HDFS中的NameNode和DataNode
来源:互联网 发布:c语言编译器安卓中文版 编辑:程序博客网 时间:2024/05/16 00:58
HDFS集群中以Master-Slave模式运行,主要有两类节点:一个Namenode节点(即master)和多个Datanode节点。Namenode管理文件系统的Namespace.他维护着文件系统树以及文件树中所有的文件和文件夹的元数据。
hdfs架构图: 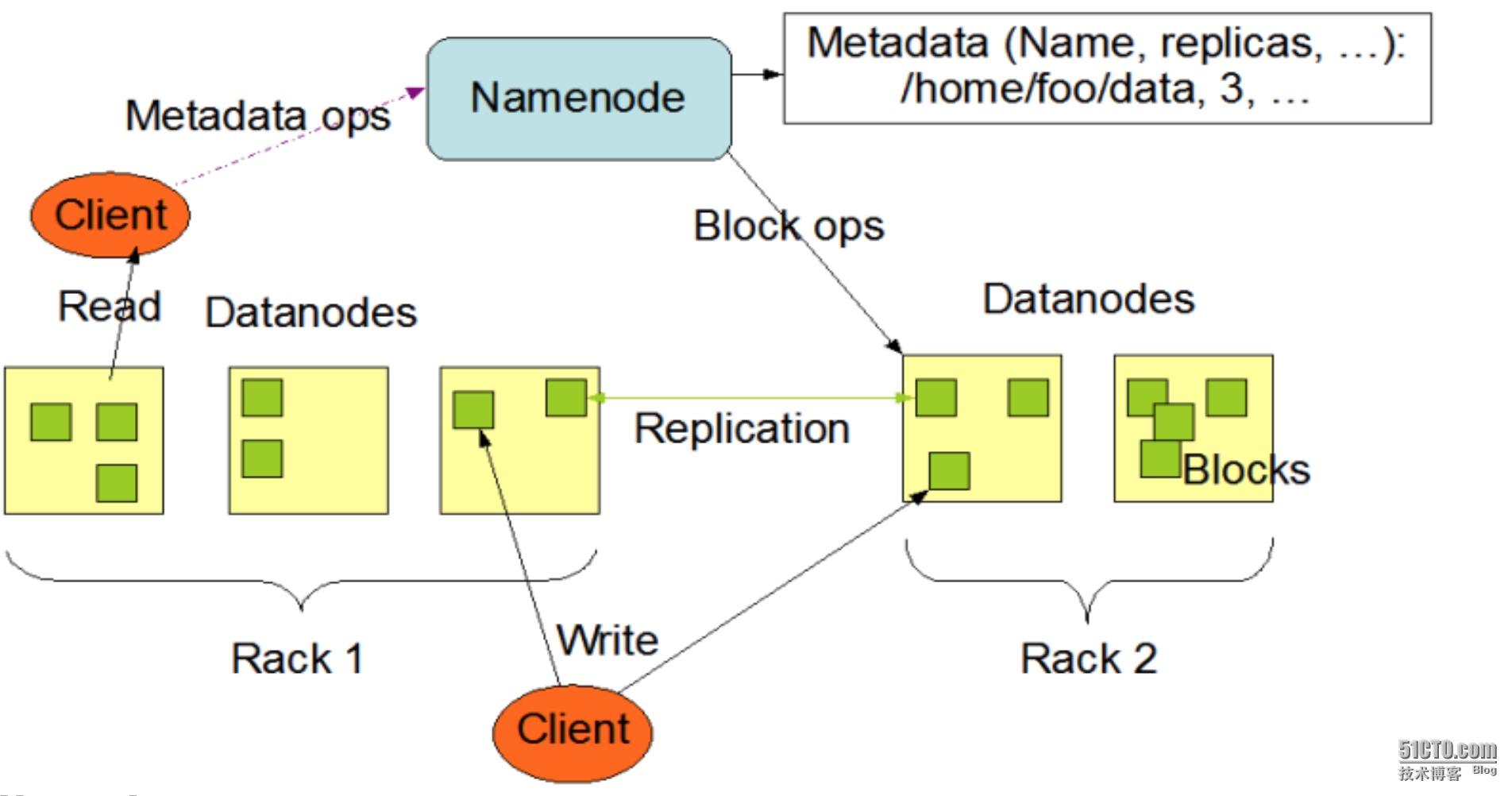
Namenode:
Namenode管理文件系统的Namespace。它维护着文件系统树以及文件树中所有的文件和文件夹的元数据(Metadata).管理这些信息的文件有两个,分别是Namespace镜像文件(Namespace image)和操作日志文件(edit log), 这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地磁盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是它并不持久化存储这些信息,因为这些信息会在系统重启时从数据及节点重建。
Namenode结构抽象图: 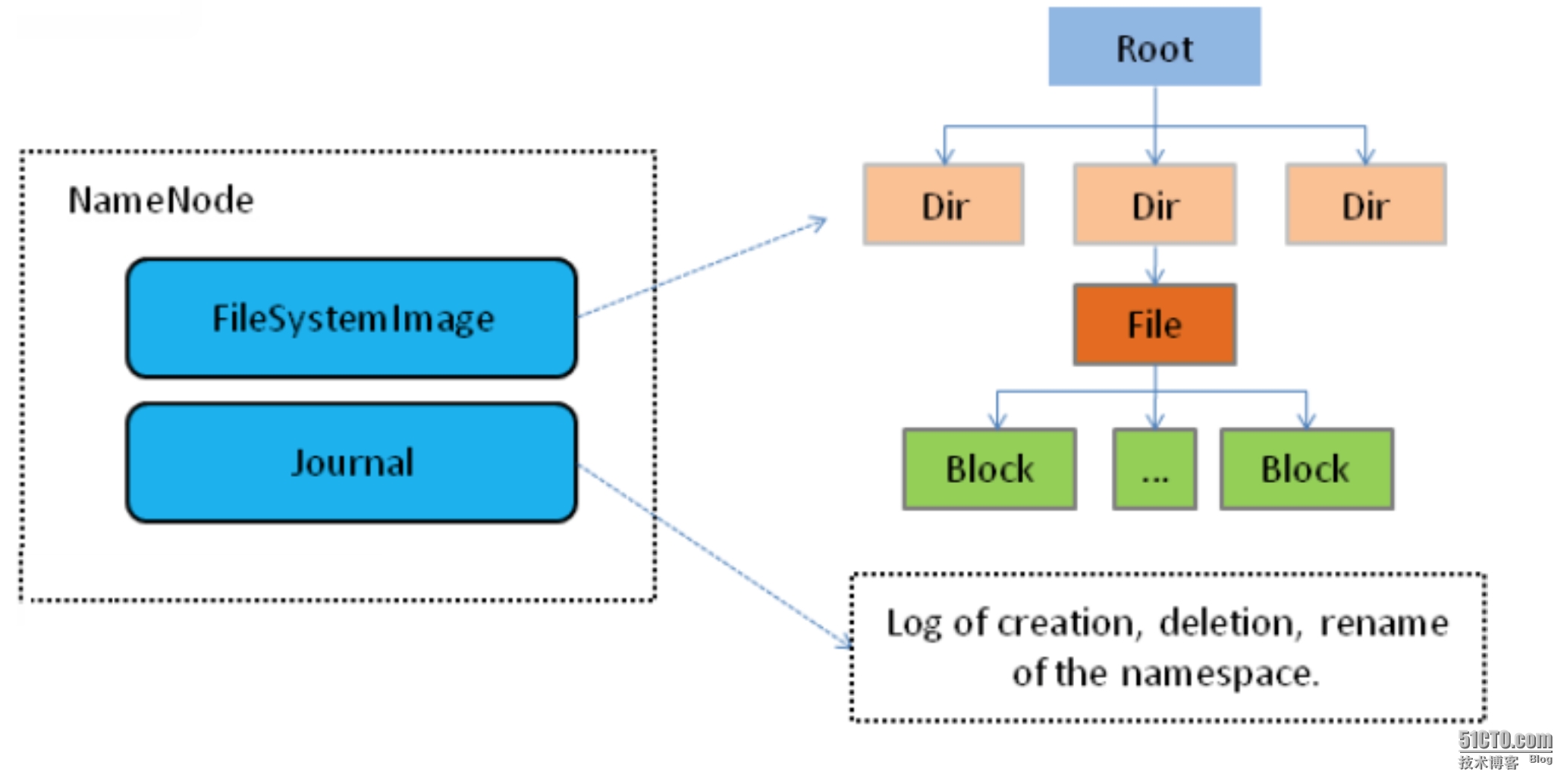
客户端代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一系列的文件系统接口,因此我们在编程时,几乎无需知道datanode和namenode,即可完成我们所需要的功能。
Datanode:
Datanode是文件系统的工作节点,他们根据客户端或者namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表.
Namenode容错机制:
没有了Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种容错机制。
第一种方式:将持久化存储在本地磁盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将它的持久化状态写道不同的文件系统中。这种写操作时同步并且是原子化的。比较常见的配置是在将持久化状态写道本地磁盘的同时,也写到远端挂载的网络文件系统。
