hdu 5486 Difference of Clustering 2015多校联合训练赛
来源:互联网 发布:权然后知轻重 编辑:程序博客网 时间:2024/06/05 20:33
Difference of Clustering
Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submission(s): 320 Accepted Submission(s): 112
Problem Description
Given two clustering algorithms, the old and the new, you want to find the difference between their results.
A clustering algorithm takes manymember entities as input and partition them into clusters . In this problem, a member entity must be clustered into exactly one cluster. However, we don’t have any pre-knowledge of the clusters, so different algorithms may produce different number of clusters as well as different cluster IDs. One thing we are sure about is that the memberIDs are stable, which means that the same member ID across different algorithms indicates the same member entity.
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
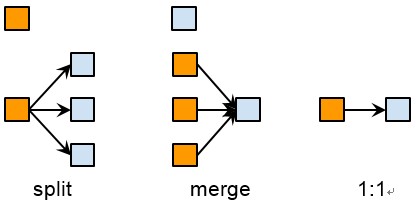
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
A clustering algorithm takes many
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
Input
The first line of input contains a number T indicating the number of test cases (T≤100 ).
Each test case starts with a line containing an integerN indicating the number of member entities (0≤N≤106 ). In the following N lines, the i -th line contains two integers c1 and c2, which means that the member entity with ID i is partitioned into cluster c1 and cluster c2 by the old algorithm and the new algorithm respectively. The cluster IDs c1 and c2 can always fit into a 32-bit signed integer.
Each test case starts with a line containing an integer
Output
For each test case, output a single line consisting of “Case #X: A B C”.X is the test case number starting from 1. A ,B , and C are the numbers of splits, merges, and 1:1s.
Sample Input
230 00 00 140 00 01 11 1
Sample Output
Case #1: 1 0 0Case #2: 0 0 2
Source
2015 ACM/ICPC Asia Regional Hefei Online
#include<iostream>#include<cstring>#include<algorithm>#include<map>#include<cstdio>using namespace std;map<int,int> haha;map<int,int> hehe;struct Node{ int old,ne;};#define maxn 1100007int num[maxn];int num2[maxn];Node po[maxn];int comp1(Node a,Node b){ return a.old < b.old;}int comp2(Node a,Node b){ return a.ne < b.ne;}int main(){ int t,tt=1,n; scanf("%d",&t); while(t--){ scanf("%d",&n); for(int i = 0;i <= n; i++) num[i] = num2[i]= 0; int cnt = 0; haha.clear(); hehe.clear(); int cnt2 = 0; for(int i = 0;i < n; i++){ scanf("%d%d",&po[i].old,&po[i].ne); if(haha.find(po[i].old) == haha.end()) haha[po[i].old] = cnt++; po[i].old = haha[po[i].old]; num[po[i].old]++; if(hehe.find(po[i].ne) == hehe.end()) hehe[po[i].ne] = cnt2++; po[i].ne = hehe[po[i].ne]; num2[po[i].ne]++; } int ans1=0,ans2=0,ans3=0; sort(po,po+n,comp1); int x = 0; while(x < n){ int y = x; haha.clear(); while(po[y].old == po[x].old && y < n) y++; int ch = po[x].ne, xn=0; for(int i = x; i < y; i++){ if(haha.find(po[i].ne) == haha.end()) haha[po[i].ne] = 0; haha[po[i].ne]++; } int flag = 1; map<int,int>::iterator it = haha.begin(); while(it != haha.end()){ if(it->second != num2[it->first]) flag = 0; it++; } if(haha.size() > 1 && flag == 1)ans1+=flag; x = y; } sort(po,po+n,comp2); x = 0; while(x < n){ int y = x; haha.clear(); while(po[y].ne == po[x].ne && y < n) y++; int ch = po[x].old, xn = 0; for(int i = x;i < y; i++){ if(haha.find(po[i].old) == haha.end()) haha[po[i].old] = 0; haha[po[i].old]++; } int flag = 1; map<int,int>::iterator it = haha.begin(); while(it != haha.end()){ if(it->second != num[it->first]) flag = 0; it++; } if(flag == 1){ if(haha.size() > 1) ans2++; else ans3++; } x = y; } printf("Case #%d: %d %d %d\n",tt++,ans1,ans2,ans3); } return 0;} 0 0
- hdu 5486 Difference of Clustering 2015多校联合训练赛
- hdu 5486 Difference of Clustering
- hdu 5486 Difference of Clustering
- hdu 5486 Difference of Clustering(合肥网赛)
- HDU 5486(Difference of Clustering-聚类)
- hdu 5486 Difference of Clustering(暴力)
- HDU 5486 Difference of Clustering 图论
- hdu 5486 Difference of Clustering 2015合肥网络赛 并查集 离散化 悲伤的题
- hdu 5381 The sum of gcd 2015多校联合训练赛#8莫队算法
- hdu 5326 work 搜索 2015多校联合训练赛
- hdu 5417 RGCDQ 2015多校联合训练赛
- hdu 5387 Clock 2015多校联合训练赛#8
- hdu 5406 2015 多校联合训练赛#10 dp
- HDU5486-Difference of Clustering
- 多校联合训练4&&HDU 5763
- 多校联合训练7&&HDU 5810
- 多校联合训练8&&HDU 5828
- hdu 5303 Delicious Apples 2015多校联合训练赛2 dp+枚举
- HTML5中div、article、section的区别及使用介绍
- <PY>转换类型:嵌套列表的遍历
- 本地事务异步恢复机制实现多数据源最终一致性
- HDU5481求数轴的并集的长度
- qt 委托 paint() 显示数据
- hdu 5486 Difference of Clustering 2015多校联合训练赛
- Perfect Squares
- hdu 5493 Queue 贪心+线段树
- hdu 541 The Next 位枚举
- 帝国备份王放到空间以后打开index.php显示空白页,解决办法
- Android Api Demos登顶之路(八十三)Graphics-->Point
- SEO优化图片方法
- 十一第一题Single Number
- 8种Nosql数据库系统对比


