王小草【机器学习】笔记--提升
来源:互联网 发布:diy在线定制系统 源码 编辑:程序博客网 时间:2024/05/17 03:50
王小草【机器学习】笔记–提升
标签(空格分隔): 王小草机器学习笔记
集成学习
集成学习(ensemble learning)是通过构建多个学习器来完成学习任务的。
按照集成中学习器是否是同种类型,可分为:
同质(homogeneous)的集成:集成中只包含同种类型的个体学习器,例如决策树集成全是决策树,神经网络集成全是神经网络。同质集成中的个体学习器称为“基学习器(base leaner)”,学习算法称为“基学习算法(base learning algorithm)”。
异质(heterogenous)的集成:集成中包含不同类型的个体学习器,如同时包含决策树与神经网络。异质集成中的个体学习器称为“组件学习器(component learner)”或“个体学习器”。
按照集成的方式不同,可以分为:
Boosting:将弱学习器提升为强学习器的算法。个体学习器存在强依赖关系,必须串行生成的序列化方法。the model is dependent on the previous model
Bagging: 是并行式即成学习方法著名代表,名字来自于Bootstrap AGGregatING的缩写。个体学习器不存在强依赖关系,可以同时生成的并行化方法,the models are independent for each other。
集成学习可以获得比单一学习器显著优越的泛化性能,尤其是在弱学习器上,因此很多理论研究都针对弱学习器,尽管如此,在实际中,出于为了使用尽量少的个体学习器或其它原因,在较强的学习器上使用集成的方法,也不失为优选。
本笔记主要是针对boosting相关的知识整理。
1 提升(boosting)的概念
提升是机器学习技术,可以用于回归和分类问题。它先从初始训练集训练出一个基学习器;然后根据这个基学习器的表现对训练样本对分布进行调整,使得之前基学习期错的训练样本在之后受到更多关注;接着,基于调整后的样本分布再训练下一个基学习期,如此重复,直到基学习器数目达到设定的阈值;最后,将所有基学习器进行加权求和。(周志华《机器学习》)
也就是说,每次迭代,都会改变训练
即它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient Boosting).
梯度提升算法首先给定一个目标函数,它的定义域是所有可行的弱函数集合(基函数);提升算法通过迭代的选择一个负梯度方向上的基函数来逐渐逼近局部极小值。这种在函数域的梯度提升观点对机器学习的很多领域有深刻影响。
提升的理论意义:如果一个问题存在弱分类器,则可以通过提升的办法得到强分类器。
额。。这串概念是什么鬼,看完如果还不知所云提升是啥玩意儿。先不要急,心乱如麻先看下去。
2.梯度提升算法与推导
2.1 提升算法大致思路
现在用公式来解释一下GB算法的大致思路。
(1)给定输入向量x和输出向量y组成的若干训练样本:
(x1,y1), (x2, y2),(x3, y3)…(xn, yn)
(2)目标是要找出一个近似函数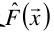 ,使得损失函数L(y, F(x))的损失最小。
,使得损失函数L(y, F(x))的损失最小。
其中损失函数L(y, F(x))的形式有多种,在回归中比较典型为: 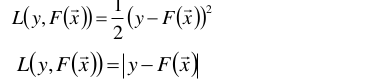
y是样本的实际值,F(x)是通过模型F预测出来的预测值,两者的差距就形成了损失。
分类问题中,用对是“对数损失函数”
也就是说,通过损失最小的目标函数,最终会求的一个最优的函数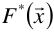 ,
, 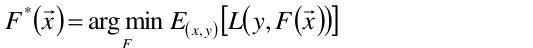
好了,现在已经很明确,我们的目标是去求最优的F(X)函数,它做出的预测与实际的值的差距是最小的,也就是预测是最准的,这当然是我们求之不得的啦。那么怎么去求这个F(X)呢?
