DL语义分割总结
来源:互联网 发布:java 多线程监听端口 编辑:程序博客网 时间:2024/05/29 08:12
目前看过的论文有FCN,U-net,还有几个经典网络没有看,看论文速度有待提高,赶紧还债,下面是我对几个语义分割网络的简单理解,后期会补充。另,建议关注一个类似知乎的国外精英网站:Qure)
参考来源 :A 2017 Guide to Semantic Segmentation with Deep Learning
在FCN网络在2104年提出后,越来越多的关于图像分割的深度学习网络被提出,相比传统方法,这些网络效果更好,运算速度更快,已经能成熟的运用在自然图像上。
大致分为三部分:介绍语义分割问题,回顾语义分割方法,介绍一个有趣的网络算法。
1 什么是语义分割?
语义分割是在像素级别的水平上理解图像,为每个像素标记一个特定类别,比如下面一张图像

除了识别摩托车和骑手,我们还要划定目标边界,因此不同于分类问题,我们需要像素密度预测。两个比较常用的语义分割数据集为:VCO2012 和 MSCOCO在使用深度网络之前传统的算法有TextonForest 和 Random Forest based classifiers。和分类问题一样,CNN在图像分割方面也获得了巨大成功。
其中最开始的一个算法是基于图像块的分类(patch classification(http://people.idsia.ch/~juergen/nips2012.pdf)) ,每个像素根据它所在的像素块被分类。使用像素块原因是分类网络通畅以整幅图像作为输入,所以我们以图像块代表一个像素进而得到像素类别。
在2014年,Long等人提出全卷积网络(FCN),FCN是一个著名的CNN结构的像素密度预测网络,该网络的特点是没有全连接层,而是直接输出分割结果,这可以使网络输出任意大小的分割图,几乎所有以后算法都采用了这种范式。
除了全连接网络,CNN的另一个问题是池化层。池化层增加了视野,能够在忽略“where”信息的情况下聚合上下文。然而,语义分割要求分类图精确校正,因此需要保存“where”信息。在论文中提出了两种不同的分类架构。
