java多线程发展史
来源:互联网 发布:东京轰炸 知乎 编辑:程序博客网 时间:2024/06/05 19:13
诞生
Java的基因来自于1990年12月Sun公司的一个内部项目,目标设备正是家用电器,但是C++的可移植性和API的易用性都让程序员反感。旨在解决这样的问题,于是又了Java的前身Oak语言,但是知道1995年3月,它正式更名为Java,才算Java语言真正的诞生。
JDK 1.0
1996年1月的JDK1.0版本,从一开始就确立了Java最基础的线程模型,并且,这样的线程模型再后续的修修补补中,并未发生实质性的变更,可以说是一个具有传承性的良好设计。
抢占式和协作式是两种常见的进程/线程调度方式,操作系统非常适合使用抢占式方式来调度它的进程,它给不同的进程分配时间片,对于长期无响应的进程,它有能力剥夺它的资源,甚至将其强行停止。采用协作式的方式,需要进程自觉、主动地释放资源,在这种调度方式下,可能一个执行时间很长的线程使得其他所有需要CPU的线程”饿死”。java采用hotspot虚拟机的调度方式为抢占式调用,因此Java语言一开始就采用抢占式线程调度的方式。1.0中线程间的协作通信采用简单粗暴的stop/resume/suspend这样的方法。
stop即可停止run()方法中剩余的全部工作,包括在catch或finally语句中,并抛出ThreadDeath异常(通常情况下此异常不需要显示的捕获),因此可能会导致一些清理性的工作的得不到完成,如文件,数据库等的关闭,而且会立即释放改线程持有的所有锁,会导致数据中断同步处理,出现数据不一致现象。
resume/suspend必须要成对出现,否则非常容易发生死锁,因为suspend方法并不会释放锁,如果使用suspend的目标线程对一个重要的系统资源持有锁,那么没任何线程可以使用这个资源直到要suspend的目标线程被resume,如果一个线程在resume目标线程之前尝试持有这个重要的系统资源锁再去resume目标线程,这两条线程就相互死锁了,也就冻结线程。
在比较稳定的JDK 1.0.2版本中,可以找到Thread和ThreadUsage这样的类,这也是线程模型中最核心的两个类。整个版本只包含了这样几个包:java.io、 java.util、java.NET、java.awt和java.applet,所以说Java从一开始这个非常原始的版本就确立了一个持久的线程模型。
JDK 1.2
1998年年底的JDK1.2版本正式把Java划分为J2EE/J2SE/J2ME三个不同方向。在这个版本中,Java试图用Swing修正在AWT中犯的错误,例如使用了太多的同步。可惜的是,Java本身决定了AWT还是Swing性能和响应都难以令人满意,这也是Java桌面应用难以比及其服务端应用的一个原因,在IBM后来的SWT,也不足以令人满意,JDK在这方面到JDK 1.2后似乎反省了自己,停下脚步了。值得注意的是,JDK高版本修复低版本问题的时候,通常遵循这样的原则:
向下兼容。所以往往能看到很多重新设计的新增的包和类,还能看到deprecated的类和方法,但是它们并不能轻易被删除。
严格遵循JLS(Java Language Specification),并把通过的新JSR(Java Specification Request)补充到JLS中,因此这个文档本身也是向下兼容的,后面的版本只能进一步说明和特性增强,对于一些最初扩展性比较差的设计,也会无能为力。这个在下文中关于ReentrantLock的介绍中也可以看到。
在这个版本中,正式废除了这样三个方法:stop()、suspend()和resume()。
在这个JDK版本中,引入线程变量ThreadLocal这个类:
JDK 1.4
在2002年4月发布的JDK1.4中,正式引入了NIO。JDK在原有标准IO的基础上,提供了一组多路复用IO的解决方案。
通过在一个Selector上挂接多个Channel,通过统一的轮询线程检测,每当有数据到达,触发监听事件,将事件分发出去,而不是让每一个channel长期消耗阻塞一个线程等待数据流到达。所以,只有在对资源争夺剧烈的高并发场景下,才能见到NIO的明显优势。
相较于面向流的传统方式这种面向块的访问方式会丢失一些简易性和灵活性。
JDK 5.0
2004年9月起JDK 1.5发布,并正式更名到5.0。有个笑话说,软件行业有句话,叫做“不要用3.0版本以下的软件”,意思是说版本太小的话往往软件质量不过关——但是按照这种说法,JDK的原有版本命名方式得要到啥时候才有3.0啊,于是1.4以后通过版本命名方式的改变直接升到5.0了。
Executors
用来创建各种线程池。newFixedThreadPool newCachedThreadPool 、newSingleThreadExecutor ScheduledExecutorService 等线程池 用于优化线程的性能
Callable和Futrue
ExecutorService还可以调用submit(Callable) 方法执行一个任务,在call() 方法中定义任务内容并且返回一个值 submit方法会返回一个Future对象,在任务执行结束时,Future对象的get()方法可以得到call() 方法返回的值,如果调用get()方法时任务未完成,那么线程将阻塞等待任务完成