它是一个强预测模型,上面的概念里最后一句回答了,弱预测模型可以通过提升的方式变成强预测模型。
(3)所以的所以,我们假定F(x)是一组基函数(弱预测函数)f(xi)的加权和。 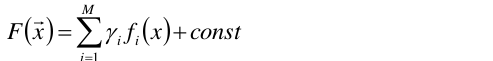
γ是每个基函数的权重。
于是问题变成了求取基函数,以及它们对应的权值γ。
其实,与线性回归的y=wx+b的形式很相似,线性回归中我们的目标是求的损失最小时各个特征的权重w,使得预测值y与真实值最接近;同理,GB中是为了得到损失最小时的权重γ(i),与对应的基函数f(i),使得损失最小,即F(x)的预测值与真实值最接近。把线性回归中的x,y换成函数f,F理解即可。
(4)总结
这是要建立的模型:
这是求得模型参数建立得目标函数(损失函数):
2.2 梯度提升算法的推导
以上大致了解了基本思路之后,现在我们重点来讲下推导的过程。
要求得的最优函数F(X)是由一组基函数f(x)加权而来。所以,问题就变成了依次求每个基函数f,以及其对应得权重γ
基函数:f0, f1, f2…fn
权值:γ0, γ1, γ2,…γn
(1)首先,给定常函数F0(x): 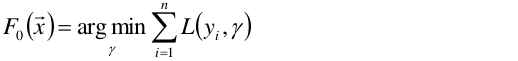
n是样本到个数,令第一个基函数f0 = 1,所以F0(x)就简化为以上公式。以上函数中未知数为γ。目标是要求以上函数最小值时γ为多少,其实就是定义F0(x)求导=0, 求出来之后常系数γ=1/n。
(2)于是现在我们有了f0和γ0,即第一个基函数与它的权值,即F0(x)。那么如何继续求接下去的基函数与权值呢?这里以贪心算法的思路扩展到Fm(x)(贪心算法就是运筹学里的动态规划): 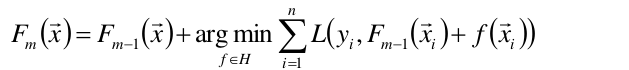
假设我们已经知道了Fm-1(x),即已经知道了f0,f1,…fm-1,与γ0,γ1…γm-1,可以将以上函数求出最优的f(xi),从而求得最优的Fm(x).
然而贪心法在每次选择最优基函数f时仍然困难。所以,选择使用梯度下降的方法来近似计算。过程是这样的:
将样本代入基函数f得到了f(x1), f(x2), …,f(xn),从而L退化维向量L(y1,f(x1)), L(y2, f(x2)),…,L(yn, f(xn))
于是可以对损失函数求f的偏导,求负梯度 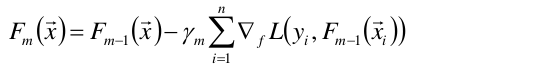
上式的权值γ为梯度下降的步长,使用线性搜索求最优步长: 
以前的梯度下降法是求出最小值时的那个x,现在是求最小值时的那个函数f(这个函数f有可能是决策树模型,逻辑回归模型等等)。
来来来,把上面的再重新理一下思路:
假设有数据集(x1,y1),(x2,y2)….
1.初始给定的模型为常数
假设第一个基函数f0=1,因此初始对模型F0(x)=γ*f0 = γ*1 = γ,
损失函数如下,对γ求导等于0,可以得到γ=1/n(n为样本个数) 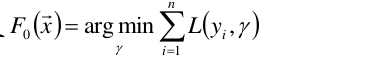 =1
=1
因此第一步之后,已知了基函数f0,当前模型F0(x),基函数对应的权重γ
接下去,就要求f2,γ2;f3,γ3;…
2.对于m=1到M
(1)计算出每个样本点在当前模型下的伪残差(负梯度) 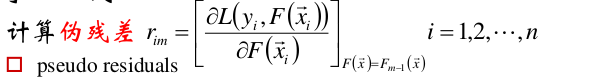
(2)使用数据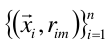 计算拟合残差的基函数fm(x).
