三大机器翻译技术的high-level概述:Neural, Rule-Based and Phrase-Based Machine Translation
来源:互联网 发布:监控系统怎么连接网络 编辑:程序博客网 时间:2024/06/06 07:15
http://blog.systransoft.com/how-does-neural-machine-translation-work/
In this issue of step-by-step articles, we explain how neural machine translation (NMT) works and compare it with existing technologies: rule-based engines (RBMT) and phrase-based engines (PBMT, the most popular being Statistical Machine Translation – SMT).
The results obtained from Neural Machine Translation are amazing, in particular, the neural network’s paraphrasing. It almost seems as if the neural network really “understands” the sentence to translate. In this first article, we are interested in “meaning,” that which gives an idea of the type of semantic knowledge the neural networks use to translate.
Let us start with a glimpse of how the 3 technologies work, the different steps of each translation process and the resources that each technology uses to translate. Then we will take a look at a few examples and compare what each technology must do to translate them correctly.
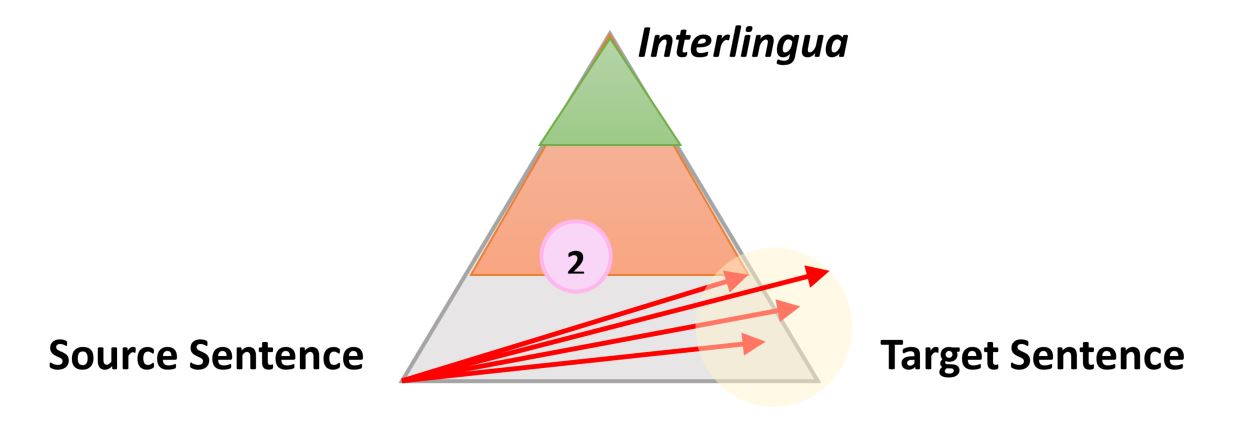
One very simple but still useful representation of any automatic translation process is the following triangle which was introduced by French Researcher B. Vauquois in 1968[1].

The triangle represents the process of transforming the source sentence into the target sentence in 3 different steps.
The left side of the triangle characterizes the source language; the right side the target language. The different levels inside the triangle represent the depth of the analysis of the source sentence, for instance the syntactic or semantic analysis. We now know that we cannot separate the syntactic and semantic analysis of a given sentence, but still the theory is that you can dig deeper and deeper into the analysis of a given sentence. The first red arrow represents the analysis of the sentence in the source language. From the actual sentence, which is just a sequence of words, we can build an internal representation corresponding to how deep we can analyze the sentence.
For instance, on one level we can determine the parts of speech of each word (noun, verb, etc.), and on another we can connect words: for instance, which noun phrase is the subject of which verb.
When the analysis is finished, the sentence is “transferred” by a second process into a representation of equal or slightly less depth in the target language. Then, a third process called “generation” generates the actual target sentence from this internal representation, i.e. a meaningful sequence of words in the target language. The idea of using a triangle is that the higher/deeper you analyze the source language, the smaller/simpler the transfer phase. Ultimately, if we could convert a source language into a universal “interlingua” representation during this analysis, then we would not need to perform any transfer at all – and we would only need an analyzer and generator for each language to translate from any language to any language.
This is the general idea and explains intermediate representation, if any exists, and the mechanisms involved to go from one step to the next. More importantly, this model describes the nature of the resources that this mechanism uses. Let us illustrate how this idea works for the 3 different technologies using a very simple sentence: “The smart mouse plays violin.”
