spark RDD 分区
来源:互联网 发布:珠宝首饰销售数据分析 编辑:程序博客网 时间:2024/05/29 19:57
分区是为了更好的利用集群中的众多CPU,提高并行度。
实际分区应该考虑处理问题的类型,如果是IO密集型,考虑等待的时间,每个CPU上对应的分区可以适当多点,如果是计算密集型,每个CPU处理的分区就不能太多,不然相当于排队等待。是推荐的分区大小是一个CPU上面有2-4个分区。
Spark会自动根据集群情况设置分区的个数。参考spark.default.parallelism参数和defaultMinPartitions成员。
编程的时候可以通过parallelize函数设置分区数目(e.g. sc.parallelize(data, 10))。
对于来自HDFS的数据,默认一个块对应一个分区(默认快大小64M),你可以编程设置自己的分区,但不能少于块数。
Spark每个块的大小有2G的限制。
RDD的数据本地性。
很多操作会影响分区,包括cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没有partitioner
从实现上看,每个RDD都有一个Partitioner。
<img src="https://pic3.zhimg.com/20049c7cecf2107389107e42881b844e_b.jpg" data-rawwidth="1083" data-rawheight="692" class="origin_image zh-lightbox-thumb" width="1083" data-original="https://pic3.zhimg.com/20049c7cecf2107389107e42881b844e_r.jpg">图片来自《Spark大数据处理》
图片来自《Spark大数据处理》
想要重新给rdd分区,直接调用rdd.repartition方法就可以了,如果想具体控制哪些数据分布在哪些分区上,可以传一个Ordering进去。比如说,我想要数据随机地分布成10个分区,可以:class MyOrdering[T] extends Ordering[T]{ def compare(x:T,y:T) = math.random compare math.random}// 假设数据是Int类型的rdd.repartition(10)(new MyOrdering[Int])1. 什么是分区
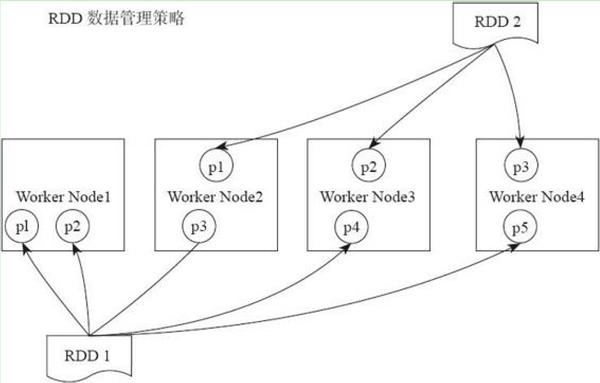
RDD 内部的数据集合在逻辑上(以及物理上)被划分成多个小集合,这样的每一个小集合被称为分区。像是下面这图中,三个 RDD,每个 RDD 内部都有两个分区。

在源码级别,RDD 类内存储一个 Partition 列表。每个 Partition 对象都包含一个 index 成员,通过 RDD 编号 + index 就能从唯一确定分区的 Block 编号,持久化的 RDD 就能通过这个 Block 编号从存储介质中获得对应的分区数据。
2. 为什么要分区
分区的个数决定了并行计算的粒度。比如说像是下面图介个情况,多个分区并行计算,能够充分利用计算资源。当然实际的情况,因为要考虑 Shuffle 依赖,肯定会比下面这张图要复杂些。

3. 如何手动分区
分两种情况,创建 RDD 时和通过转换操作得到新 RDD 时。
对于前者,在调用 textFile 和 parallelize 方法时候手动指定分区个数即可。例如 sc.parallelize(Array(1, 2, 3, 5, 6), 2) 指定创建得到的 RDD 分区个数为 2。
对于后者,直接调用 repartition 方法即可。实际上分区的个数是根据转换操作对应多个 RDD 之间的依赖关系来确定,窄依赖子 RDD 由父 RDD 分区个数决定,例如 map 操作,父 RDD 和子 RDD 分区个数一致;Shuffle 依赖则由分区器(Partitioner)决定,例如 groupByKey(new HashPartitioner(2)) 或者直接 groupByKey(2) 得到的新 RDD 分区个数等于 2。- Spark-RDD 分区
- spark RDD 分区
- spark rdd 自动分区
- Spark RDD 内部结构(二) RDD分区
- Spark自定义RDD重分区
- Spark RDD 分区数详解
- 举例说明Spark RDD的分区、依赖
- 举例说明Spark RDD的分区、依赖
- 举例说明Spark RDD的分区、依赖
- Learning Spark笔记9-确定RDD分区
- Spark开发-RDD分区重新划分
- spark RDD算子(十三)之RDD 分区 HashPartitioner,RangePartitioner,自定义分区
- Spark RDD系列-------1. 决定Spark RDD分区算法因素的总结
- spark RDD系列------2.HadoopRDD分区的创建以及计算
- Spark算子:统计RDD分区中的元素及数量
- 影响Spark输出RDD分区的操作函数
- 影响到Spark输出RDD分区的操作函数
- 影响到Spark输出RDD分区的操作函数
- P1518 两只塔姆沃斯牛 The Tamworth Two(模拟)
- Django authenticate函数验证问题
- (ssl1072、ssl1273、ssl1274)P2347 砝码称重
- A progress dialog show when optimize apk during booting up (Android device)
- Hadoop The Definitive Guide 4th Editon
- spark RDD 分区
- START
- 近期前端学习规划
- 理解JavaScript中的call、apply、bind
- LintCode 将二叉树拆成链表
- spring自动扫描机制
- kmp模板
- SSL 2295——暗黑破坏神
- 123


