python之nltk基础用法
来源:互联网 发布:帝国cms用户密码忘记 编辑:程序博客网 时间:2024/06/08 07:06
一、NLTK进行分词
用到的函数:
nltk.sent_tokenize(text) #对文本按照句子进行分割
nltk.word_tokenize(sent) #对句子进行分词

二、NLTK进行词性标注
用到的函数:
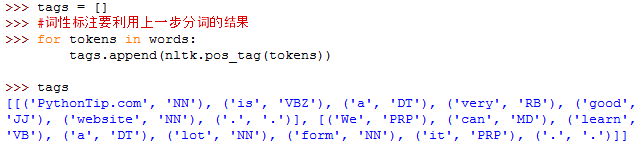
nltk.pos_tag(tokens)#tokens是句子分词后的结果,同样是句子级的标注
三、NLTK进行命名实体识别(NER)
用到的函数:
nltk.ne_chunk(tags)#tags是句子词性标注后的结果,同样是句子级
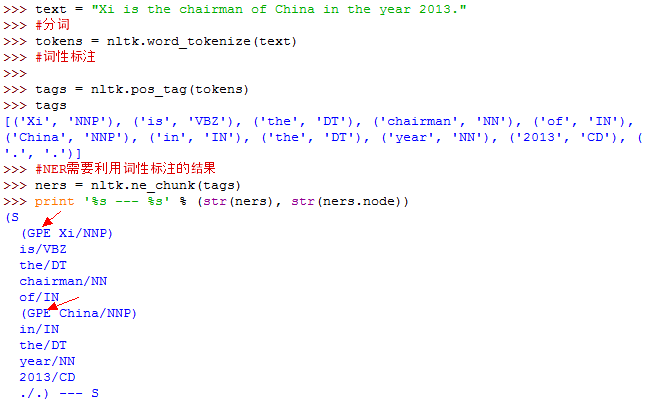
上例中,有两个命名实体,一个是Xi,这个应该是PER,被错误识别为GPE了; 另一个事China,被正确识别为GPE。
四、句法分析
nltk没有好的parser,推荐使用stanfordparser
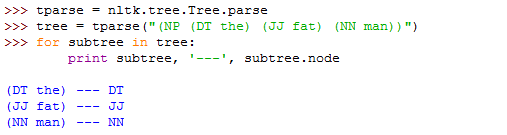
但是nltk有很好的树类,该类用list实现
可以利用stanfordparser的输出构建一棵python的句法树
阅读全文
0 0
- python之nltk基础用法
- 【Python&NLP】nltk的几个基础函数
- NLP-python自然语言工具之nltk
- Python学习之入门--加载nltk自然语言处理
- python NLTK、中文分词
- python NLTK学习
- python NLTK 环境搭建
- Python-NLTK环境搭建
- python nltk 基本操作
- Python nltk -- Sinica Treebank
- 第一章 Python and NLTK
- python NLTK环境搭建
- python NLTK 环境搭建
- Python NLTK学习
- python+Myeclipse2014+pymongo+NLTK
- Python安装nltk模块
- windows7 安装python +nltk
- [python]NLTK简明教程
- Java实现-买卖股票的最佳时机1
- ubuntu/centos 搭建 搭建 redis 集群
- Windows下C/C++获取当前系统时间
- 【XML解析】(6)利用XML+DOM4j+Xpath+MD5加密+图形界面(Jtabe+Vector)实现《通讯录管理系统》
- luogu P1387 最大正方形
- python之nltk基础用法
- JavaScript之Set和Map数据结构
- CentOS 7 中使用 Sendmail 通过 PHP 发送邮件
- cocos-js 常用API
- jsp页面中的代码执行加载顺序介绍
- 如何在C++中将filetime时间转化为字符串?
- 滑动鼠标改变背景色
- Java注解----自定义注解
- Windows API的时间结构体、时间转换及时间获取