Rule-Based Machine Translation
Rule-Based machine translation is the oldest approach and covers a wide variety of different technology. However, all rule-based engines generally share the following characteristics:
- The process strictly follows the Vauquois triangle and the analysis side is often very advanced, while the generation part is sometimes reduced to the minimal;
- All 3 steps of the process use a database of rules and lexical items on which the rules apply;
- These rules and lexical items are « readable » and can be modified by linguist/lexicographer.
For instance, the internal representation of our sentence can be the following:
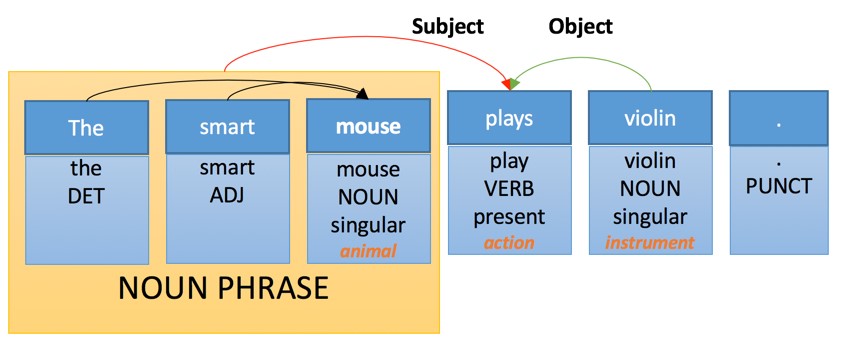
We see a few different levels of analysis:
- Part of speech tagging: each word is assigned a “part of speech” which is a grammatical category
- Morphological analysis: “plays” is recognized as inflected third person present form of the verb “play”
- Semantic analysis: some words are assigned a semantic category – for instance “violin” is an instrument
- Constituent analysis: some words are grouped into constituent – “the smart mouse” is a noun phrase
- Dependency analysis: words and phrases are connected with “links”, here we identify the subject and the object of the main verb “play”
Transfer of such a structure will use rules and lexical transformations such as:

Application of these rules on the previous example will generate the target language representation of the sentence:
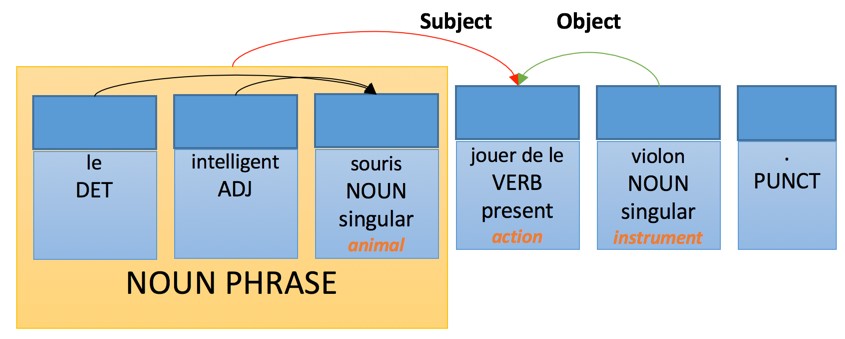
Then French generation rules will define:
- The adjective in a noun phrase follow the nouns – with a few listed exceptions
- A determiner agrees in number and gender with the noun it modifies
- An adjective agrees in number and gender with the noun it modifies
- The verb agrees with the subject
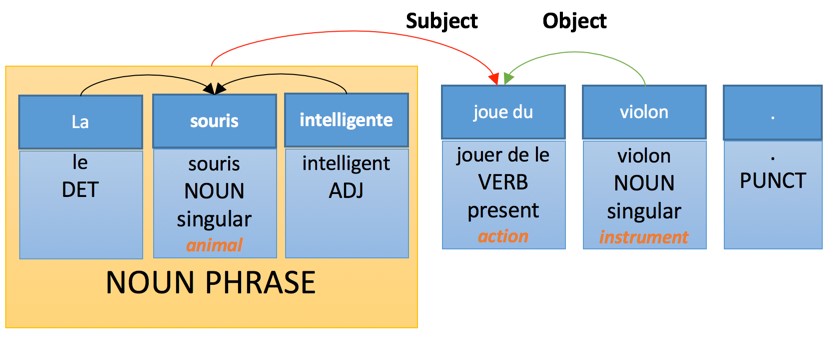
Ideally, this analysis would generate the following translation:
Phrase-Based Machine Translation
Phrase-Based Machine Translation is the simplest and most popular version of statistical machine translation. As of today, it is still the main paradigm used behind major online translation services.
