编写java程序151条建议读书笔记(8)
来源:互联网 发布:西瓜影音mac版 官方 编辑:程序博客网 时间:2024/06/10 13:10
建议71:推荐使用subList处理局部列表
一个列表有100个元素,现在要删除索引位置为20~30的元素所有的操作都是在原始列表上进行的,那我们就用subList先取出一个子列表,然后清空。因为subList返回的list是原始列表的一个视图,删除这个视图中 的所有元素,最终都会反映到原始字符串上,那么一行代码解决问题了。
public static void main(String[] args) { // 初始化一个固定长度,不可变列表 List<Integer> initData = Collections.nCopies(100, 0); // 转换为可变列表 List<Integer> list = new ArrayList<Integer>(initData); //删除指定范围内的元素 list.subList(20, 30).clear(); }public void clear() { removeRange(0, size()); }protected void removeRange(int fromIndex, int toIndex) { ListIterator<E> it = listIterator(fromIndex); for (int i=0, n=toIndex-fromIndex; i<n; i++) { it.next(); it.remove(); } }建议72:生成子列表后不要再操作原列表
subList取出的列表是原列表的一个视图,原数据集(代码中的lsit变量)修改了,但是subList取出的子列表不会重新生成一个新列表(这点与数据库视图是不相同的),后面在对子列表继续操作时,就会检测到修改计数器与预期的不相同,于是就抛出了并发修改异常。数据库的一张表可以有多个视图List也可以有多张视图,也就是可以有多个子列表但问题是只要生成的子列表多于一个,任何一个子列表都不能修改了,否则就会抛出ConcurrentModificationException异常。subList生成子列表后,保持原列表的只读状态。
建议73:使用Comparator进行排序
要想给数据排序,有两种实现方式,一种是实现Comparable接口,一种是实现Comparator接口,在JDK中,对Collections.sort方法的解释是按照自然顺序进行升序排列,这种说法其实不太准确的,sort方法的排序方式并不是一成不变的升序,也可能是倒序,这依赖于compareTo的返回值,我们知道如果compareTo返回负数,表明当前值比对比值小,零表示相等,正数表明当前值比对比值大,实现了Comparable接口的类表明自身是可以比较的,有了比较才能进行排序,而Comparator接口是一个工具类接口,它的名字(比较器)也已经表明了它的作用:用作比较,它与原有类的逻辑没有关系,只是实现两个类的比较逻辑,从这方面来说,一个类可以有很多的比较器,只要有业务需求就可以产生比较器,有比较器就可以产生N多种排序,而Comparable接口的排序只能说是实现类的默认排序算法,一个类稳定、成熟后其compareTo方法基本不会变,也就是说一个类只能有一个固定的、由compareTo方法提供的默认排序算法。Comparable接口可以作为实现类的默认排序算法,Comparator接口则是一个类的扩展排序工具。
建议74:不推荐使用binarySearch对列表进行检索
对一个列表进行检索时使用最多的是indexOf方法,它简单、好用,而且也不会出错,虽然它只能检索到第一个符合条件的值,但是可以生成子列表后再检索,这样也即可以查找出所有符合条件的值了。Collections工具类也提供了一个检索方法,binarySearch该方法也是对一个列表进行检索的,可查找出指定值的索引。
