softmax回归(Softmax Regression)
来源:互联网 发布:mac怎么看硬盘文件 编辑:程序博客网 时间:2024/05/19 12:11
Softmax Regression
注:这篇博客是看NG的UFLDL_Tutorial写的博客笔记,其中大量文字和公式来自该网页,自己只添加了公式推导和实验编程部分。网址为:Link。
本文主要从下几个方面介绍softmax回归(softmax regression):
- softmax regression的代价函数
- softmax regression模型参数的特点(参数冗余)
- 权重衰减
- Softmax回归与Logistic 回归的关系
- Softmax 回归 vs. k 个二元分类器
- 实验编程(手写体识别)
一、代价函数
softmax regression主要用于解决多元分类问题,假设对于样本 ,样本有K个类别,即
,样本有K个类别,即 。例如对于手写体识别来说
。例如对于手写体识别来说 。softmax回归主要是估算对于输入样本
。softmax回归主要是估算对于输入样本 属于每一类别的概率,所以softmax回归的假设函数如下:
属于每一类别的概率,所以softmax回归的假设函数如下:

其中 是模型的参数,乘以
是模型的参数,乘以 的目的是为了使概率在[0,1]之间且概率之和为1。因此,softmax回归将样本标记为类别
的目的是为了使概率在[0,1]之间且概率之和为1。因此,softmax回归将样本标记为类别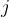 的概率为:
的概率为:
下面来看个例子(图片来自台大李宏毅《一天搞懂深度学习》)
 )
)softmax回归的参数矩阵 可以记为:
可以记为:
下面直接来看softmax回归的代价函数:
其中, 是示性函数,所谓示性函数即
是示性函数,所谓示性函数即 ,举例来说就是,
,举例来说就是, 。因此我们的目的还是最小化代价函数,可以用梯度下降来求,下面来推导下梯度,即
。因此我们的目的还是最小化代价函数,可以用梯度下降来求,下面来推导下梯度,即 。关于这个公式的推导,为了让大家看的很清楚,我看用两种方法推导:
。关于这个公式的推导,为了让大家看的很清楚,我看用两种方法推导:
,举例来说就是,1.法一:

这里面几个容易踩得坑:1.对 求偏导,这个j不要和
求偏导,这个j不要和 这里的j混淆了,还有就是除j项外其他项为0。2.红色框起来的地方结果为1,因为仅有一种类别满足条件是真,其他是0。
这里的j混淆了,还有就是除j项外其他项为0。2.红色框起来的地方结果为1,因为仅有一种类别满足条件是真,其他是0。
2.法二:如果上面的推导过程没看明白,可以看看下面这种推导方法,之所以要拆成两项,是因为 分母总含有
分母总含有 这一项,于是我们可以下列的方法拆成两项:
这一项,于是我们可以下列的方法拆成两项:
分母总含有
好吧,不得不承认编辑公式是一件费时费力的事情。。。
二、softmax regression模型参数的特点(参数冗余)
这一段直接copy ufldl教程,因为发现自己无论怎么总结,都没NG说的好。。
Softmax 回归有一个不寻常的特点:它有一个“冗余”的参数集。为了便于阐述这一特点,假设我们从参数向量 中减去了向量
中减去了向量 这时,每一个都变成了
这时,每一个都变成了 。此时假设函数变成了以下的式子:
。此时假设函数变成了以下的式子:

换句话说,从中减去完全不影响假设函数的预测结果!这表明前面的 softmax 回归模型中存在冗余的参数。更正式一点来说, Softmax 模型被过度参数化了。对于任意一个用于拟合数据的假设函数,可以求出多组参数值,这些参数得到的是完全相同的假设函数 。
。
进一步而言,如果参数 是代价函数
是代价函数 的极小值点,那么
的极小值点,那么 同样也是它的极小值点,其中可以为任意向量。因此使最小化的解不是唯一的。(有趣的是,由于仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)
同样也是它的极小值点,其中可以为任意向量。因此使最小化的解不是唯一的。(有趣的是,由于仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)
注意,当 时,我们总是可以将
时,我们总是可以将 替换为
替换为 (即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的
(即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的 个参数
个参数 (其中
(其中 ),我们可以令
),我们可以令 ,只优化剩余的
,只优化剩余的 个参数,这样算法依然能够正常工作。
个参数,这样算法依然能够正常工作。
在实际应用中,为了使算法实现更简单清楚,往往保留所有参数,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
进一步而言,如果参数
注意,当
在实际应用中,为了使算法实现更简单清楚,往往保留所有参数
三、权重衰减
这个权重衰减在统计学中叫做收缩法(shrinkage),在神经网络中叫做权重衰减,其实就是个正则项用于惩罚参数 。在以前的博客讲正则项的时候也讲过为什么正则项能够惩罚系数。这里再说一下吧,来看个例子:假如对于一个多项式函数:
。在以前的博客讲正则项的时候也讲过为什么正则项能够惩罚系数。这里再说一下吧,来看个例子:假如对于一个多项式函数:
下面通过 一张表来说明系数是如何随着多项式阶数增加而剧增的(来自PRML):

