Spider是为MySQL/MariaDB开发的一个特殊引擎,具有内嵌分片功能。现在它已经被集成到MariaDB10.0及以上版本中,作为MariaDB的一个新的主要特性。Spider的主要功能是将数据分散到多个后端节点,它的作用类似于一个代理。
本文主要分成四个部分来介绍Spider:
表链接:利用Spider,多个后端节点的表看起来就像存在于单一实例上一样。
事务:Spider实现了XA事务/单机事务接口,支持XA事务,以便在多个数据节点之间同步或者更新数据。
插拔式引擎:Spider作为MySQL/MariaDB的一个插拔式引擎,实现handler类定义的表访问方法。
读写流程:受MySQL Server层驱动,执行访问数据的动作。
一、表链接
Spider的表链接的技术参考ISO/IEC 9075-9:2008 SQL/MED标准。利用Spider的这个特性,你可以像操作本地MariaDB实例的表一样来操作远程MariaDB实例上的表,也可以像操作本地MariaDB实例的表一样来操作分布在多个MariaDB实例上的表。
当创建一个Spider存储引擎的表时,该表指向远程服务器上对应的一张表或者多个实例上的表,就像UNIX/Linux中的软链接一样。远程服务器上的表可以是任何存储引擎的表。在执行CREATE TABLE命令创建Spider引擎的表时,需要添加COMMENT或CONNECTION语法来指定远程服务器的地址等信息。例如,在远程服务器(该服务器是数据节点,假设IP为192.168.0.1)上创建了如下一张表:
CREATE TABLE s(id INT NOT NULL AUTO_INCREMENT, code VARHCAR(10), PRIMARY KEY(id));
在Spider节点创建一张表指向该表:
CREATE TABLE s(id INT NOT NULL AUTO_INCREMENT, code VARHCAR(10), PRIMARY KEY(id)) ENGINE=SPIDER COMMENT ‘host “192.168.0.1”,user “user1”, password “pwd1”, port “3307”’
在Spider节点,表字段定义可以忽略。Spider第一次访问表的时候,如果发现没有表字段定义,会从后端节点拉取相关元数据,然后缓存在本地。
Spider的系统表spider_tables记录了各个数据分片的位置信息,类似于编程语言中指针作用。该系统表可以便利Spider跨节点的join操作:访问数据所在的机器,然后把数据拉取到本地进行join操作;如果进行join操作字段不是分片字段,那么需要广播SQL语句将数据拉取到Spider节点进行join操作。
Spider_tables类似图1所示。
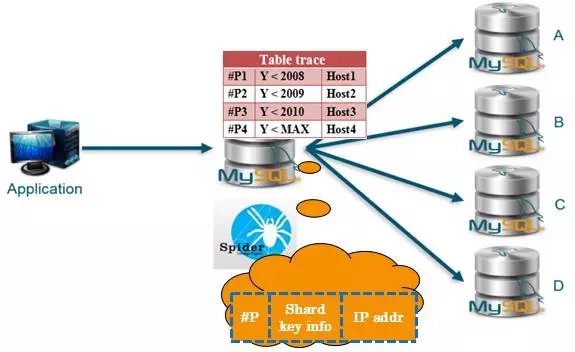
图1. Spider表链接
二、事务
Spider分别针对单机事务与XA事务实现了相应的操作事务的方法。图2列出了部分实现的方法。

图2. Spider部分实现的事务接口
上述方法的主要实现是向后端节点发送消息,有些阶段同时需要执行记录系统表的行为。Spider依赖后端数据节点保证事务的持久性以及隔离性。它只负责开启事务,以及在适当的时机发送提交或者回滚事务的命令。如果单机事务涉及多个数据节点,Spider需要将相应的连接保存在队列中。在事务提交或者回滚的时候,逐个发送相应的命令。
