朴素贝叶斯分类的Python实现
来源:互联网 发布:4518无法网络打印 编辑:程序博客网 时间:2024/05/16 13:52
贝叶斯定理:
条件概率: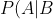)
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。
基本求解公式: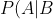=\frac{P(AB)}{P(B)})
贝叶斯定理:=\frac{P(A|B)P(B)}{P(A)})
朴素贝叶斯分类:
基于假定:给定目标值时属性之间相互条件独立。
思想基础:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
naiveBayes.py
# 使用朴素贝叶斯分类def classify(dataSet): numEntries = len(dataSet) # 计算出每种类别的数量 labelCounts = {} for featVec in dataSet: currentLabel = featVec[-1] labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1 # 计算出每个类的先验概率 prob = {} for key in labelCounts: prob[key] = float(labelCounts[key]) / numEntries return prob# 使用朴素贝叶斯预测def predict(prob, dataSet, features, newObject): numFeatures = len(dataSet[0]) - 1 # 计算条件概率 for i in range(numFeatures): labelValues = [example[-1] for example in dataSet if example[i] == newObject[features[i]]] labelCounts = {} for currentLabel in labelValues: labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1 for val in prob: prob[val] *= float(labelCounts.get(val, 0)) / len(labelValues) # 找出最大返回 maxProb = -1.0 for val in prob: if prob[val] > maxProb: maxProb = prob[val] label = val return labeldef main(): # 创建数据集 def createDataSet(): dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] features = ['no surfacing', 'flippers'] return dataSet, features dataset, features = createDataSet() prob = classify(dataset) print(predict(prob, dataset, features, {'no surfacing': 1, 'flippers': 1})) print(predict(prob, dataset, features, {'no surfacing': 1, 'flippers': 0})) print(predict(prob, dataset, features, {'no surfacing': 0, 'flippers': 1})) print(predict(prob, dataset, features, {'no surfacing': 0, 'flippers': 0}))if __name__ == '__main__': exit(main())输出结果:
yesnonono
阅读全文
0 0
- 朴素贝叶斯分类器的python实现
- 朴素贝叶斯分类算法的Python实现
- 朴素贝叶斯分类的Python实现
- 朴素贝叶斯分类的实现
- Python实现朴素贝叶斯分类器
- python实现一个朴素贝叶斯分类器
- 朴素贝叶斯分类文本 python实现
- 朴素贝叶斯分类器及Python实现
- 朴素贝叶斯分类器(Python实现)
- 朴素贝叶斯分类算法python实现
- 朴素贝叶斯分类原理及Python实现简单文本分类
- 《机器学习实战》基于朴素贝叶斯分类算法构建文本分类器的Python实现
- 朴素贝叶斯实现的文本分类
- 【机器学习算法-python实现】扫黄神器-朴素贝叶斯分类器的实现
- 【机器学习算法-python实现】扫黄神器-朴素贝叶斯分类器的实现
- 朴素贝叶斯分类Python演示
- 分类-朴素的贝叶斯
- Python实现文本自动分类(朴素贝叶斯方法)
- Java提高篇——equals()与hashCode()方法详解
- “玲珑杯”ACM比赛 Round #18
- CSS性能优化
- ES(elasticsearch)搜索引擎安装和使用
- Gym-101353H Simple Path(树型dp)
- 朴素贝叶斯分类的Python实现
- java--单测
- linux下如何查看某软件是否已安装
- SGU167 I-country
- POI之Word文档读取-yellowcong
- HDU-5977 Garden of Eden(树分治+枚举子集)
- JS中style.display和style.visibility的区别
- 关于const引用
- Mac Install Raspberry system to machine