第一种就是编码-解码结构。编码过程会通过池化操作逐渐降低空间尺度,而解码过程则会逐渐恢复目标细节和空间。在编码解码之间通常会有快捷连接来增加细节,比如融合,来使网络恢复目标更加完善。U-net网络如下所示:

第二类网络使用dilated/atrous卷积,并且去掉了池化层。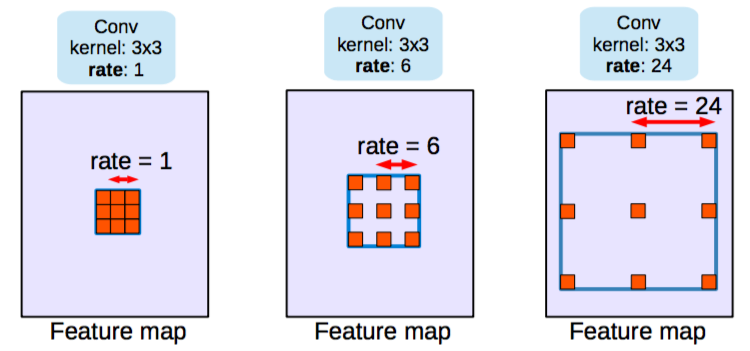
条件随机场(CRF)后处理能够提高分割效果。CRF是基于底层图像强度平滑“平滑”分割的图形模型。他们的工作原理为:强度类似的像素往往被标记为同一类。CRF能够提高1-2%的成绩。 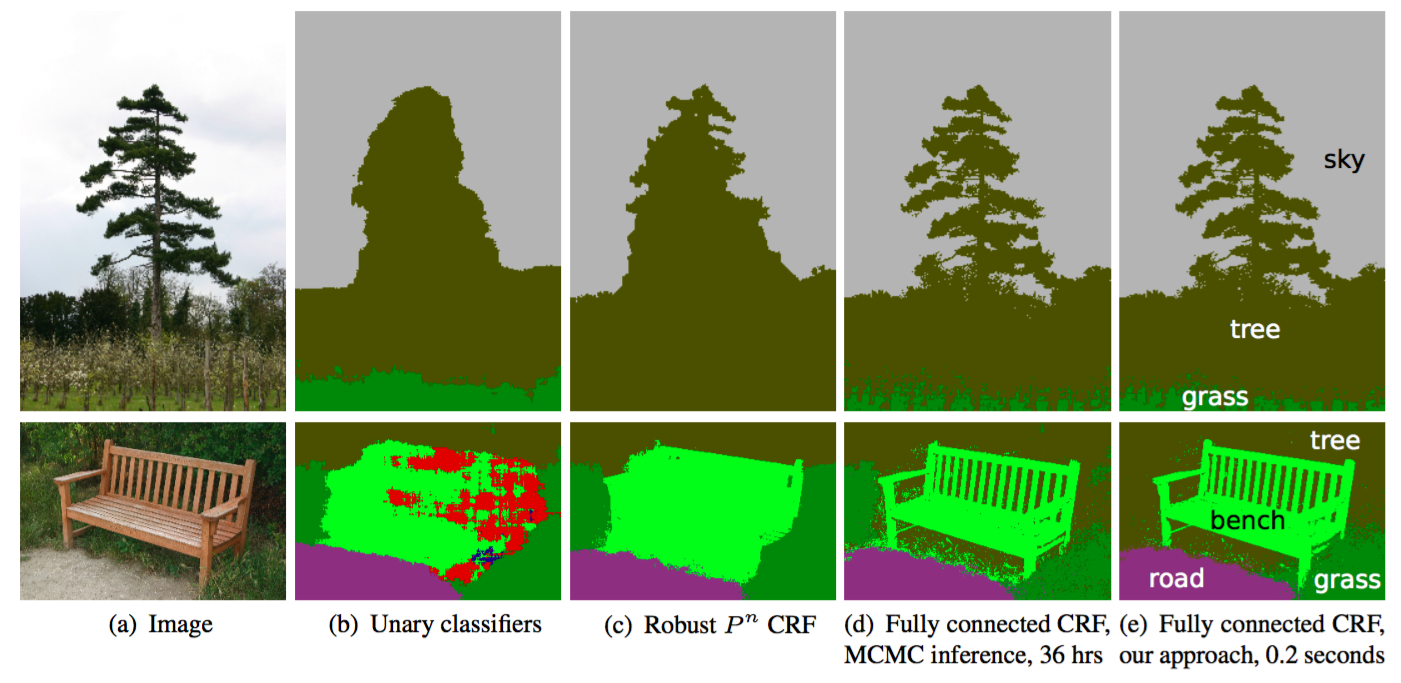
CRF illustration. (b) Unary classifiers is the segmentation input to the CRF. (c, d, e) are variants of CRF with (e) being the widely used one. source
第三部分介绍以下
1 FCN2 SegNet3 Dilated Convolutions4 Deeplab(v1&v2)5 RefineNet6 PSPNet7 Large Kerel Matters8 Deeplab v3FCN
全卷积网络对于图像分割
14 Nov 2014
主要贡献: 1 提出了使用端到端的卷积网络来进行语义分割 2 直接使用预训练好的分类网络进行图像分割(迁移学习) 3 使用反卷积层进行上采样 4 介绍跳过连接提高上采样的粗糙度详细解释: 关键是在分类网络中全连接层可以看做是覆盖整个输入区域的 内核的卷积。这相当于对原始分类网络的评估,在重叠的输入上面,但是由于计算在重叠区域是共享的,所以计算效率更高。虽然这种独到的见解不是第一次提出,但它却是提高了VOC2012测试效果。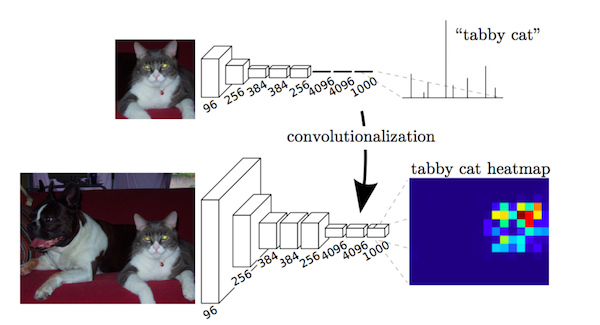
Fully connected layers as a convolution.Source.
