adaboost原理图解
来源:互联网 发布:linux设置为中文后死机 编辑:程序博客网 时间:2024/05/16 14:26
二、Adaboost算法及分析



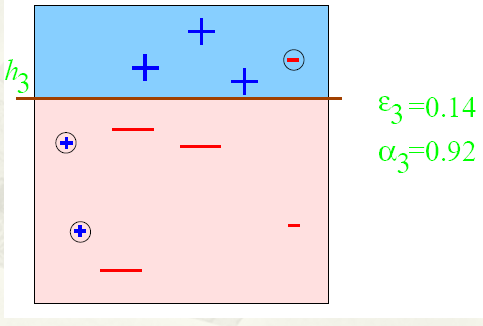
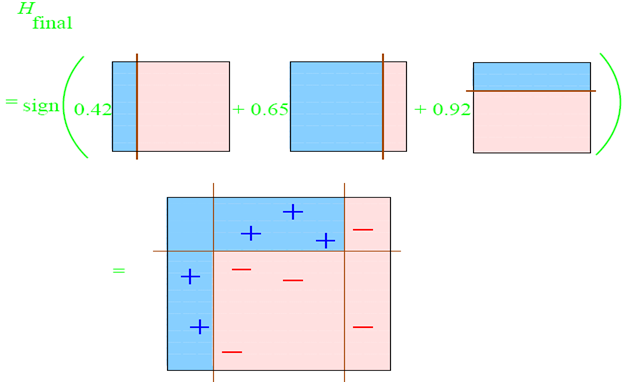
阅读全文
0 0
- adaboost原理图解
- Adaboost 原理
- AdaBoost原理
- AdaBoost原理
- AdaBoost算法原理
- AdaBoost算法原理
- AdaBoost算法原理
- Adaboost 原理 应用
- Adaboost原理、应用
- AdaBoost检测原理
- AdaBoost算法原理
- AdaBoost原理,算法实现
- AdaBoost算法原理
- AdaBoost算法原理
- AdaBoost算法原理
- Adaboost 算法及原理
- AdaBoost算法原理
- Adaboost原理、应用
- bzoj1419: Red is good
- JAVA与数据库
- 单例模式
- netfilter/iptables学习总结(一)
- 给学习Linux系统小白的两三个建议
- adaboost原理图解
- 使用Maven搭建Struts2+Spring3+Hibernate4的整合开发环境
- 树莓派GPS(USB转串口)获取经纬度
- 1179: 构造表达式
- jQueryTable DataTables
- 【影评】速度与激情8
- 剑指offer 面试题12 打印 1 到最大的 n 位整数
- Unity-UGUI——通过代码给UI元素添加对应事件
- matlab实现彩色图像特征提取1