Technically-speaking, phrase-based machine translation does not follow the process defined by Vauquois. Not only is there no analysis or generation, but more importantly the transfer part is not deterministic. This is to say that the engine can generate multiple translations for one source sentence, and the strength of the approach resides in its ability to select the best one.
For that the model is based on 3 main resources:
- A phrase-table which produces translation option and their probabilities for “phrases” (sequences of words) on the source language
- A reordering table indicating how words can be reordered when transferred from source language to target language
- A language model which gives probability for each possible word sequence in the target language
Hence, from the source sentence, the following table will be built (in real, there would be many more options associated to each word):
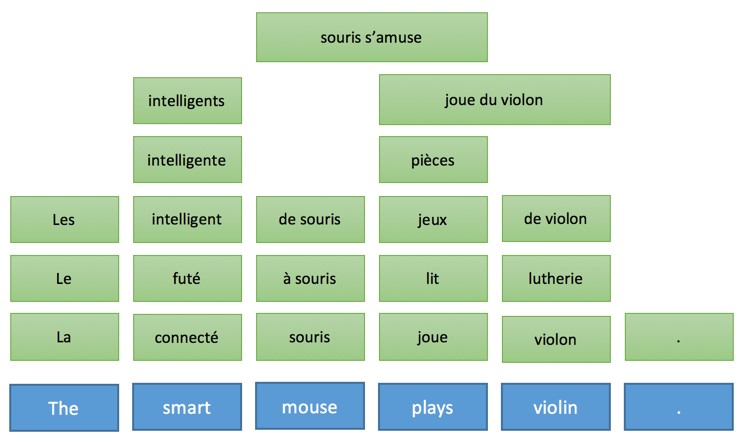
From the table, thousands of possible translations for the sentence is generated, such as the following:
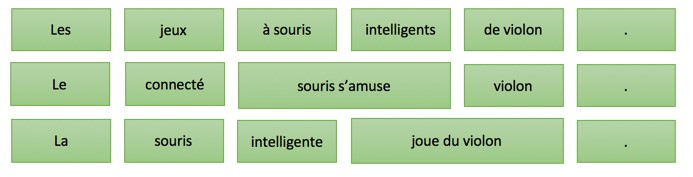
However, thanks to smart probability calculations and smarter search algorithms, only the most likely translation will be explored and the best one kept.
In this approach, the target language model is very important, and we can get an idea simply by doing online search:

Intuitively, search algorithms prefer to use sequences of words that are probable translations of the source words, with a probable reordering scheme, and generate sequences of words in the target language with a high probability.
In this approach, there is no implicit or explicit linguistic or semantic knowledge. Many variants have been proposed and some show improvements, but to our knowledge and from what we can observe, the main online translation engines use the base mechanism.