在经过一个全卷积的预训练的网络之后,比如说VGG。由于池化操作降低了图像空间维度,特征map仍然需要需要被上采样。与简单的双线性插值不同,反卷积层可以学习插值。该层野叫上卷积(upconvolution),全卷积(full convolution),转置卷积(transpose convolution)或者分数化卷积(fractionally-strided convolution)
然而,上采样(即使反卷积层)产生粗糙的分割图,是因为在池化过程中信息的丢失。因此,快捷连接/跳转连接能够产生分别率更高的特征对应图。
评价:
这是分割图像中一个重要的贡献,当年引用率第一。2 SegNet
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Submitted on 2 Nov 2015
Arxiv Link
主要贡献:
最大池化转到解码提高分割精度详细介绍
尽管FCN网络的上卷积层和一个跳转连接能够生成粗糙的分割图。因此,更多的跳转连接被引进。然而,不是简单的复制FCN的编码特征,同时也保留最大池化时最大值位置。这使得SegNet需要更多内存但也比FCN更加有效。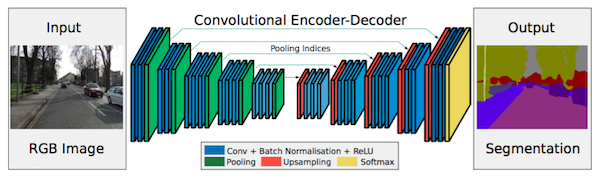
Segnet Architecture. Source.
评价:
1 FCN和SegNet都是第一次提出编码解码的结构
2 SegNet基准不够好
3 扩张卷积
Multi-Scale Context Aggregation by Dilated Convolutions
Submitted on 23 Nov 2015
Arxiv Link
主要贡献:
1 使用扩张卷积,一个卷基层用于密度估计
2 提出“上下文模块”采用扩张卷积在多尺度聚合
详细介绍
池化能帮助网络分类网络提高接受野。但是由于池化降低了分辨率,所以池化在分割方面很不好。因此,作者使用扩张卷积。如下图所示: 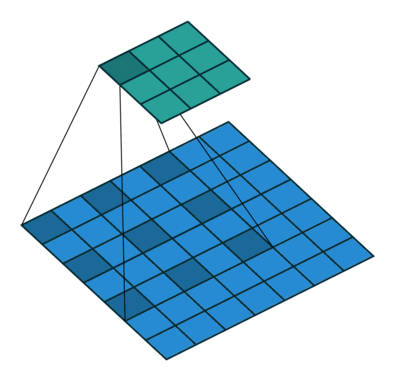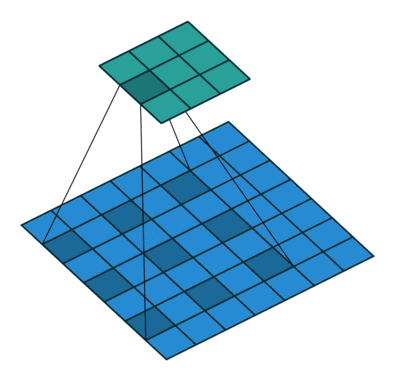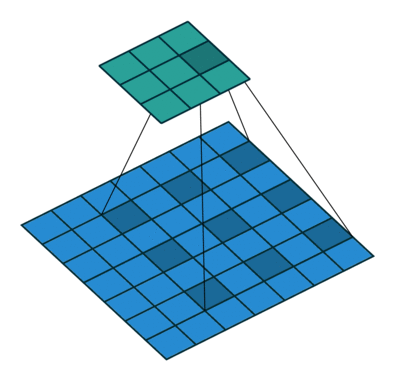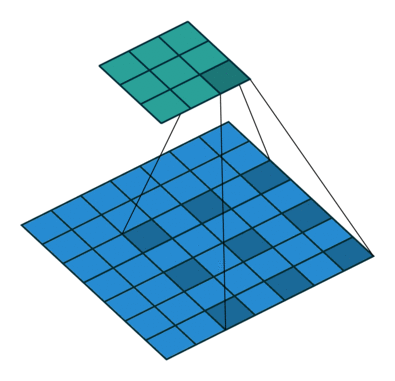
Dilated/Atrous Convolutions. Source
扩张卷积层(Atrous Convolutions)在不降低视觉空间的前提下增加视野维度。
在预训练网络VGG中,最后两个池化层被移除,接下来卷基层由扩张卷积替换。
特别的,在pool-3和pool-4之间的卷积层是dilation-2,pool-4之后是dilation 4。使用这个(论文中叫前端模块),在不增加参数的情况下提高了
