因为有它,Spark集群的交互操作变得更简单
来源:互联网 发布:千鱼淘宝店铺复制 编辑:程序博客网 时间:2024/04/29 15:37
Spark 2.X开发的一个动机是让它可以触及更广泛的受众,特别是缺乏编程技能但可能非常熟悉SQL的数据分析师或业务分析师。因此,Spark 2.X现在比以往更易使用。
在以前的Spark 1.x版本中,主要使用RDD(弹性分布式数据集),所有的操作都是基于RDD的转化,而在Spark 2.x中,主要基于DataFrame操作,所有的操作都是基于dataframe进行操作。
在本文中,我将重点介绍使用fea spk包如何进行spark的dataframe操作,为以后进行fea大数据分析做一下铺垫。使用这种方式的优势在于,可以利用spark集群的分布式原理,对大规模的数据进行分析和处理,步骤如下:
1、 创建spk连接
在spark 2.X的操作里面,使用SparkSession为Spark集群提供了唯一的入口点。val spk= SparkSession.builder. master("local") .appName("spark session example") .getOrCreate()
而使用fea spk包,需要创建的spk连接如下
spk = @udf df0@sys by spk.open_spark
2. fea spk dataframe
fea spk操作有2种dataframe,一种是pandas的dataframe,可以直接在fea里面运行dump查看。
另外一种是spark的dataframe,它能够进行各种各样的spark算子操作,比如group,agg等。
spark dataframe需要转换为pandas的dataframe才能运行dump命令查看,转换的原语如下:
pd= @udf df by spk.to_DF #spark dataframe df转换为pandas dataframe pd
dump pd
#可以直接使用dump命令查看
sdf= @udf spk,pd by spk.to_SDF
#将pandas dataframe pd转换为spark dataframe sdf,以便进行spark的各种操作。
3. 使用spk连接读取数据
fea spk包支持各种各样的数据源。如,hive,mongodb,text,avro , json, csv , parquet,mysql,oracle等数据源,下面列举几个比较常见的数据源来进行演示。
csv数据源
a.csv文件格式如下:
id,hash
1,ssss
2,333
3,5567
使用如下命令,连接读取数据
df= @udf spk by spk.load_csv with (header,/data/a.csv)
pd= @udf df by spk.to_DF
dump pd

Mysql数据源
Mysql中student_infos表数据如下:
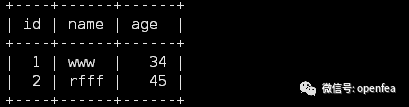
使用如下命令,连接读取数据
df1= @udf spk by spk.load_mysql with (student_infos)
pd= @udf df1 by spk.to_DF
dump pd

4. 使用spk包 来进行groupby,agg操作
d.csv数据如下
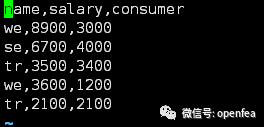
df2= @udf spk by spk.load_csv with (header,/data/d.csv)
df3= @udf df2 by spk.group with (name)
#对df2表的name字段进行group操作
df4= @udf df3 by spk.agg with (salary:avg,consumer:sum)
#对group之后的df3表的salary字段求均值,consumer字段进行求和操作
pd= @udf df4 by spk.to_DF
dump pd

![]()
5 使用spk包来进行join操作
b.csv数据如下
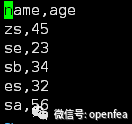
c.csv数据如下

df5= @udf spk by spk.load_csv with (header,/data/b.csv)
df6= @udf spk by spk.load_csv with (header,/data/c.csv)
df7= @udf df5,df6 by spk.join with (name:name1,inner)
#按照df5表的name字段,df6表的name1字段进行join内连接
pd= @udf df7 by spk.to_DF
dump pd

6. 使用spk包给表的一列或者多列重命名
对于上面的df7表,把name命名为name1,age命名为age1
df8=@udf df7 by spk.rename with (name:name1,age:age1)
pd=@udf df8 by spk.to_DF
dump pd

7 使用spk包对表按照某种条件进行过滤
以上面的df6表为例,统计income字段大于3000
df9= @udf df6 by spk.filter with (income>3000)
pd=@udf df9 by spk.to_DF

8. 使用spk包将表注册成能够使用SQL语句的表
以上面的df7表为例进行说明,将表注册为employee表
a= @udf df7 by spk.df_table with (employee)
使用SQL语句查询注册的表,返回DF
df10= @udf spk by spk.df_sql with (select * from employee where income>2000)
pd=@udf df10 by spk.to_DF
dump pd