Spider参照分布式事务DTP/XA模型实现了分布式XA事务(见图3)。在这个模型中,存在RM(Resource Manager,资源管理器)、TM(Transaction Manager, 事务管理器)以及AP(Application, 应用程序)三种角色。AP通过RM API来操作和管理资源,通过TM接口开启/终止/结束事务。RM与TM之间需要实现XA接口。XA接口定义了两阶段提交的必要步骤,以及RM与TM之间需要进行的交互。Spider扮演的是TM角色,而后端的数据节点扮演的是RM的角色。
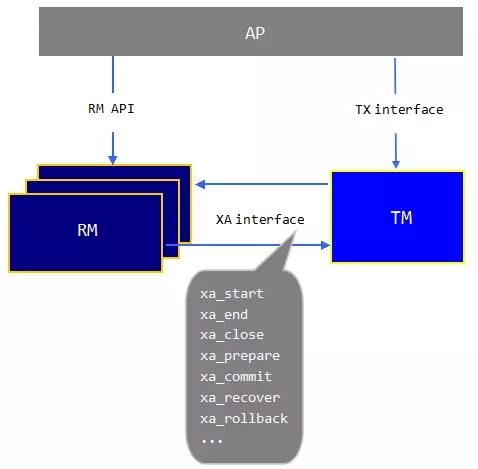
图3. 分布式DTP/XA模型
为了使用分布式XA事务,业界定义的XA命令如下:
XA START 'trx-id'; //开启XA事务
do actual work; //实际的查询执行语句
XA END 'trx-id'; //XA事务结束
XA PREPARE 'trx-id'; //预提交
XA COMMIT 'trx-id'; //提交
Spider会在系统表spider_xa中记录XA事务的状态,同时在另外一张系统表spider_xa_members中记录参与该XA事务的节点,以便进行操作。
在Spider中,XA事务分别有四种状态,如图4所示,对应于NOT YET,PREPAED,ROLLBACK以及COMMITTED。Spider在开始PREPARE阶段之际会在系统表spider_xa中标记该XA事务的状态为NOT YET。在所有数据节点都接收到PREPARE消息以后,该XA事务的状态进入到PREPARED阶段。假如在PREPARE阶段,某一个数据节点发生故障,那么Spider会回滚该事务。相应地,事务的状态变成ROLLBACK。
最后,如果所有参与事务的节点都返回PREPARE OK,该事务进入提交阶段。图5给出了对应上述命令的每一个步骤,Spider向后端节点发送的消息。
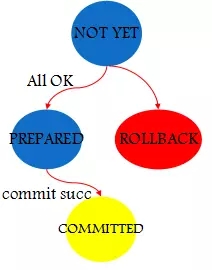
图4. Spider XA事务状态转换
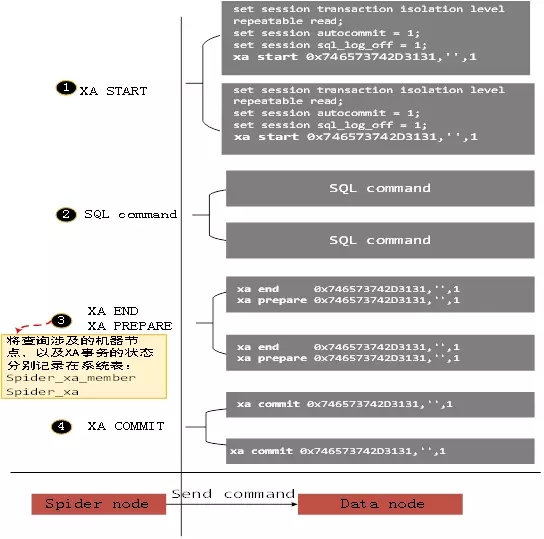
图5. 执行XA事务,Spider与两个后端节点的交互
从图5可以看到Spider向后端节点发送XA START命令时会设置会话级别的事务特性,同时将XA事务ID发送到后端节点。因为XA事务ID由三部分组成,Spider会将这三个部分的解析出来,然后拼接成对应的字符串发送到后端节点。为了节省网络开销,Spider将XA END与XA PREPARE命令合并起来一起发送。也就是在这个阶段初始,Spider在系统表里面记录事务的状态。如果所有的RM都返回OK,那么Spider进入PREPARED状态,准备提交事务。否则,事务进入到回滚状态。
三、插拔式引擎
MySQL最强大的功能之一,以及区别于其它关系型数据库系统的一个主要的特色是不同的表能够采用不同的存储引擎。每一个存储引擎都有其优缺点,用户能够根据自己的需要定制MySQL的存储引擎。存储引擎能够控制在哪里以及如何存放、获取数据。它代表了下面物理层提供的抽象逻辑接口,也是数据库执行实际I/O操作的地方。这是一个组件体系结构。在这个结构中,handler类定义了存储引擎提供的接口和功能。因为所有的存储引擎从基类handler继承而来,所以它们能够提供相同的功能。

原文链接


