerializer这一节的开头我们谈到过,有两种方法建立需要序列化的类。
上面的例子是第一种方式:通过自己写代码定义.net类,然后通过给类成员加上各种Attribute来控制序列化后的xml形式。
还有一种方式是根据给定的xsd 架构文件生成一个.net类,然后这个类序列化后的xml是符合xsd的架构的。
这种方式适合于,在交换数据的双方事先约定了一个交换数据的格式,即先定义了一个schema,双方交换的数据都必须遵从这个schema的情况。
2.1. 准备xsd架构文件
还是使用上面的自定义.net的例子数据,根据上面例子序列化后的xml,建立这个xml对应的schema,既前面的xml数据遵从这个schema。
由于xml中Author属性有自己的名称空间,NamePro元素也有自己的名称空间,所以这两个成员需要在单独的schema中定义,所以这个xml一共需要三个schema来定义:
主xsd的内容,文件名test2.xsd,这里面会import Author属性和NamePro元素对应的两个xsd文件,同时把根元素BOOK改成BOOKxsd,生成BOOKxsd的.net类型,跟上个例子的book类型相区别:
xml version="1.0" encoding="utf-16"?>
<xsd:schema xmlns:d1p1="http://www.chnkingAttr.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsd="http://www.w3.org/2001/XMLSchema" attributeFormDefault="unqualified" elementFormDefault="qualified" targetNamespace="http://www.chnking.com">
<xs:import schemaLocation="./test.xsd" namespace="http://www.chnkingAttr.com" />
<xs:import schemaLocation="./test1.xsd" namespace="http://www.chnkingName.com" />
<xs:element name="BOOKxsd">
<xs:complexType>
<xs:sequence>
<xs:element name="address1" type="xs:string" />
<xs:element name="address2" type="xs:string" />
<xs:element xmlns:q1="http://www.chnkingName.com" ref="q1:NamePro" />
xs:sequence>
<xs:attribute ref="d1p1:Author" use="required" />
xs:complexType>
xs:element>
xsd:schema>
Author属性的schema,文件名test1.xsd:
xml version="1.0" encoding="utf-16"?>
<xs:schema xmlns:tns="http://www.chnkingName.com" attributeFormDefault="unqualified" elementFormDefault="qualified" targetNamespace="http://www.chnkingName.com" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="NamePro" type="xs:string" />
xs:schema>
NamePro元素schema,文件名test.xsd:
xml version="1.0" encoding="utf-16"?>
<xs:schema xmlns:tns="http://www.chnkingAttr.com" attributeFormDefault="unqualified" elementFormDefault="qualified" targetNamespace="http://www.chnkingAttr.com" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:attribute name="Author" type="xs:string" />
xs:schema>
好了,schema文件都准备好了,使用工具验证一下这些schema生成的一个xml的实例:
<ns0:BOOK ns1:Author="d1p1:Author_0" xmlns:ns1="http://www.chnkingAttr.com" xmlns:ns0="http://www.chnking.com">
<ns0:address1>address1_0ns0:address1>
<ns0:address2>address2_0ns0:address2>
<ns2:NamePro xmlns:ns2="http://www.chnkingName.com">NamePro_0ns2:NamePro>
ns0:BOOK>
跟前面示例的xml的模样是一致的,说明这几个schema建立的没有问题。
2.2. 根据xsd生成.net类
微软提供了一个工具xsd.exe,它可以根据xsd架构文件,生成相应的.net类,而这个.net类使用XmlSerializer序列化后的xml又能遵从这个xsd架构。
使用下面的命令行生成.net类:
xsd test2.xsd test1.xsd test.xsd /c
命令会产生一个cs文件,里面包含了生成的.net类,这个类如下:
[System.CodeDom.Compiler.GeneratedCodeAttribute("xsd", "2.0.50727.42")]
[System.SerializableAttribute()]
[System.Diagnostics.DebuggerStepThroughAttribute()]
[System.ComponentModel.DesignerCategoryAttribute("code")]
[System.Xml.Serialization.XmlTypeAttribute(AnonymousType=true, Namespace="http://www.chnking.com")]
[System.Xml.Serialization.XmlRootAttribute(Namespace="http://www.chnking.com", IsNullable=false)]
public partial class BOOKxsd {
private string address1Field;
private string address2Field;
private string nameProField;
private string authorField;
public string address1 {
get {
return this.address1Field;
}
set {
this.address1Field = value;
}
}
public string address2 {
get {
return this.address2Field;
}
set {
this.address2Field = value;
}
}
[System.Xml.Serialization.XmlElementAttribute(Namespace="http://www.chnkingName.com")]
public string NamePro {
get {
return this.nameProField;
}
set {
this.nameProField = value;
}
}
[System.Xml.Serialization.XmlAttributeAttribute(Form=System.Xml.Schema.XmlSchemaForm.Qualified, Namespace="http://www.chnkingAttr.com")]
public string Author {
get {
return this.authorField;
}
set {
this.authorField = value;
}
}
}
2.3. 序列化xsd生成的.net类
将xsd生成的.net类,放到前面例子里替代book类,然后序列化,看序列化后的结果:

可以跟前面使用自定义 .net类序列化后的xml对比一下,他们序列化后的xml结果是一样的。
- 什么是反射?什么是序列化
- 什么是序列化?
- 什么是序列化
- 什么是序列化
- 什么是序列化?
- 什么是序列化
- 什么是序列化
- 什么是序列化
- C# 什么是序列化
- 什么是序列化?
- 什么是java序列化
- 什么是java序列化
- .NET Framework 序列化 什么是序列化
- 什么是序列化,为什么要序列化?
- Serializable序列化以及什么是序列化
- 什么是序列化,为什么要序列化。
- 什么是序列化,为什么要序列化
- 什么是反射,什么序列化?
- 如何将汉语数字转换成阿拉伯数字!
- C#多线程学习(五) 多线程的自动管理(定时器)
- 什么是成功?
- js入门(三)
- ERP系统模块完全解析──主生产计划MPS
- 什么是序列化
- Oracle查看段信息show_space()
- Openvms QQ群: 主群11112300,副群135272460
- read the code read the soul
- 练习55
- linux下的截图工具
- submit 按钮提交无效 点击无效果 不可用
- ERP项目实施正式开始了
- 上学为了啥?大学生十宗罪