Neural Machine Translation
The neural machine translation approach is radically different from the previous ones but can be classified as following using the Vauquois Triangle:
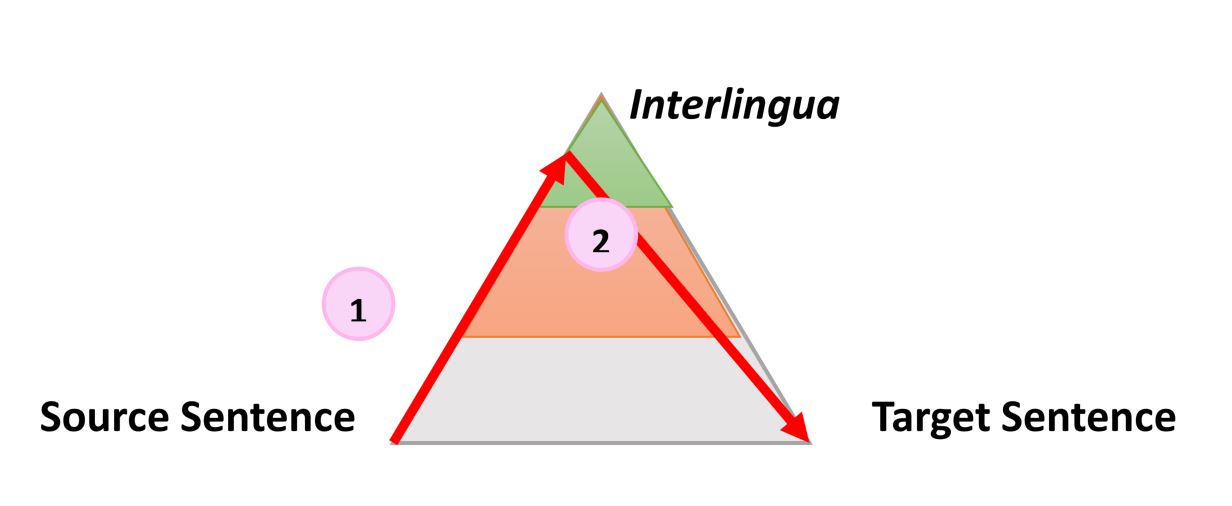
With the following specificities:
- The “analysis” is called encoding and the result of the analysis is a mysterious sequence of vectors
- The “transfer” is called decoding and directly generates the target form without any generation phase. This is not a strict constraint, and could possibly be evolving, but it is how the baseline technology works.
To decompose the process there are 2 separates phases. In the first one, each word of the source sentence passes through the “encoder” and generates what we call a “source context” using the current word and the previous source context:
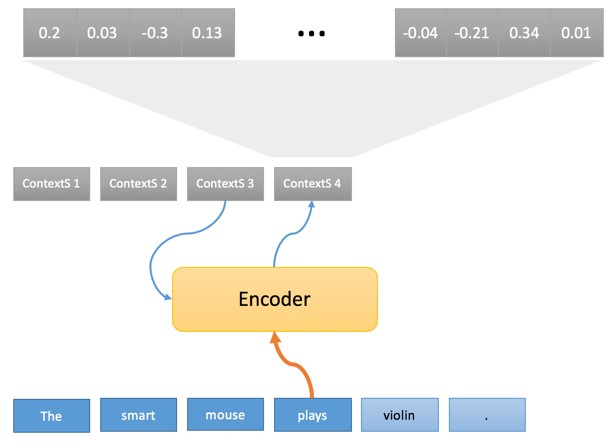
The sequence of source contexts (ContextS 1, … ContextS 5) is the internal representation of the source sentence on the Vauquois triangle and as mentioned above it is a sequence of float numbers (typically 1000 float numbers associated to each source word). For now, we won’t discuss how this transformation is performed and how the encoder works, but we would like to point out that what is particularly interesting is the initial transformation of words in the vector of floats.
This is actually a building block of the technology, and as is the case in a rule-based system where each word is first looked up in a monolingual dictionary, the first step of the encoder is to look up each source word in a word embedding table. Part of how meanings are represented in neural machine translation are in the word embedding.
We don’t exactly know how word embedding are constituted. Another article will dissect word embeddings in more detail, but the idea is as simple as organizing objects in space.
Coming back to the translation process, the second step is represented as follows:
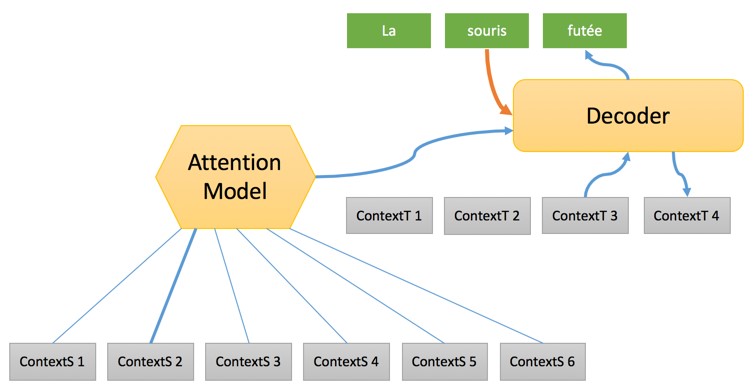
Now the full sequence of “Source Context” is generated, and one by one, the target words are generated using:
- The “Target Context” generated together with the previous word, and which represents some information about the status of the translation;
- A weighted “Source Context” which is a mix of the different source contexts by a specific model called Attention Model – we will discuss Attention Models further in another article. Essentially, Attention Models select the source word to translate at any step of the process;
- The previously translated word using a word embedding to convert the actual word into a vector that the decoder can actually handle.