计算拟合残差的基函数fm(x).
说人话,就是通过求得残差,我们有了一组新的数据 ,假设这组数据是样本点,对这组样本点去求得一个分类器,这个分类器其实就是我们的基函数f。
,假设这组数据是样本点,对这组样本点去求得一个分类器,这个分类器其实就是我们的基函数f。
(3)计算步长
fm(x)其实就是负梯度,也就是对第(2)步中数据拟合出的分类器。代入求得的fm(x),对每个样本点进行遍历,搜索出损失最小的样本点对应点权重γ,作为本次迭代最终的γ,也就是fm(x)基函数对应的权重 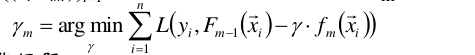
(4)更新模型,将上两步得到的权重和基函数代入,更新得到新的模型 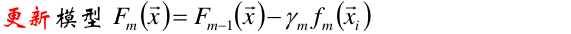
对重复以上的步骤一直到M,最终得到的F(x)就是我们需要的最优的模型。
若基函数选用的时决策树,则称之为梯度提升决策树模型,缩写为GBDT(注意GBDT中的决策树一般为回归树)。
3 XGboost
上面GBDT用的是一阶导,那么使用二阶导会咋样呢?
3.1 二阶导:
目标函数: 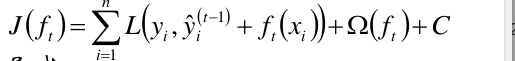
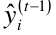 是Ft-1函数预测出来的值,
是Ft-1函数预测出来的值,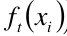 是ft基函数,将两个相加,就是Ft(x)函数的预测值,yi是实际的观测值,故L()表示预测值与观测值的损失。Ω(ft)是正则项, C是常数。
是ft基函数,将两个相加,就是Ft(x)函数的预测值,yi是实际的观测值,故L()表示预测值与观测值的损失。Ω(ft)是正则项, C是常数。
回顾一下Taylor展式: 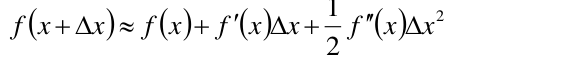
令: 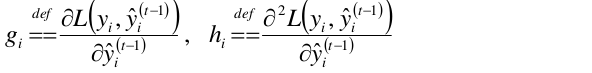
将目标函数进行Taylor展式的转换,得到如下: 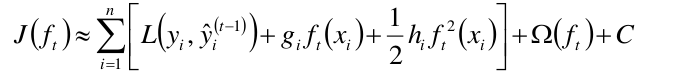
上面公式中的ft我们是想到的,它是一个基函数,也就是一个模型,比如说是一个决策树,现在我们还不知道这个决策树的结构与叶子节点的信息等。
3.2 决策树的描述
假设ft是决策树。
使用决策树对样本做分类或回归,是从根节点到叶子节点的细化过程,落在相同叶子节点的样本的预测值是相同的。
假定某决策树的叶子节点数目为T,每个叶子节点的权值为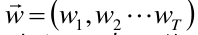
(在分类中叶子节点是不同的类别,里面有被分在那里的样本,在回归中,叶子节点是值,我们用w权值来表示)
于是决策树的学习过程,就是构造如何使用特征得到划分,从而得到这些权值的过程。
样本x落在叶子节点q中,定义f为: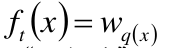
一个决策树的核心即“树结构”与“叶节点”。这两个确定了之后,这课决策树就确定了。
比如说以下例子: 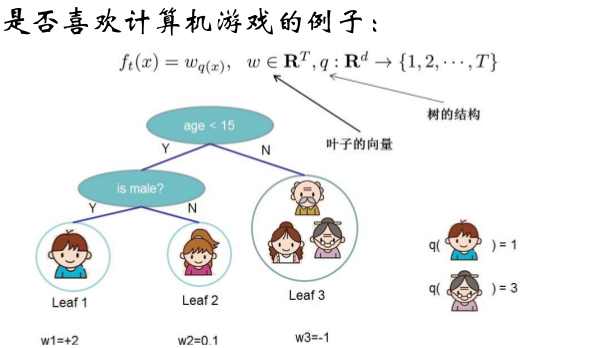