Futrue的实现原理类似于java 的回调函数 submit后直接返回future对象,在后台new一个新的线程进行访问数据,获取数据后调用函数返回数据
Semaphore 可以在多个线程并发时指定同时执行线程的个数。 使用构造函数Semaphore(int)创建信号灯,指定并发个数。 在线程开始执行后调用acquire()方法占用一个并发数,线程结束时使用release()释放一个并发数。
Exchanger 可以在多线程并发时设置等待,等待另一线程运行到指定位置,并且交换数据。 使用构造函数Exchanger()创建对象。
在线程开始之后可以使用exchange(Object)方法控制当前线程等待,直到有另一个线程也调用该方法时交换数据,并继续执行。
ReentrantLock ReentrantReadWriteLock 实现lock接口 可以自主的对锁实现更精细的操作(java编程思想里面不推荐使用,除非并发编程特别厉害的可以使用,因为自主控制并发可能出现自己意想不到不到的问题,一般还是推荐synchronized关键字,synchronized在每个版本的逐步优化中性能已经跟lock差不多,而且后期还会有优化)
Condition Lock的newCondition()方法可以获取一个Condition,Condition对象拥有和Object类似
的wait()、notify()、notifyAll()功能,分别为await()、signal()、signalAll() 区别是如果使用synchronized同步时只能使用锁对象来wait()、notify()、notifyAll(),这时notify()方法只能唤醒随机一个线程 而使用Condition时可以创建多个分支对象,让线程在不同的分支上等待,并且可以唤醒指定分支上的线程
JDK 5.0不只是版本号命名方式变更那么简单,对于多线程编程来说,这里发生了两个重大事件,JSR 133和JSR 166的正式发布。
JSR 133
JSR 133重新明确了Java内存模型,事实上,在这之前,常见的内存模型包括连续一致性内存模型和先行发生模型。
对于连续一致性模型来说,程序执行的顺序和代码上显示的顺序是完全一致的。这对于现代多核,并且指令执行优化的CPU来说,是很难保证的。而且,顺序一致性的保证将JVM对代码的运行期优化严重限制住了。
但是JSR 133指定的先行发生(Happens-before)使得执行指令的顺序变得灵活:
在同一个线程里面,按照代码执行的顺序(也就是代码语义的顺序),前一个操作先于后面一个操作发生
对一个monitor对象的解锁操作先于后续对同一个monitor对象的锁操作
对volatile字段的写操作先于后面的对此字段的读操作
对线程的start操作(调用线程对象的start()方法)先于这个线程的其他任何操作
一个线程中所有的操作先于其他任何线程在此线程上调用 join()方法
如果A操作优先于B,B操作优先于C,那么A操作优先于C
而在内存分配上,将每个线程各自的工作内存(甚至包括)从主存中独立出来,更是给JVM大量的空间来优化线程内指令的执行。主存中的变量可以被拷贝到线程的工作内存中去单独执行,在执行结束后,结果可以在某个时间刷回主存:
但是,怎样来保证各个线程之间数据的一致性?JLS给的办法就是,默认情况下,不能保证任意时刻的数据一致性,但是通过对synchronized、volatile和final这几个语义被增强的关键字的使用,可以做到数据一致性。
JSR 166
JSR 166的贡献就是引入了java.util.concurrent这个包。前面曾经讲解过AtomicXXX类这种原子类型,内部实现保证其原子性的其实是通过一个compareAndSet(x,y)方法(CAS),而这个方法追踪到最底层,是通过CPU的一个单独的指令来实现的。这个方法所做的事情,就是保证在某变量取值为x的情况下,将取值x替换为y。在这个过程中,并没有任何加锁的行为,所以一般它的性能要比使用synchronized高。
使用immutable对象的拷贝(比如CopyOnWrite)也可以实现无锁状态下的并发访问。举一个简单的例子,比如有这样一个链表,每一个节点包含两个值,现在我要把中间一个节点(2,3)替换成(4,5),不使用同步的话,我可以这样实现:
构建一个新的节点连到节点(4,6)上,再将原有(1,1)到(2,3)的指针指向替换成(1,1)到(4,5)的指向。
除了这两者,还有很多不用同步来实现原子操作的方法,比如我曾经介绍过的Peterson算法。
以下这个表格显示了JDK 5.0涉及到的常用容器:
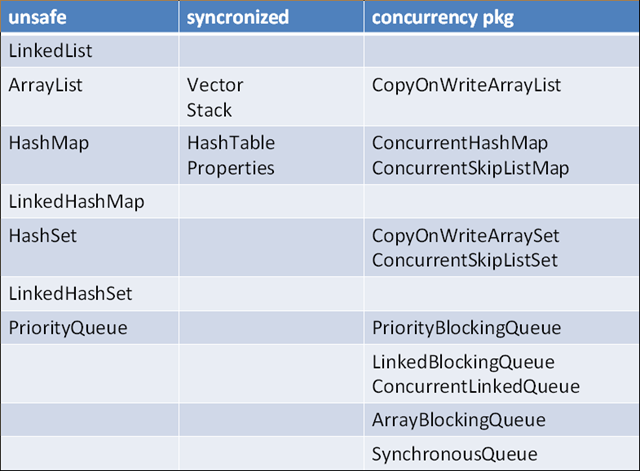
其中:
unsafe这一列的容器都是JDK之前版本有的,且非线程安全的;
synchronized这一列的容器都是JDK之前版本有的,且通过synchronized的关键字同步方式来保证线程安全的;
concurrent pkg一列的容器都是并发包新加入的容器,都是线程安全,但是都没有使用同步来实现线程安全。