The translation will end when the decoder “decides” to generate an end-of-sentence special word.
The complete process is undeniably mysterious, and we will need several articles to dig into the different components. The key point to remember is that the translation process of a Neural Machine Translation engine follows the same sequence of operations as a rule-based engine, however, the nature of the operations and the objects manipulated are completely different – and the starting point of the conversion of words into vectors is the word embedding – and this is good enough to get an idea of how the following examples work.
Comparative Translation Examples
Let us look at some translation examples and discuss what we have highlighted today on why/how some examples don’t work for the different technologies. We have selected several polysemic verbs in English and are looking at English-French translations.

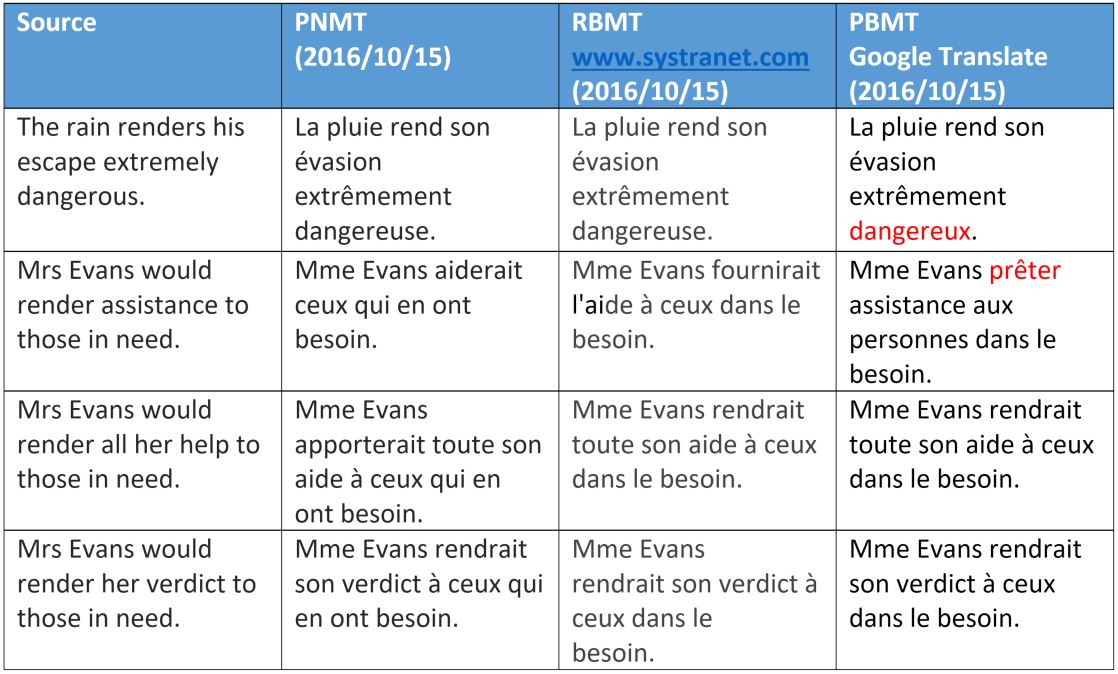
What we can see is PBMT mainly interprets “render” as a meaning – except for the very idiomatic “render assistance”. This can be easily explained – the selection of the meaning depends either on a long distance check on the sentence structure, or on the semantic category of the object.
For NMT, the fact that it correctly processes “help” and “assistance” in a similar way shows some benefit of word embedding, plus the apparent ability to get some long distance syntactic information that we will cover in another article.

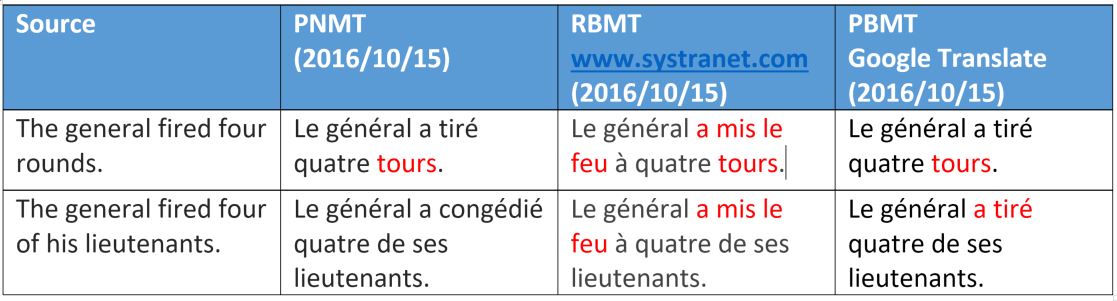
Here again, the fact that the NMT engine distinguishes semantically between the two types of objects (basically human or not) seems to be a direct benefit of the word embedding.
