Namenode 和 Datanode
来源:互联网 发布:淘宝钻石等级可以买吗 编辑:程序博客网 时间:2024/05/29 17:13
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
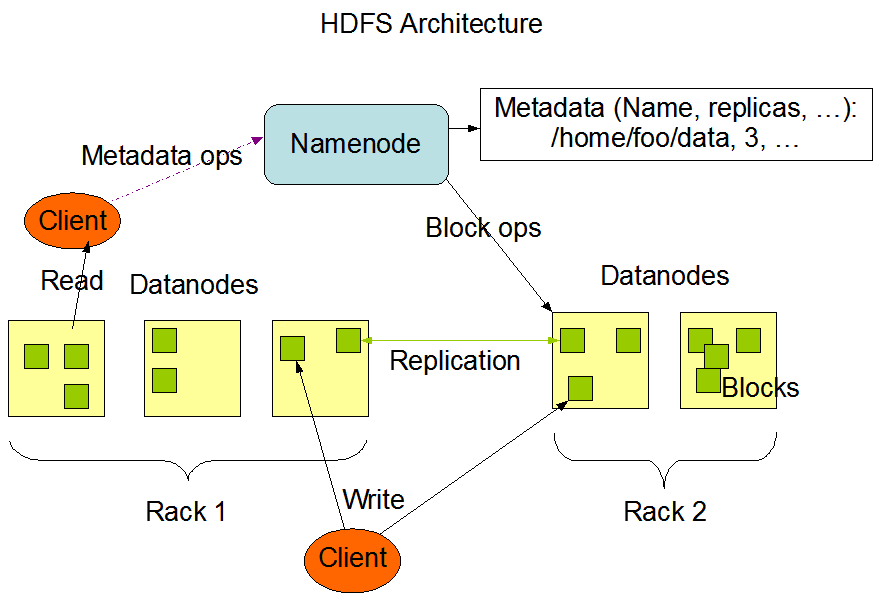
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。
由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来。应用程序可以设置HDFS保存的文件的副本数目。文件副本的数目称为文件的副本系数,这个信息也是由Namenode保存的。数据复制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,除了最后一个,所有的数据块都是同样大小的。为了容错,文件的所有数据块都会有副本。每个文件的数据块大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
- NameNode 和 DataNode
- NameNode和DataNode启动
- Namenode 和 Datanode
- NameNode和DataNode通信机制
- HDFS的namenode和datanode
- HDFS中的NameNode 和 DataNode
- HDFS中的Namenode和Datanode
- HDFS中的Namenode和Datanode
- Hadoop启动namenode和datanode
- 简单认识namenode和datanode
- HDFS中的NameNode和DataNode
- HDFS namenode 和 datanode功能
- HDFS中的Namenode和Datanode
- 深入理解NameNode和DataNode
- hadoop namenode和datanode无法启动
- DataNode和Namenode无法正常启动
- namenode和datanode无法启动问题
- Hadoop获得集群NameNode和DataNode状态
- [JZOJ100019]A
- jqgrid获取全部数据
- 输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
- eclipse背景设置什么颜色缓解眼睛疲劳之一
- ierport JasperReport 日期类型java.sql.Timestamp判断是否为空 ($F{date}==null?"":String.valueOf($F{date}.getYear
- Namenode 和 Datanode
- ML_W8_Anomaly Detection_Density Estimation
- LeetCode: Kth Largest Element in Array
- Spring Data MongoDB :基本文档查询
- 高性能可扩展mysql(用户模块设计,分区表使用)
- hibernate session操作
- eCos打印UTC时间
- JAVA调试技巧
- 【SpringMVC】@Controller和@RequestMapping注解说明