一个模块(称为文章上下文模块)进行训练,分别与前端模块的输出作为输入。这个模块是一个级联的卷积,扩张扩张不同的多尺度上下文聚合和预测从前端的改进。
一个模块(在论文中称上下文模块)单独进行训练,与前端模块的输出作为输入。这个模块是级联的扩张卷积,拥有不同的扩张尺度,因此多尺度语境信息能被聚合,从前端的预测就被改进。
评价:
需要注意的是,分割结果的尺寸是图像尺寸的1/8。几乎所有的方法都是这样的,对它们进行插值得到最终的分割图。
(4) DeepLab(v1 & v2)
v1 : Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Submitted on 22 Dec 2014
Arxiv Link
v2 : DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Submitted on 2 Jun 2016
Arxiv Link
主要贡献:
1 使用 atrous/dilated 卷积
2 提出atrous 空间金字塔池化(ASPP)
3 使用全连接CRF
详细介绍:
atrous/dilated卷积在没有增加参数的情况下增加了视野范围。网络经过改变,如论文所示
多尺度处理可以多个调整尺寸的原图像平行通过CNN分支(金字塔图形)或者使用具有不同采样率的(ASPP)多个平行的不同的atrous 卷积层。
通过全连接CRF来实现结构预测。CRF。CRF作为后序流程单独训练/微调。 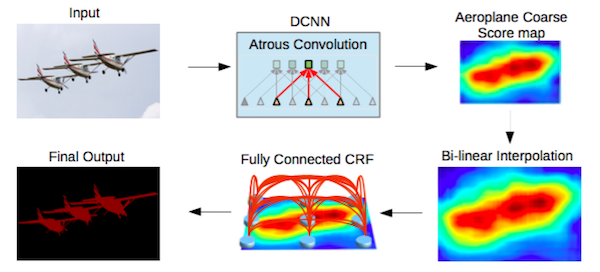
DeepLab2 Pipeline. Source.
(5) RefineNet
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
Submitted on 20 Nov 2016
Arxiv Link
主要贡献:
(1)具有良好解码块的编码-解码架构(2) 所有部件遵循剩余全连接详细解释:
采用dilated/atrous卷积也存在缺点。dilated卷积计算量大需要较大内存。因为他们已经被应用到大量高分辨率特征map。这阻碍了高分辨预测的计算。DeepLab预测,是原始输入大小的1/8。因此,本文提出编解码的架构。编码部分是ResNet-101模块。解码器有RefineNet模块,它连接/融合编码器的高分辨率特征和以前RefineNet模块的低分辨率特征。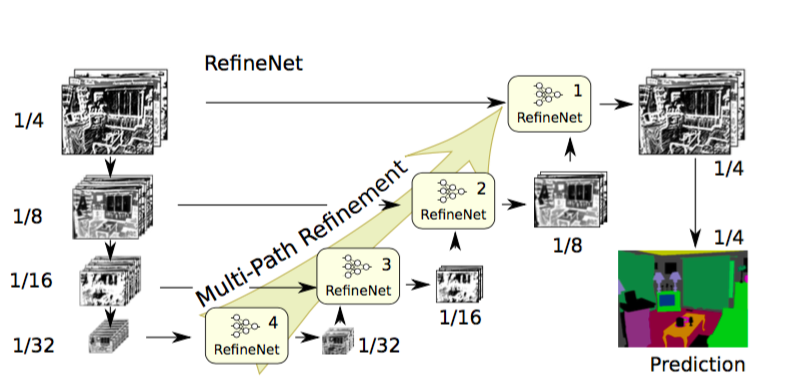
RefineNet Architecture. Source.