再说一下对于线程池的支持。在说线程池之前,得明确一下Future的概念。Future也是JDK 5.0新增的类,是一个用来整合同步和异步的结果对象。一个异步任务的执行通过Future对象立即返回,如果你期望以同步方式获取结果,只需要调用它的get方法,直到结果取得才会返回给你,否则线程会一直hang在那里。Future可以看做是JDK为了它的线程模型做的一个部分修复,因为程序员以往在考虑多线程的时候,并不能够以面向对象的思路去完成它,而不得不考虑很多面向线程的行为,但是Future和后面要讲到的Barrier等类,可以让这些特定情况下,程序员可以从繁重的线程思维中解脱出来。把线程控制的部分和业务逻辑的部分解耦开。
JDK 6.0
JDK 6.0对锁做了一些优化,比如锁自旋、锁消除、锁合并、轻量级锁、所偏向等。
CyclicBarrier是JDK 6.0新增的一个用于流程控制的类,这个类可以保证多个任务在并行执行都完成的情况下,再统一执行下一步操作:
还有一个类似的类是CountDownLatch(使用倒数计数的方式),这样的类出现标志着,JDK对并发的设计已经逐步由微观转向宏观了,开始逐步重视并发程序流程,甚至是框架上的设计,这样的思路我们会在下文的JDK 7.0中继续看到。
两者的区别CyclicBarrier是对多个线程的控制,即多个任务全部执行完成后,多个线程再统一执行下一步操作,CountDownLatch是对单个线程,即多个线程全部完成后,由一个线程去执行下一步操作。
JDK 7.0
2011年的JDK 7.0进一步完善了并发流程控制的功能,比如fork-join框架:
把任务分解成不同子任务完成;比如Phaser这个类,整合了CyclicBarrier和CountDownLatch两个类的功能,但是提供了动态修改依赖目标的能力;还有NIO2的新开放特性。这里不详细介绍了。
JDK 8.0
LongAdder和AtomicLong类似的使用方式,但是性能比AtomicLong更好。
LongAdder与AtomicLong都是使用了原子操作来提高性能。但是LongAdder在AtomicLong的基础上进行了热点分离,热点分离类似于有锁操作中的减小锁粒度,将一个锁分离成若干个锁来提高性能。在无锁中,也可以用类似的方式来增加CAS的成功率,从而提高性能。
CompletableFuture实现CompletionStage接口(40余个方法),大多数方法多数应用在函数式编程中。并且支持流式调用
CompletableFuture是Java 8中对Future的增强版
StampedLock是ReadWriteLock的一个改进。StampedLock与ReadWriteLock的区别在于,StampedLock认为读不应阻塞写,StampedLock认为当读写互斥的时候,读应该是重读,而不是不让写线程写。这样的设计解决了读多写少时,使用ReadWriteLock会产生写线程饥饿现象。
所以StampedLock是一种偏向于写线程的改进。
JDK 9.0
甲骨文宣布原定于2017年3月推出的Java 9将再延至2017年7月发布,主要原因是Java 9内置的模组化架构Jigsaw需要更长的时间来开发。
改善锁争用机制
锁争用限制了许多Java多线程应用性能,新的锁争用机制改善了Java对象监视器的性能,并得到了多种基准测试的验证(如Volano),这类测试可以估算JVM的极限吞吐量。实际中, 新的锁争用机制在22种不同的基准测试中都得到了出色的成绩。如果新的机制能在Java 9中得到应用的话, 应用程序的性能将会大大提升。更多相关信息参见JEP143。
参考博客:http://blog.csdn.net/findmyself_for_world/article/details/41981355
- java-多线程发展史
- java 多线程的发展史
- java多线程发展史
- java发展史
- java发展史
- Java 发展史
- Java发展史
- Java发展史
- Java发展史
- Java发展史
- Java发展史
- Java发展史
- java发展史
- Java 发展史
- Java发展史
- Java发展史
- JAVA发展史
- JAVA发展史
- js 获取所有被选中复选框的值
- Codeforces 325D Reclamation 题解
- 几个maven仓库地址,直接贴到pom.xml用
- hdu1248 (解题报告)
- jenkins:使用 Jenkins 实现持续集成 (Android)
- java多线程发展史
- 'Spawn scene object not found 1' Error 解决方法
- databinding数据不能进行动态绑定方法
- 职场3大涨工资技能,今天教你其中1个。
- java笔记(一):String,StringBuffer,StringBuilder
- Java中普通代码块,构造代码块,静态代码块区别及代码示例
- 欢迎使用CSDN-markdown编辑器
- java实现连续子数组的最大和(子向量的长度至少是1)
- Shiro源码分析----认证流程