废话不多说了,直接来看softmax回归增加一个权重衰减项后的代价函数吧:
其中 ,因此对代价函数求偏导后的导数为:
,因此对代价函数求偏导后的导数为:
四、Softmax回归与Logistic 回归的关系
其实softmax回归是logistic回归的一般形式,logistic回归是softmax回归在 时的特殊形式,下面通过公式推导来看下当时softmax回归是如何退化成logistic回归的:
时的特殊形式,下面通过公式推导来看下当时softmax回归是如何退化成logistic回归的:
当时,softmax回归的假设函数为:
前面说过softmax回归的参数具有冗余性,从参数向量中减去向量,完全不影响结果。现在我们令 ,并且两个参数向量都减去,则有:
,并且两个参数向量都减去,则有:

最后化成了logistic回归。
五、Softmax 回归 vs. k 个二元分类器
知道“one vs all”的都知道对于K元分类而言,可以训练K个二元分类器来实现K元分类,那么究竟何时该使用softmax回归,何时使用K个二元分类器呢,ng给出的标准是这样的:
- 如果你的数据集的K个类别是相互独立互斥的,比如手写体识别1-10,样本只能有一个类别,某一样本不可能既属于1又属于2。那么就用softmax回归
- 如果你的数据集的K个类别不是互斥的,比如音乐类型分类(考虑四个类别:人声音乐、舞曲、影视原声、流行歌曲),这些某类别不是互斥的,例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
六、实验编程(手写体识别)
实验还是做得UFLDL上的softmax回归编程题,数据集用的Yann Lecun的手写体识别数据集,主要是实现代价函数和梯度(导数),我只把核心代码贴出来:

具体的说下这个代码吧,唯一要说的就是cost和thetagrad这两个公式的实现,其他的都很简单,一看就明白的。先说cost:
groundTruth是一个10*60000的矩阵,10是类别(1-10),60000是样本的数量,样本属于哪个类别该类别置为1,其他均为0,看图吧:

prediction_probability也是一个10*60000的矩阵,是在theta随机初始化下对于每个类别的预测概率,如下图所示:

先看对于第一个样本 时,就是每个类别的示性函数*每个类别的对数概率之和,因此就是上述两个表的第一列向量乘积,然后60000个样本累加,因此可以可以转换为groundTruth(:)'*log_probability(:),groundTruth(:)是把groundTruth矩阵按列拼接成向量。
时,就是每个类别的示性函数*每个类别的对数概率之和,因此就是上述两个表的第一列向量乘积,然后60000个样本累加,因此可以可以转换为groundTruth(:)'*log_probability(:),groundTruth(:)是把groundTruth矩阵按列拼接成向量。
再看thetagrad:
我们得到的代价函数的导数是对求得导,此时只是某一个具体的参数向量,现在我们要求出k个参数向量,具体到这个题目而言要求 ,注意
,注意 是一个1*784的向量。直接看
是一个1*784的向量。直接看 的梯度怎么求,由梯度公式知道:
的梯度怎么求,由梯度公式知道:
因此 就是groundTruth的第一行减去log_probability的第一行,然后乘以data的每一行(因为有求和函数),那这样如果用矩阵一次性运算求出,就变成了
就是groundTruth的第一行减去log_probability的第一行,然后乘以data的每一行(因为有求和函数),那这样如果用矩阵一次性运算求出,就变成了 。因此实际得到的thetagrad是一个10*784的矩阵。784是因为数据集采样的时候按照28*28像素采样的,可以理解为784个特征。
。因此实际得到的thetagrad是一个10*784的矩阵。784是因为数据集采样的时候按照28*28像素采样的,可以理解为784个特征。
现在总结来看:

关于softmax回归就介绍这么多,如有错误之处,欢迎大家留言指正。
0 1
- softmax回归(Softmax Regression)
- Softmax回归(Softmax Regression)
- Softmax回归(Softmax Regression)
- Softmax回归(Softmax Regression)
- Ufldl Exercise:Softmax Regression Softmax回归练习
- MNIST和softmax回归(softmax regression)
- Logistic and Softmax Regression (逻辑回归和Softmax回归)
- Logistic and Softmax Regression (逻辑回归和Softmax回归)
- UFLDL——Exercise: Softmax Regression (softmax回归)
- [03]tensorflow实现softmax回归(softmax regression)
- SoftMax regression
- Softmax Regression
- softmax regression
- Softmax Regression
- Softmax Regression
- Softmax regression
- Softmax Regression
- Softmax回归
- Git 常用命令大全
- Hadoop常用指令
- 去除android导航栏和状态栏(返回键,home键,列表键)
- pandas数据结构Series学习
- yolo论文
- softmax回归(Softmax Regression)
- LoadRunner的安装破解教程
- [转载] ubuntu下如何查找某个文件的路径
- redhat下安装activeMQ
- STM32 根据固件库新建工程
- java 的接口可以实现接口吗?抽象类呢?
- 在ubuntu上安装neo4j图形数据库(3.2.0 Community Edition)
- Discuz!教程之论坛设置过滤词无效的解决方法
- MAC 为python3安装 beautifulsoup4