每个RefineNet模块拥有融合多分辨率特征的结构,他通过上采样低分辨率特征和捕获语境的组件,该组件基于重复size为5*5,stride为1 的重复池化层。这些组件中每个都采用了符合身份地图思维(identity map mindset)的残差连接(ResNet) 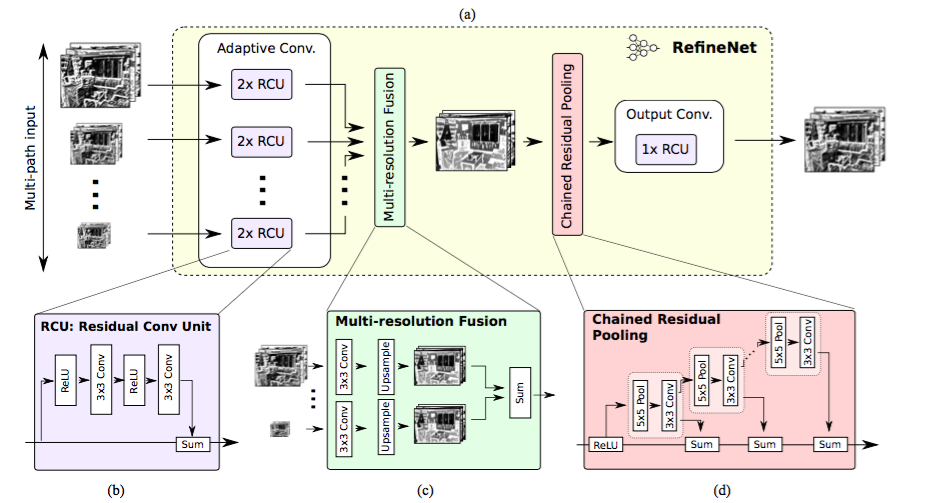
RefineNet Block. Source.
(5) PSPNet
Pyramid Scene Parsing Network
Submitted on 4 Dec 2016
Arxiv Link
主要贡献:
1 提出金字塔池化模型来聚合上下文信息
2 使用辅助损失
详细介绍:
全局场景分类重要是因为它提供了切分类别分布的线索。金字塔池化模型通过使用大规模的kernel池化层来捕捉这类信息。
Dilted 卷积在dilted卷积论文中被用来修改残差网络(Resnet),在其上面增加一个金字塔池化模型。该模型将ResNet的特征映射与上采样的输出,该输出是并行池化层,拥有能够覆盖整个,一半和一小部分图像的kernel。
辅助损失,对主要分支额外的,被应用第四阶段的ResNet(即输入金字塔池化模块)。该方法也被其他地方称为中间监督。 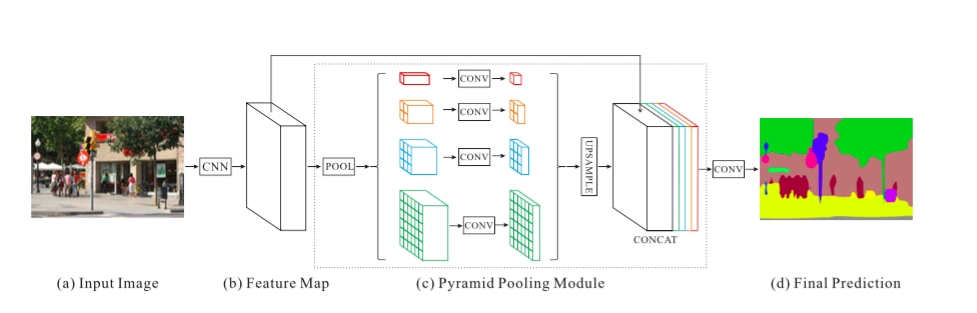
PSPNet. Source
(6) Large Kernel MAtters
Large Kernel Matters – Improve Semantic Segmentation by Global Convolutional Network
Submitted on 8 Mar 2017
Arxiv Link
主要贡献:
提出了拥有大面积的kernel的编解码架构
详细解释:
语义分割需要对对象进行分割和分类。由于全连接层是不可分割的结构,所以我们用非常大的卷积核来代替。
另一个原因是虽然更深度的神经网络比如ResNet拥有更大的接受视野。研究表明网络往往从一个很小的区域收集信息(有效接受域)。
较大的内核在计算上花费很大,并且参数更多。因此,K*K卷积核与1*K+K*1卷积核或者k*1+1*K卷积核近似。该模型在论文中被称作全局卷积网络(GCN)。
在架构中,ResNet(没有任何dilated卷积)组成编码部分,而GCNs和反卷积构成解码部分。一个简单的残余块被称为边界细化(BR)也被使用。 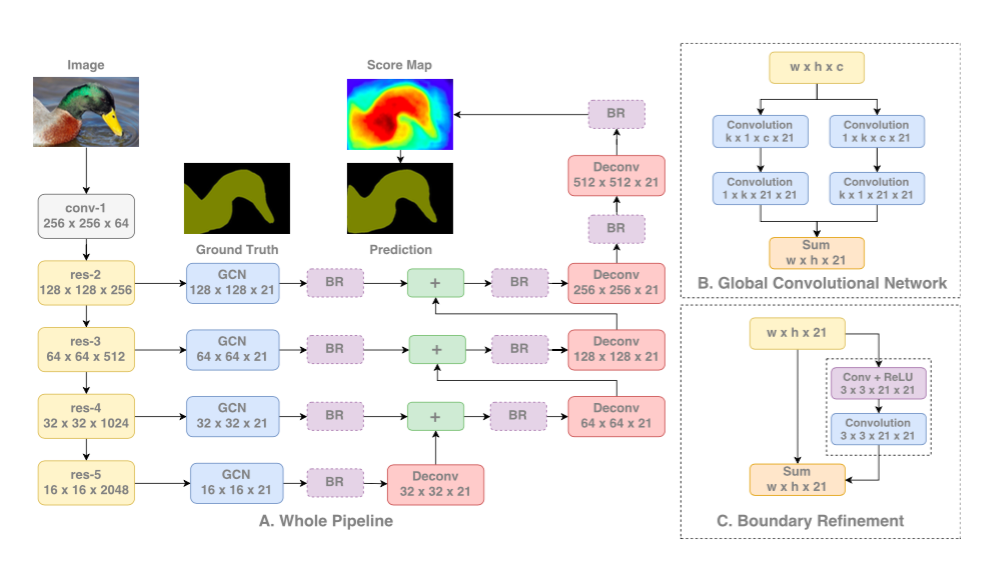
