READING NOTE: FastMask: Segment Multi-scale Object Candidates in One Shot
来源:互联网 发布:java高并发架构 编辑:程序博客网 时间:2024/06/06 02:57
TITLE: FastMask: Segment Multi-scale Object Candidates in One Shot
AUTHOR: Hexiang Hu, Shiyi Lan, Yuning Jiang, Zhimin Cao, Fei Sha
ASSOCIATION: UCLA, Fudan University, Megvii Inc.
FROM: arXiv:1703.03872
CONTRIBUTIONS
- A novel weight-shared residual neck module is proposed to zoom out feature maps of CNN while preserving calibrated feature semantics, which enables efficient multi-scale training and inference.
- A novel scale-tolerant head module is proposed which takes advantage of attention model and significantly reduces the impact of background noises caused by unmatched receptive fields.
- A framework capable for one-shot segment proposal is made up, namely FastMask. The proposed framework achieves the the state-of-the-art results in accuracy while running in near real time on MS COCO benchmark.
METHOD
Network Architecture
The network architecture is illustrated in the following figure.

With the base feature map, a shared neck module is applied recursively to build feature maps with different scales. These feature maps are then fed to a one-by-one convolution to reduce their feature dimensionality. Then we extract dense sliding windows from those feature maps and do a batch normalization across all windows to calibrate and redistribute window feature maps. With a feature map downscaled by factor
Residual Neck
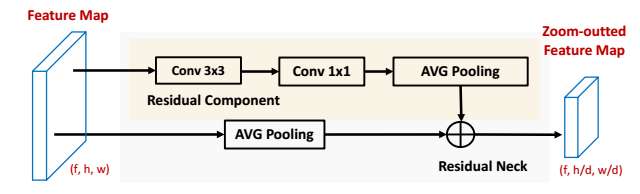
The neck module is actually used to downscale the feature maps so that features with different scales can be extracted.
There are another two choices. One is Max pooling neck, which produces uncalibrated feature in encoding pushing the mean of downscaled feature higher than original. The other one is Average pooling neck, which smoothes out discriminative feature during encoding, making the top feature maps appear to be blurry.
Residual neck is then proposed to learn parametric necks that preserve feature semantics. The following figure illustrates the method.
Attentional Head
Given the feature map of a sliding window as the input, a spatial attention is generated through a fully connected layer, which takes the entire window feature to generate the attention score for each spatial location on the feature map. The spatial attention is then applied to window feature map via the element-wise multiplication across channels. Such operation enables the head module to enhance features on the salient region, where is supposed to be the rough location of the target object. Finally, the enhanced feature map will be fed into a fully connected laye to decode the segmentation mask of the object. This module is illustrated in the following figure.
The feature pyramid is sparse in this work because of the downscale operation. The sparse feature pyramid raises the probability that there exists no suitable feature maps for an object to decode, and also raises the risk of introducing background noises when the object is decoded from an unsuitable feature map with too larger receptive field. So salient region is introduced in this head. With the capability of paying attention to the salient region, a decoding head could reduce the noises from the backgrounds of a sliding window and thus produce high quality segmentation results when the receptive field is unmatched with the scale of object. Also the salient region attention has the tolerance to shift disturbance.
SOME IDEAS
- This work shares the similar idea with most one-shot alogrithms, extracting sliding window in the feature map and endcode them with a following network.
- How to extract sliding windows?
- READING NOTE: FastMask: Segment Multi-scale Object Candidates in One Shot
- 分割候选区域--FastMask: Segment Multi-scale Object Candidates in One Shot
- #Paper Reading# Learning to Segment Object Candidates
- READING NOTE: Learning to Segment Moving Objects in Videos
- 论文 Learning to Segment Object Candidates
- READING NOTE: SSD: Single Shot MultiBox Detector
- READING NOTE: DSSD: Deconvolutional Single Shot Detector
- Two-Scale Particle Simulaton--READING NOTE
- 阅读 理解 思考 - Learning to Segment Object Candidates
- 论文精读 Learning to Segment Object Candidates(一)
- 论文精读 Learning to Segment Object Candidates(二)
- READING NOTE: Towards Accurate Multi-person Pose Estimation in the Wild
- READING NOTE: Object Detection by Labeling Superpixels
- 基于深度学习的图像分割: Learning to Segment Object Candidates -- Facebook
- multi jdk in one OS
- DeepMind one shot learning 论文批注 One-Shot Generalization in Deep Generative Models
- 视频物体分割--One-Shot Video Object Segmentation
- OSVOS(One-Shot Video Object Segmentation)论文笔记
- va_start和va_end使用详解
- populating-next-right-pointers-in-each-node
- vim编辑器中如何查找某个词
- vue.js 实现 todo list 任务表单-2
- hdu1162 Eddy's picture 最小生成树 prim
- READING NOTE: FastMask: Segment Multi-scale Object Candidates in One Shot
- 新水手上船
- Java垃圾回收
- RNN时间序列预测(1)-Tensorflow入门,MNIST学习
- LeetCode 141 Linked List Cycle(链表判环)
- C++ 复制字符串/字符数组
- 巧用模板,不仅能提升AS开发效率,还能装逼
- Linux Kernel 学习笔记4:自动创建设备节点
- MongoDB的安装和配置