public class test { public static void main(String[] args) { List<String> cities = new ArrayList<String> (); cities.add("上海"); cities.add("广州"); cities.add("广州"); cities.add("北京"); cities.add("天津"); //indexOf取得索引值 int index1= cities.indexOf("广州"); //binarySearch找到索引值 int index2= Collections.binarySearch(cities, "广州"); System.out.println("索引值(indexOf):"+index1); System.out.println("索引值(binarySearch):"+index2); }}使用二分搜索法搜索指定列表,以获得指定对象。其实现的功能与indexOf是相同的,只是使用的是二分法搜索列表,索引值(indexOf):1, 索引值(binarySearch):2indexOf方法就是一个遍历,找到第一个元素值相等则返回二分法查询的一个首要前提是:数据集以实现升序排列,否则二分法查找的值是不准确的。不排序怎么确定是在小区(比中间值小的区域) 中查找还是在大区(比中间值大的区域)中查找呢?二分法查找必须要先排序,这是二分法查找的首要条件。建议75:集合中的元素必须做到compareTo和equals同步
实现了Comparable接口的元素就可以排序,compareTo方法是Comparable接口要求必须实现的,它与equals方法有关系吗?有关系,在compareTo的返回为0时,它表示的是进行比较的两个元素时相等的。indexOf是通过equals方法判断的,equals方法等于true就认为找到符合条件的元素了,而binarySearch查找的依据是compareTo方法的返回值,返回0即认为找到符合条件的元素了。indexOf依赖equals方法查找,binarySearch则依赖compareTo方法查找;
equals是判断元素是否相等,compareTo是判断元素在排序中的位置是否相同。一个决定排序位置,一个是决定相等,我们就应该保证当排序相同时,其equals也相同,否则就会产生逻辑混乱。实现了compareTo方法就应该覆写equals方法,确保两者同步。
建议76:集合运算时使用最优雅方式
遍历可以实现并集、交集、差集等运算,但是不优雅,1)并集:也叫作合集 list1.addAll(list2); 2)交集:计算两个集合的共有元素list1.retainAll(list2); 3)差集:由所有属于A但不属于B的元素组成的集合list1.removeAll(list2); 4)无重复的并集:并集是集合A加集合B,那如果集合A和集合B有交集,就需要确保并集的结果中只有一份交集,此为无重复的并集list2.removeAll(list1); //把剩余的list2元素加到list1中 list1.addAll(list2);
建议77:使用shuffle打乱列表
打乱一个列表的顺序,我们不用费尽心思的遍历、替换元素了。我们一般很少用到shuffle这个方法,在什么地方用
1)可用在程序的 "伪装" 上:比如我们例子中的标签云,或者是游侠中的打怪、修行、群殴时宝物的分配策略。
2)可用在抽奖程序中:比如年会的抽奖程序,先使用shuffle把员工顺序打乱,每个员工的中奖几率相等,然后就可以抽出第一名、第二名。
3)可以用在安全传输方面:比如发送端发送一组数据,先随机打乱顺序,然后加密发送,接收端解密,然后进行排序,即可实现即使是相同的数据源,也会产生不同密文的效果,加强了数据的安全性。
建议78:减少HashMap中元素的数量
HashMap和ArrayList的长度都是动态增加的,不过两者的扩容机制不同,HashMap,它在底层是以数组的方式保存元素的,其中每一个键值对就是一个元素,HashMap把键值对封装成了一个Entry对象,然后再把Entry对象放到了数组中。也就是说HashMap比ArrayList多了一次封装,多出了一倍的对象。其中HashMap的扩容机制代码(resize(2 * table.length)这就是扩容核心,在插入键值对时会做长度校验,如果大于或者等于阈值,则数组长度会增大一倍。hashMap的size大于数组的0.75倍时,就开始扩容,ArrayList的扩容策略,它是在小于数组长度的时候才会扩容1.5倍综合来说,HashMap比ArrayList多了一层Entry的底层封装对象,多占用了内存,并且它的扩容策略是2倍长度的递增,同时还会根据阈值判断规则进行判断,因此相对于ArrayList来说,同样的数据,它就会优先内存溢出。
建议79:集合中的哈希码不要重复
