Machine Learning第九讲[推荐系统] --(三)低秩矩阵分解
来源:互联网 发布:linux暴力破解root密码 编辑:程序博客网 时间:2024/04/30 00:21
内容来自Andrew老师课程Machine Learning的第九章内容的Low Rank Matrix Factorization部分。
一、Vectorization: Low Rank Matric Factorization(向量化: 低秩矩阵分解)
我们仍然使用之前movie的例子:

将这些数据写成矩阵的形式,即右边的Y矩阵,又因为用户j对电影i的评分预测值为: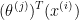
因此Y矩阵对应的预测值应为:

我们记:
则:

= 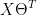
上述就是协同矩阵的向量化。
那么我们应该怎样来找出相关商品呢?
首先对于每一个产品i,我们找出其特征向量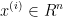
找出使两个商品特征比较相同的产品,即可以找出使得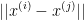 最小的五个商品,则这5个商品就是和i最相似的5个商品,既可以作为相关产品推荐。
最小的五个商品,则这5个商品就是和i最相似的5个商品,既可以作为相关产品推荐。
二、Implementational Detail: Mean Normalization(实现细节: 均值归一化)
假设我们有下面一组数据:

即有一个用户Eve没有对任何电影进行评价,这时候如果我们使用之前的方法测Eve对每部电影的评分,则最小化图上的公式,因为对于任意i,Eve都没有评分过,因此①式r(i, j)=1条件不满足,因此①对于最小化Eve的数据没有作用,②也没有作用,因此对于最小化Eve数据有作用的便是③式,即,因此二者都为0,因此
,于是对于Eve的预测值:
,即Eve对任何电影的预测值都为0。虽然结果是得出来了,但是这个结果我们没办法用来推荐,因为对所有的电影,其
都为0。
因此,我们引入归一化:

即对于某一部电影,利用已经评过分的值(?不计算在内),计算出平均分,记为μ,于是归一化矩阵为原来的Y的每一个数减去这一行(这一部电影)对应的平均值,得到新的Y,如图片右侧所示(?的仍为?),利用这个新的Y矩阵学习θ和x的值。则对于Eve,之前关于最小化的分析仍成立,即
归一化之后的预测值公式为:
因此对于Eve的预测值为:
其实对于这个预测结果我们是可以接受的,因为我们不知道Eve的喜好,因此把她的评分预测为平均水平。
特殊情况:若出现有一部电影无评分的情况,则可以考虑使每列的均值为0,即计算每列的均值,用Y减去对应列的均值得到新的Y矩阵。
阅读全文
1 0
- Machine Learning第九讲[推荐系统] --(三)低秩矩阵分解
- Machine Learning第九讲[推荐系统] --(二)协同过滤
- Machine Learning第九讲[推荐系统] --(一)基于内容的推荐系统
- Standord Machine Learning -- 第九讲 推荐引擎
- Machine Learning第九讲[异常检测] --(三)多元高斯分布(选学)
- Machine Learning第九讲[异常检测] --(二)创建一个异常检测系统
- Machine Learning第九周笔记:异常检测与推荐系统
- Machine Learning第九讲[异常检测] --(一)密度估计
- 《Machine Learning》第九讲 K-means算法
- Andrew Ng《Machine Learning》第九讲——异常检测和推荐算法
- Machine Learning第三讲[Logistic回归] --(三)多元分类
- Machine Learning第四讲[神经网络: 表示] --(三)应用
- 矩阵分解与推荐系统
- 推荐系统之矩阵分解
- 推荐系统之矩阵分解
- 推荐系统ALS矩阵分解
- 推荐系统ALS矩阵分解
- 推荐系统中的矩阵分解
- 2014年第五届蓝桥杯C/C++程序设计本科B组决赛 年龄巧合(结果填空)
- linux进入mysql数据库
- Struts1框架三之里面的DynActionForm讲解
- python: reduce()函数、lambda函数、map()函数
- Canvas API详解(Part 2)剪切方法合集
- Machine Learning第九讲[推荐系统] --(三)低秩矩阵分解
- [YTU]_2907( 类重载实现矩阵加法)
- Ubuntu下嵌入式Linux开发环境搭建
- 数据库like查询
- hdu-3085(双向bfs)
- Math数组Date
- codevs 1078 最小生成树
- 5.17
- 细致分析cookie、session、sessionid 与jsessionid


