HDU5486-Difference of Clustering
来源:互联网 发布:素描入门教程 知乎 编辑:程序博客网 时间:2024/06/05 07:24
Difference of Clustering
Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submission(s): 562 Accepted Submission(s): 199
Problem Description
Given two clustering algorithms, the old and the new, you want to find the difference between their results.
A clustering algorithm takes manymember entities as input and partition them into clusters . In this problem, a member entity must be clustered into exactly one cluster. However, we don’t have any pre-knowledge of the clusters, so different algorithms may produce different number of clusters as well as different cluster IDs. One thing we are sure about is that the memberIDs are stable, which means that the same member ID across different algorithms indicates the same member entity.
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
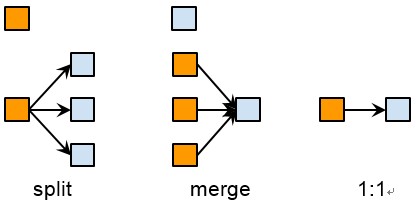
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
A clustering algorithm takes many
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
Input
The first line of input contains a number T indicating the number of test cases (T≤100 ).
Each test case starts with a line containing an integerN indicating the number of member entities (0≤N≤106 ). In the following N lines, the i -th line contains two integers c1 and c2, which means that the member entity with ID i is partitioned into cluster c1 and cluster c2 by the old algorithm and the new algorithm respectively. The cluster IDs c1 and c2 can always fit into a 32-bit signed integer.
Each test case starts with a line containing an integer
Output
For each test case, output a single line consisting of “Case #X: A B C”. X is the test case number starting from 1. A , B , and C are the numbers of splits, merges, and 1:1s.
Sample Input
230 00 00 140 00 01 11 1
Sample Output
Case #1: 1 0 0Case #2: 0 0 2
Source
2015 ACM/ICPC Asia Regional Hefei Online
Recommend
wange2014
题意:给你n对关系,每个关系是a,b,表示a,b间连了一条边(注意要去重边),问你一对多,多对一,1对1的情况分别有多少种
解题思路:用stl里的map来解决
#include<iostream> #include<cstdio> #include<cstring> #include<string> #include<algorithm> #include<queue> #include<cmath> #include<map> #include<bitset> #include<set> #include<vector> using namespace std ; int n,a,b,A,B,C; map<pair<int,int>,int>mp; map<int,int>vis,vis2; map<int,vector<int> >mp1,mp2; vector<int>V1,V2; int main() { int cas=1,t; scanf("%d",&t); while(t--) { scanf("%d",&n); mp.clear(); V1.clear(); V2.clear(); mp2.clear(); mp1.clear(); vis.clear(); vis2.clear(); for(int i=1;i<=n;i++) { scanf("%d%d",&a,&b); if(mp[make_pair(a,b)]) continue; mp1[a].push_back(b); mp2[b].push_back(a); if(!vis[a]) V1.push_back(a); if(!vis2[b]) V2.push_back(b); vis[a]=1; vis2[b]=1; mp[make_pair(a,b)]=1; } A=0,B=0,C=0; for(int i=0; i<V1.size(); i++) { int sum=0; for(int j=0; j<mp1[V1[i]].size(); j++) sum+=mp2[mp1[V1[i]][j]].size(); if(sum==mp1[V1[i]].size()) { if(sum==1) C++; else A++; } } for(int i=0; i<V2.size(); i++) { int sum=0; for(int j=0; j<mp2[V2[i]].size(); j++) sum+=mp1[mp2[V2[i]][j]].size(); if(sum==mp2[V2[i]].size()) { if(sum==1) C++; else B++; } } printf("Case #%d: %d %d %d\n",cas++,A,B,C/2); } return 0; } 0 0
- HDU5486-Difference of Clustering
- hdu 5486 Difference of Clustering
- hdu 5486 Difference of Clustering
- HDU 5486(Difference of Clustering-聚类)
- hdu 5486 Difference of Clustering(暴力)
- HDU 5486 Difference of Clustering 图论
- hdu 5486 Difference of Clustering(合肥网赛)
- hdu 5486 Difference of Clustering 2015多校联合训练赛
- hdu 5486 Difference of Clustering 2015合肥网络赛 并查集 离散化 悲伤的题
- Difference of Gaussian (DoG)
- Difference of Function and Sub
- the difference of QRectF&QRect
- difference of padding and margin
- HDOJ 5487 Difference of Languages
- Difference of Maven JAXB plugins
- DoG(Difference of Gaussian)
- Two Smallest Difference of Ad
- uncover the hood of j2ee clustering (TSS)
- Error:(1, 0) Plugin with id 'com.android.application' not found
- arm地址线的链接方式
- 多校训练赛 Furude_Rika and wall 解题报告(dp)
- 在linux和Windows使用curl
- 为什么Linux的fdisk分区时第一块磁盘分区的First Sector是2048?
- HDU5486-Difference of Clustering
- 浅谈C++里的异常类
- Intellij Idea 解决File 工具栏中没有 Import Project
- 金蝶Bos的报表跟过滤条件
- 数据库三大范式
- 优秀BLOG
- Android ExpandableListView的技巧
- SpringMVC上传文件的三种方式
- oracle--存储过程和存储函数