9 将表保存为parquet文件格式
以df10为例,保存目录为hdfs的目录/user/root/employee.parquet
b=@udf df10 by spk.save_parquet with (employee.parquet)
此外spk还有很多原语,暂时列举一部分,下面进行spk包机器学习的演示。
使用spk包进行机器学习,真正实现了分布式机器学习的思想,替代了原始的单机版本的机器学习,大大提高了机器学习的速度和吞吐量。目前spk包支持的机器学习还是比较完善的,包括逻辑回归,决策树,随机森林,贝叶斯,神经网络,Kmeans等算法。
10.使用随机森林进行分类
m1表的内容如下:
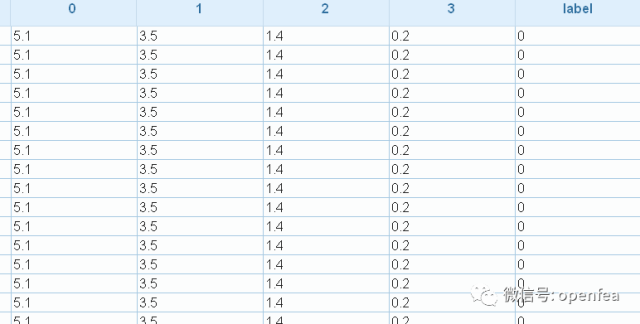
前面4个是特征,后面label为标签,有3种情况,0,1,2,下面使用随机森林算法进行模型的训练。注意,使用spk包进行机器学习,要求表的字段为double类型,所以要先进行转换。
m1= @udf m1 by spk.ML_double
md1= @udf m1 by spk.ML_rf with (maxDepth=5, numTrees=10)
md1是训练出的随机森林模型
下面进行预测,预测的表为m2,数据具有4个特征,不包括标签列,表格式如下
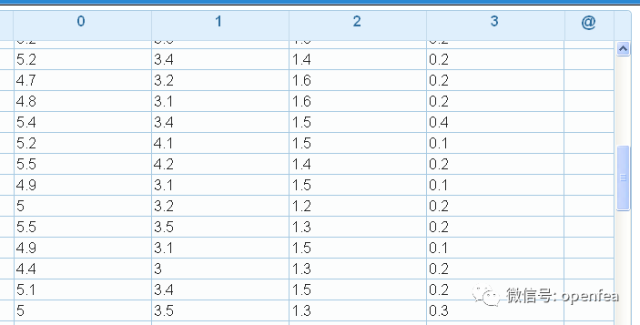
r1= @udf m2 by spk.ML_predict with (md1@public)
pd=@udf r1 by spk.to_DF
dump pd
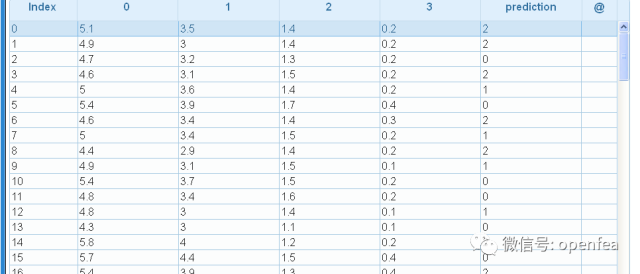
prediction这列就是预测的结果
下面对模型进行打分
s1= @udf m1 by spk.ML_score with (md1@public)
dump s1

- 因为有它,Spark集群的交互操作变得更简单
- 陪父母旅行,它让你的心意更全,因为有你在身旁
- 哪些领域的应用因为大数据变得更聪明?
- 因为它有一个 DefiningQuery,而 <ModificationFunctionMapping> 元素中没有支持当前操作的 <InsertFunction> 元素
- 因为它有一个 DefiningQuery,而 <ModificationFunctionMapping> 元素中没有 支持当前操作的 <DeleteFunction> 元素
- 中兴的想法因为4G的到来变得更具可能性
- 2016年让开发工作变得更简单的小事
- AlertController工具类的封装,让AlertController变得更简单
- 查找OPNET函数,修改OPNET的帮助文档,让它变得更直接更好用
- 无法更新 EntitySet“XXX”,因为它有一个 DefiningQuery,而 <ModificationFunctionMapping> 元素中没有支持当前操作的
- 无法更新 EntitySet“***”,因为它有一个 DefiningQuery,而 元素中没有支持当前操作的***元素。
- 如何让地图变得更有吸引力
- 如何让地图变得更有吸引力
- 扩展jQuery Media Plugin,使它变得更完整
- 让管理变得更简单(17)
- 让管理变得更简单(16)
- 让管理变得更简单(15)
- 让管理变得更简单(14)
- RJ45隔离变压器作用
- C++函数重载
- Andoid自定义View的OnMeasure详解和自定义属性
- Git Pull Push 避免用户名和密码方法--雷锋
- 数据库设计的基本步骤
- 因为有它,Spark集群的交互操作变得更简单
- bzoj1807: [Ioi2007]Pairs 彼此能听得见的动物对数
- 图书管理系统(链表)
- 文章标题
- Happy Number
- 面试题6:重建二叉树
- latex入门第6课——LaTeX中的特殊字符
- 关于Java多线程--------(2,线程常用操作方法)
- Git常用命令