GCN Architecture.Source
(7) DeepLab v3
Rethinking Atrous Convolution for Semantic Image Segmentation
Submitted on 17 Jun 2017
Arxiv Link
主要贡献:
1 改进多孔(atrous)空间金字塔池化
2 提出使用多孔卷积级联的模型
详细解释:
ResNet模型通过使用多孔/扩张卷积被改进作为DeepLabv2和扩张卷积。改进的ASPP涉及图像层次特征的级联。一个1*1卷积和3个3*3多孔卷积以不同的比率。在每个并行卷积层后面是批处理标准化。
级联模块是一个残差网络模块,除了卷基层是不同比率的多孔。该模型类似于扩张卷积论文中的语境模块,但它直接用与中间特征映射而不是信念映射(信念映射是指与拥有与类别数目相同通道的卷基层的特征映射)
两个模型都是独立评估的。结合两者不能提高性能。他们两者都表现的非常相似在验证集上在拥有ASPP表现的更好,CRF没有使用。
这些模型都由于从DeepLabv2的最好模型。作者注意到改进来自批处理和更好的编码多尺度上下文。 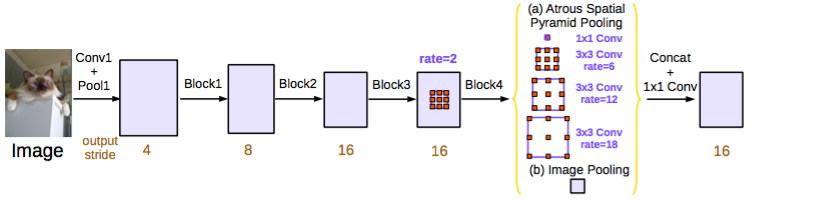
DeepLabv3 ASPP(used for submission).Source
- DL语义分割总结
- 语义分割相关总结
- 深度学习-语义分割总结
- 语义分割
- 语义分割
- 语义分割
- 语义分割
- 语义分割
- 语义分割
- 语义分割
- 语义分割
- ”语义分割”中的“语义”
- 关于图像语义分割的总结和感悟
- 关于图像语义分割的总结和感悟
- 图像语义分割的总结和资源推荐
- 【语义分割】图像语义分割技术入门
- FCN图像语义分割
- 深度学习语义分割
- xml学习笔记
- 2017年7月7日,周结(二十),实训之路开始
- Rspamd_rule_Html.lua自己的理解
- 嵌入式初体验
- LeetCode 605 : Can Place Flowers
- DL语义分割总结
- ng自定义指令和四种用法
- html讲课笔记
- 嵌入式系统学习——S3C2451嵌入式简介
- 605. Can Place Flowers
- 一起来看MyBatis(一)
- ionic3新特性懒加载,lazyloading
- 同一个Maven项目移机出错解决办法
- ROS机器人操作系统的安装、配置与初级教程 8