第二种方式:是运行一个辅助的Namenode(Secondary Namenode).实时上Secondary Namenode并不能被用作Namenode它的主要作用是定期将namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变的过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并nameSpace镜像的一个备份,如果namenode宕机了,这个备份就可以用上。但是辅助namenode总是落后于namenode,所以在namenode宕机时,数据丢失时不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的namenode 的元数据文件来使用,把nfs中的namenode元数据文件,拷贝到辅助namenode并把辅助namenode作为namenode来运行。
转自
深入理解nameNode和dataNode
- HDFS中的NameNode 和 DataNode
- HDFS中的Namenode和Datanode
- HDFS中的Namenode和Datanode
- HDFS中的NameNode和DataNode
- HDFS中的Namenode和Datanode
- Hadoop原理---HDFS中的NameNode和DataNode
- HDFS的namenode和datanode
- HDFS namenode 和 datanode功能
- hadoop的hdfs中的namenode和datanode知识总结
- 《hadoop学习》关于hdfs中的namenode和datanode详解
- Hdfs(NameNode&DataNode)和Hive迁移总结
- HDFS:NameNode、DataNode、SecondaryNameNode
- HDFS:NameNode、DataNode、SecondaryNameNode
- HDFS:NameNode概述,DataNode 概述
- Hadoop之HDFS架构(NameNode和DataNode)
- NameNode 和 DataNode
- NameNode和DataNode启动
- Namenode 和 Datanode
- Retrofit使用 addInterceptor和addNetworkInterceptor的区别
- 整数排序 II
- pxe的基础用法
- 自定义View(带进度的圆形进度条)
- Jackson 框架,轻易转换JSON
- HDFS中的NameNode和DataNode
- 算第几天
- 面向对象设计之五大原则
- 【算法】排序 (三):二叉树排序&基于散列排序(C++实现)
- java-杨辉三角
- 机器学习利用Anaconda搭建Python科学计算环境
- NetBeans+Xdebug调试php代码
- poj 3070 Fibonacci
- 1004. Counting Leaves (30)