通过样本点的学习,构造了一个决策树,这个树有3个叶子节点,于是T=3;
叶子节点分别是w1,w2,w3,3个叶子节点对应的值分别是2,0.1,-1
如果把奶奶带进去,就会分在第3个叶子节点。
3.3 正则项的定义
3.3.1 根据树的复杂度
决策树越复杂,那么就越可能导致过拟合,所以要用一个正则项Ω(ft)去惩罚它。
决策树复杂度可以考虑叶节点数和叶权值,也就是说,叶节点越多,那么惩罚的力度应该越大。
下面给出定义正则项的一个方式: 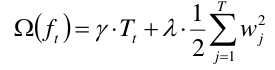
γ与λ是需要事先传入的超参数,T是节点数,w是该节点上的值。
比如上面的例子的正这项就可写成: 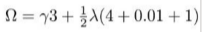
3.3.2收缩学习率
对每次学习到的基函数乘以一个学习率,避免过拟合。
3.4 目标函数的计算
根据上面的解释,于是我们就可以来计算我们之前给出的目标函数了: 
C常数项,是将公式中已知的元素取出来扔进C中。
第一步:式中的L( )损失函数的值应该是已知的,因为实际观测值y已知,t-1的预测值也是已知的。所以这是一个常数项,将它扔到C中。
第二步:f(x)的其实是f这个若预测函数对x的预测值,上文2.2.2中已经分析了预测值可以写成w权值,所以将其替换。
第三步:注意第三个等号的那个式子开头的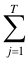 ,与前一个式子不同了,前面是i=1到n是对每一个样本点做加权,在决策树中,所有的样本点都会被分到一个叶子节点上,所以只要对每个叶子节点加权就行,因为每个叶子节点上的w是相同的。所以后面的
,与前一个式子不同了,前面是i=1到n是对每一个样本点做加权,在决策树中,所有的样本点都会被分到一个叶子节点上,所以只要对每个叶子节点加权就行,因为每个叶子节点上的w是相同的。所以后面的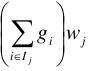 表示对该叶子节点上的所有点的g求和,w一致所以提出来在括号外面。
表示对该叶子节点上的所有点的g求和,w一致所以提出来在括号外面。
第四步:代入正则项后会发现可以提取出共同的因子,所以这个式子最后变成这样。
但是呢这个目标函数还是看上去大腹便便,我们再来简化瘦身下它:
定义: 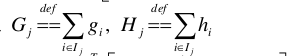
代入上面的目标函数式子,得到: 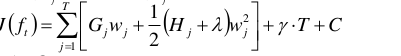
对上式的w求偏导,得到: 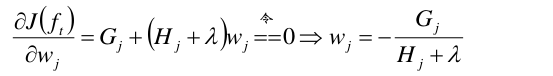
将w回代入目标函数,得到: 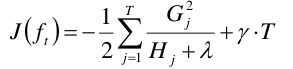
恩恩,这样美多了呢。
我们还是用上面那个小例子来解释一下这个目标函数的计算在做啥玩意儿。
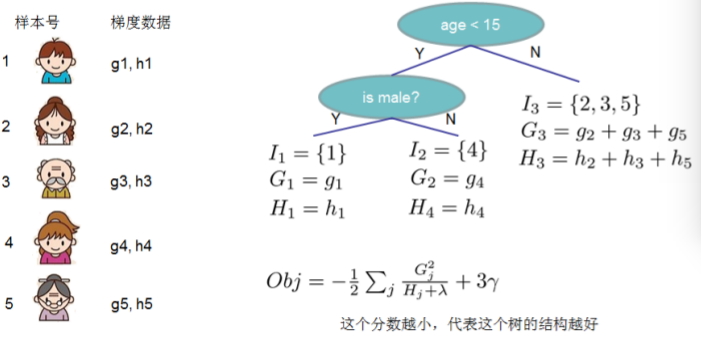
总共有5个样本点,所以分别可以求得每个样本点对应的g,h。
然后针对每个叶子节点,求每个叶子节点的G,H
最后代入公式: 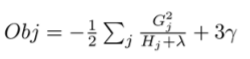
3.5 构造决策树的结构
那么对于当前节点,应该如何进行子树的划分呢?