However, let us note that it does not correctly translate “rounds,” which in this example means “bullet.” We will explain this type of interpretation in another article on how trainings teach the neural network a specific meaning for each word. As for the rule-based engine, only the 3rdmeaning of the verb is recognized, which is more appropriate for a rocket than for a bullet.

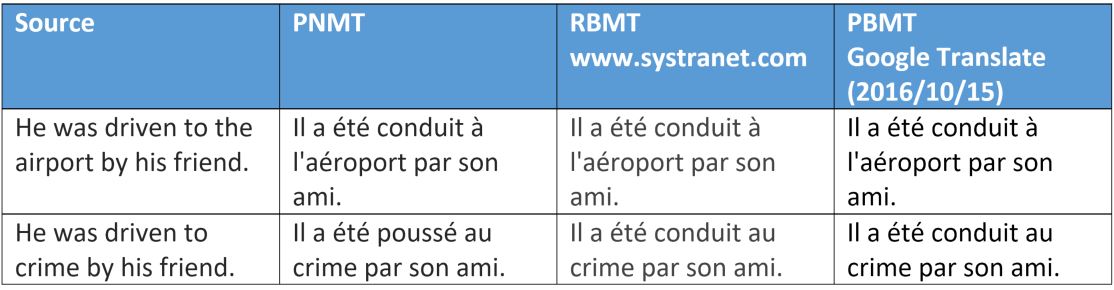
Above is another interesting example in which the difference of meaning of the verb stems from the object (crime or destination) which is again one direct knowledge from the word embedding.
Variants with the other type of crime show the same result…
The other engines are not wrong, as they use the same verb, which is acceptable in both contexts.
[1] B. Vauquois, « A Survey of Formal Grammars and Algorithms for Recognition and Translation », 1968
Read the first issue of our PNMT Insight series
- 三大机器翻译技术的high-level概述:Neural, Rule-Based and Phrase-Based Machine Translation
- 神经网络机器翻译Neural Machine Translation(5): Gradient-based Optimization Algorithms
- Phrase-based translation
- Effective Approaches to Attention-based Neural Machine Translation
- [EMNLP2015]Effective Approaches to Attention-based Neural Machine Translation
- Neural Machine Translation(NMT)技术概述
- 神经网络机器翻译Neural Machine Translation: Attention Mechanism
- 神经网络机器翻译Neural Machine Translation(1): Encoder-Decoder Architecture
- 神经网络机器翻译Neural Machine Translation(2): Attention Mechanism
- 神经网络机器翻译Neural Machine Translation(4): Modeling Coverage & MRT
- 神经机器翻译(Neural Machine Translation)系列教程
- 神经机器翻译(Neural Machine Translation)系列教程
- TensorFlow 神经机器翻译教程-TensorFlow Neural Machine Translation Tutorial
- 神经机器翻译(Neural Machine Translation)系列教程
- 神经机器翻译(Neural Machine Translation)系列教程
- 神经机器翻译(Neural Machine Translation)系列教程
- 神经机器翻译(Neural Machine Translation)系列教程
- 神经机器翻译(Neural Machine Translation)系列教程
- 【JSON学习】--简介
- Zookeeper实例Curator API-TestingCluster
- windows运行 HiveContext 报错
- spark-SQL的DataFrame和DataSet
- Spark集成 hadoop,hbase 的 maven冲突
- 三大机器翻译技术的high-level概述:Neural, Rule-Based and Phrase-Based Machine Translation
- 代理模式-以房屋中介说明
- ios tabar icon 图片渲染模式
- JavaSE 反射机制
- FAST特征点检测算法
- SSD 安装日志
- Spark任务卡死
- ext文件系统机制
- RealReachability网络状态实时监控使用


