GC垃圾回收
来源:互联网 发布:黑客获取数据 编辑:程序博客网 时间:2024/06/01 07:48
如何判断对象死亡
- 引用计数算法:
给对象中添加一个引用计数器,每当有一个地方引用它时计数器就加1,当引用失效时计数器值就减1,任何时刻计数器为0的对象就是不可能再被使用的。
- 优点:引用计数器算法实现简单,判定效率高。
- 缺点:引用计数器算法很难解决对象之间相互循环引用的问题(两个无用的对象互相持有之间的引用,导致计数器的值都不为0,然后就不能回收)。
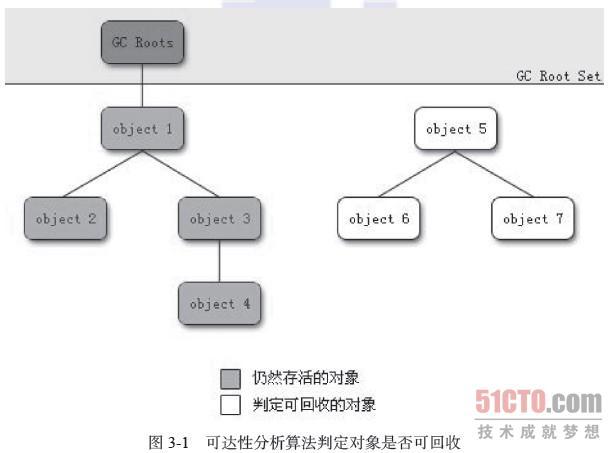
可达性分析:
以GC Roots对象为起始点,向下搜索,所走过的路称为引用链,当一个对象到GC Roots没有任何引用链相连,就判定为被回收的对象。
可以作为GC Roots的对象包括
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 栈帧是虚拟机执行时方法调用和方法执行时的数据结构,它是虚拟栈数据区的组成元素,每一个方法从调用到方法返回都对应着一个栈帧入栈出栈的过程。栈帧有局部变量表、操作数栈、动态链接、返回地址组成。
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
本地方法栈中JNI(Native方法)引用的对象
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
即使使用可达性分析算法中的不可达对象,也不是非死不可的,它只是暂时处于缓刑阶段,要真正判断一个对象死亡至少要经历两次标记:

垃圾收集算法
- 标记-清除算法
- 标记-清除算法,首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象
- 不足:
- 标记和清除这两个过程中效率都不高
- 在标记清除算法过后,会产生大量不连续的内存碎片,甚至可能导致内存不足提前触发另一次GC。
- 复制算法
- 为了解决标记清除算法的效率低下的问题我们引入了复制算法,它将可用内存按照容量划分大小相等的两块,每次只使用其中一块,当这一块内存用完时就将还存活的对象复制到另一块上面,然后再把已经使用过的内存空间一次清理掉。这样使得每次都只是对半块区域进行内存回收,内存分配时也不需要考虑内存碎片等复杂情况,只要移动堆顶指针按顺序分配内存即可。
- 优点:实现简单,运行效率高。但是内存占用太大了。
- 缺陷:复制算法在对象存活率高的时候进行比较多的复制操作,效率就会变得很低,主要还是浪费那50%的内存。
- 标记-整理算法
- 标记-整理和标记清除算法一样,但是后续步骤不是直接对对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
收集器
- Serial 收集器
- Serial收集器是一个单线程的收集器,它在回收垃圾时必须暂停其他所有的工作线程,直到它收集完成为止,
- ParNew 收集器
- ParNew收集器是Serial收集器的多线程版本,
- Parallel Scavenge 收集器
- Parallel Scavenge是一个新生代收集器,它使用的是复制算法的收集器,而且还是多线程的收集器,他的目标是达到一个可控制的吞吐量,又称吞吐量优先收集器。
- Serial Old 收集器
- SerialOld是Serial收集器的老年代版本,它同样是一个单线程收集器, 使用的是标记-整理算法。
- Parallel Old 收集器
- Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和标记整理算法。
- CMS 收集器
- CMS收集器是一种获取最短回收停顿时间为目标的收集器,他的步骤如下
- 初始标记
- 并发标记
- 重新标记
- 并发清除
- 优点
- 并发集成、低停顿
- 缺点
- CMS收集器是对CPU资源非常敏感的
- CMS收集器无法处理浮动垃圾
- CMS是基于标记-清除算法实现的,但是这样就会造成大量的空间碎片。
- CMS收集器是一种获取最短回收停顿时间为目标的收集器,他的步骤如下
- G1收集器
- 基于标记整理算法实现的,
- G1收集器的特点
- 并发于并行
- 分代收集
- 空间整合
- 可预测的停顿
- G1的步骤
- 初始标记
- 并发标记
- 最红标记
- 筛选回收
内存分配与回收策略
- 对象优先在Eden分配
- 大对象直接进入老年代
- 长期存活的对象直接进入老年代
- 动态对象年龄判断
0 0
- 内存垃圾回收 GC
- java垃圾回收GC
- Java 垃圾回收 GC
- flash 垃圾回收GC
- GC(垃圾回收)
- 垃圾回收(GC)
- 内存垃圾回收 GC
- GC垃圾回收
- GC----垃圾回收机制
- GC JVM垃圾回收
- GC垃圾回收器
- 垃圾回收器GC
- gc 垃圾回收机制
- GC垃圾回收算法
- GC 垃圾回收
- JAVA垃圾回收GC
- java 垃圾回收GC
- java GC 垃圾回收
- poj 3164 Command Network(有定根的最小树形图)
- 在myeclipse中开发webapp的一般步骤
- ASP.Net学习笔记014--ViewState初探3
- android 微信朋友圈相册封面裁剪的小秘密
- vue开发问题总结
- GC垃圾回收
- h3416最大流(未解决)
- web基础之Servlet执行过程
- leetcode-two sum
- 代理模式【介绍、静态代理、动态代理、入门、应用】
- 思科产品线
- codeforces #343d water tree(dfs+线段树)
- 精确小数点后两位
- 金融业对区块链必须有足够认识