这里同样使用贪心算法的思路:
对样本进行所有可能的划分,然后计算每次划分的损失降低的数量。选择J(f)降低最小的分割点。
也就是说,枚举所有可行的分割点,选择增益最大的划分,继续同样的操作,直到满足某阀值得到纯节点。
增益的公式如下:
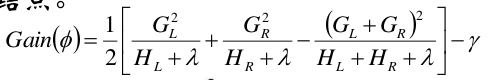
L和R表示一刀下去左边和右边形成两个节点。
如此树也构造好了,而且也可以去计算得权值w了。
3.6 XGBoost小结
以上就是XGBoost使用的核心推到过程。
相对于传统的GBDT, XGBoost使用了二阶信息,可以更快地在训练集上收敛。
有序随机森林本身具备防止过拟合的优势,因此XGBoost仍然一定程度上具有该优势。
XGBoost的实现中使用了并行/多核计算,因此训练速度快。
同事它的原生语言为C/C++,这是它速度快的实践原因。
4 Adaboost
Adaboost是最具代表性的boosting算法之一,有多种推导方式,比较容易理解的基于“加性模型(additive model)”,即基学习器的线性组合。
4.1 算法推导
设训练数据集: 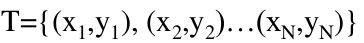
再给定一个初始化训练数据的权值分布: 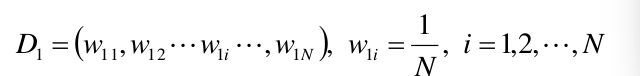
初始化的时候所有的权值都设为均值即可。
使用具有权值分布Dm的训练数据集学习,得到基本分类器: 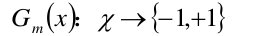
计算Gm(x)在训练数据上的分类误差率: 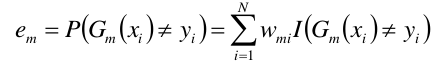
利用误差计算Gm(x)的系数: 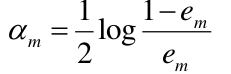
利用系数更新权值: 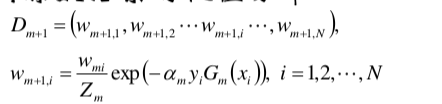
这里zm是规范化因子,它的目的仅仅是使得Dm+1成为一个概率分布。 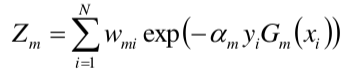
构建基本分类器的线性组合: 
得到最终的分类器: 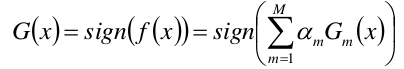
4.2 案例
来来来,一般晦涩难懂的公式都需要一杯example来调节调节气氛。
给定下列训练样本,目标使用AdaBoost算法学习一个强分类器。 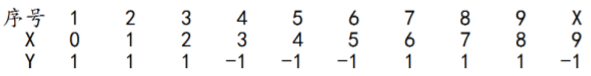
初始化训练数据的权值分布 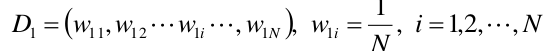
所有权值都为均值,W1i=0.1
当m=2时:
(1)在权值分布维为D1的训练数据上,阀值v取2.5的时候误差最低,所以,构建一个基本的分类器为: 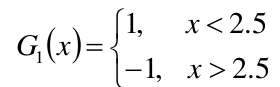
(2)计算这个分类器在训练数据集上的误差率:
e1 = 0.3
(3)计算G1分类器的系数α 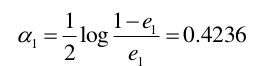
(4)更新权值分布: 
(5)构建基本分类器的线性组合 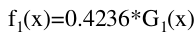
(6)分类器sign(f1(x))在训练集上有3个误分类点。迭代继续。
当m=1时:
注意此时权值已经更新了,为: 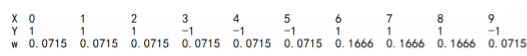
(1)在权值分布为D2的训练数据集中,阀值取8.5的时候误差率最低,于是基本分类器可以定义为: 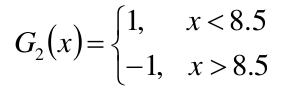
(2)计算G2的误差率: 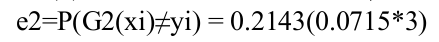
(3)计算G2的系数: 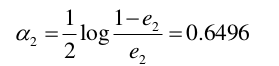
(4)更新权值分布,新的权值为: 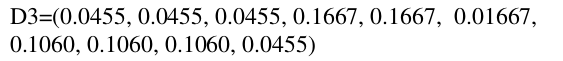
(5)构建基本分类器的线性组合: 
(6)分类器sign(f1(x))在训练集上有3个误分类点。迭代继续。
当m=3时:
(1)在权值分布为D23的训练数据集中,阀值取5.5的时候误差率最低,于是基本分类器可以定义为: 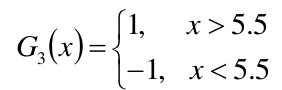
(2)计算G2的误差率: 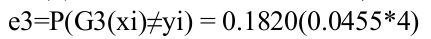
(3)计算G2的系数:
α3 = 0.7514
(4)更新权值分布,新的权值为: 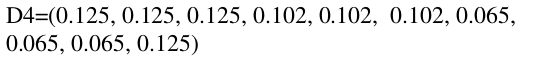
(5)构建基本分类器的线性组合: 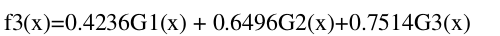
(6)分类器sign(f1(x))在训练集上有0个误分类点。完美结束
4.3 总结
Adaboost算法可以看做是采用指数损失函数的提升方法,其每个基函数的学习算法前向分步算法。
Adaboost的训练误差是以指数率下降的。
Adaboost算法不需要事先知道下界γ,具有自适应性,它能自适应弱分类器的训练误差。
- 王小草【机器学习】笔记--提升
- 王小草【机器学习】笔记--提升
- 机器学习笔记_ 提升
- 王小草【机器学习】笔记--提升之XGBoost工具的应用
- 【机器学习】笔记--梯度提升(Gradient boosting)
- 【机器学习】笔记--梯度提升(Gradient boosting)
- 机器学习之提升
- 机器学习-提升方法
- 【机器学习基础】自适应提升
- Python3《机器学习实战》学习笔记(十):提升分类器性能利器-AdaBoost
- 提升方法学习笔记
- 【R机器学习笔记】梯度提升回归树——gbm包
- 【机器学习基础】梯度提升决策树
- 机器学习:提升方法AdaBoost算法
- 机器学习算法总结--提升方法
- 【R的机器学习】决策树性能提升
- 机器学习算法总结--提升方法
- 机器学习实战-7AdaBoost提升算法
- Unity常用脚本类继承关系图
- Problem D: 字符类的封装
- UVa 540
- 5.6解题报告
- FPGA固化方法
- 王小草【机器学习】笔记--提升
- react demo7 (设置组件自身属性...this.props)
- JavaScript中的跨域详解(内附源码)
- 2017.5.6 子矩阵 思考记录
- STM32 中JTAG 引脚作为普通IO口设置方法
- vector实现三维数组
- 【BOM】Window对象、事件、方法及DOM与BOM的区别联系
- zoj 3633 rmq或线段树
- bzoj 4069: [Apio2015]巴厘岛的雕塑 (DP)