列表中查找某值是非常耗费资源的,随机存取的列表是遍历查找,顺序存储的列表是链表查找,或者是Collections的二分法查找最快的还要数以Hash开头的集合(如HashMap、HashSet等类)查找,HashMap的ContainsKey方法public boolean containsKey(Object key) { //判断getEntry是否为空 return getEntry(key) != null; }getEntry方法会根据key值查找它的键值对(也就是Entry对象),如果没有找到,则返回null。HashMap的table数组是如何存储元素的1)table数组的长度永远是2的N次幂。2)table数组的元素是Entry类型。3)table数组中的元素位置是不连续的。HashMap是如何插入元素的
public V put(K key, V value) { //null键处理 if (key == null) return putForNullKey(value); //计算hash码,并定位元素 int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K, V> e = table[i]; e != null; e = e.next) { Object k; //哈希码相同,并且key相等,则覆盖 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //插入新元素,或者替换哈希的旧元素并建立链表 addEntry(hash, key, value, i); return null; }HashMap每次增加元素时都会先计算其哈希码值,然后使用hash方法再次对hashCode进行抽取和统计,同时兼顾哈希码的高位和低位信息产生一个唯一值,也就是说hashCode不同,hash方法返回的值也不同,之后再通过indexFor方法与数组长度做一次与运算,即可计算出其在数组中的位置,简单的说,hash方法和indexFor方法就是把哈希码转变成数组的下标null值也是可以作为key值的,它的位置永远是在Entry数组中的第一位。哈希运算存在着哈希冲突问题,即对于一个固定的哈希算法f(k),允许出现f(k1)=f(k2),但k1≠k2的情况,也就是说两个不同的Entry,可能产生相同的哈希码,HashMap是如何处理这种冲突问题的呢?答案是通过链表,每个键值对都是一个Entry,其中每个Entry都有一个next变量,也就是说它会指向一个键值对---很明显,这应该是一个单向链表,该链表是由addEntity方法完成的如果新加入的元素的键值对的hashCode是唯一的,那直接插入到数组中,它Entry的next值则为null;如果新加入的键值对的hashCode与其它元素冲突,则替换掉数组中的当前值,并把新加入的Entry的next变量指向被替换的元素,于是一个链表就产生了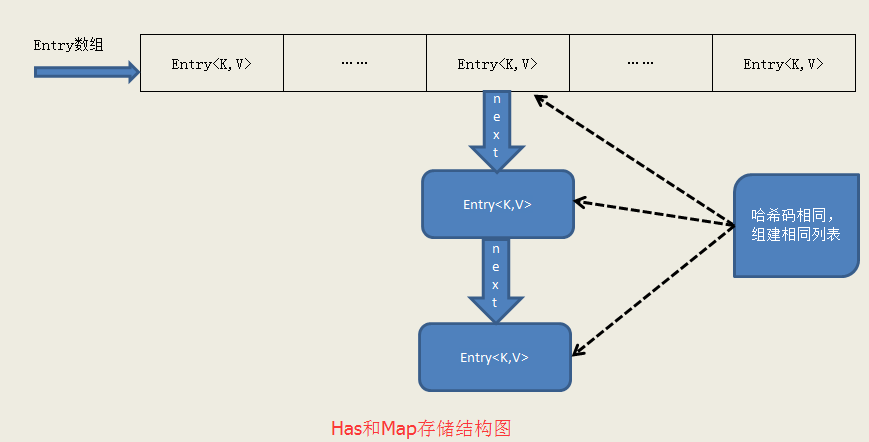
- 编写java程序151条建议读书笔记(8)
- 编写java程序151条建议读书笔记(1)
- 编写java程序151条建议读书笔记(2)
- 编写java程序151条建议读书笔记(3)
- 编写java程序151条建议读书笔记(4)
- 编写java程序151条建议读书笔记(5)
- 编写java程序151条建议读书笔记(6)
- 编写java程序151条建议读书笔记(7)
- 编写java程序151条建议读书笔记(9)
- 编写java程序151条建议读书笔记(10)
- 编写java程序151条建议读书笔记(11)
- 编写java程序151条建议读书笔记(12)
- 编写java程序151条建议读书笔记(13)
- 编写java程序151条建议读书笔记(14)
- 编写java程序151条建议读书笔记(15)
- 编写java程序151条建议读书笔记(16)
- 编写java程序151条建议读书笔记(18)
- 编写java程序151条建议读书笔记(17)
- 英语看书笔记1
- Swing学习----------java的布局管理学习总结(一)
- 蓝桥杯比赛总结
- Activity标题栏添加返回按钮
- gulp的安装&less插件
- 编写java程序151条建议读书笔记(8)
- 组合游戏(Circles Game,HDU 5299)
- 数据结构之队列
- 在tomcat上发布servlet访问mysql数据库完成登录功能的案例经验总结
- Maven pom.xml配置详解
- iOS蓝牙开发
- python基础操作
- 磁盘I/O中几种访问文件的方式
- Linux基本操作命令(二)


