hash算法冲突
来源:互联网 发布:华大基因数据库 编辑:程序博客网 时间:2024/05/29 08:27
a)开放定址法
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。注意:
①用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。
②空单元的表示与具体的应用相关。
按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、线性补偿探测法、随机探测等。
(1)线性探查法(Linear Probing)
该方法的基本思想是:
将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:
d,d+l,d+2,…,m-1,0,1,…,d-1
即:探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。
探查过程终止于三种情况:
(1)若当前探查的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探查的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探查到T[d-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
利用开放地址法的一般形式,线性探查法的探查序列为:
hi=(h(key)+i)%m 0≤i≤m-1 //即di=i
用线性探测法处理冲突,思路清晰,算法简单,但存在下列缺点:
① 处理溢出需另编程序。一般可另外设立一个溢出表,专门用来存放上述哈希表中放不下的记录。此溢出表最简单的结构是顺序表,查找方法可用顺序查找。
② 按上述算法建立起来的哈希表,删除工作非常困难。假如要从哈希表 HT 中删除一个记录,按理应将这个记录所在位置置为空,但我们不能这样做,而只能标上已被删除的标记,否则,将会影响以后的查找。
③ 线性探测法很容易产生堆聚现象。所谓堆聚现象,就是存入哈希表的记录在表中连成一片。按照线性探测法处理冲突,如果生成哈希地址的连续序列愈长 ( 即不同关键字值的哈希地址相邻在一起愈长 ) ,则当新的记录加入该表时,与这个序列发生冲突的可能性愈大。因此,哈希地址的较长连续序列比较短连续序列生长得快,这就意味着,一旦出现堆聚 ( 伴随着冲突 ) ,就将引起进一步的堆聚。
(2)线性补偿探测法
线性补偿探测法的基本思想是:
将线性探测的步长从 1 改为 Q ,即将上述算法中的 j = (j + 1) % m 改为: j = (j + Q) % m ,而且要求 Q 与 m 是互质的,以便能探测到哈希表中的所有单元。
【例】 PDP-11 小型计算机中的汇编程序所用的符合表,就采用此方法来解决冲突,所用表长 m = 1321 ,选用 Q = 25 。
(3)随机探测
随机探测的基本思想是:
将线性探测的步长从常数改为随机数,即令: j = (j + RN) % m ,其中 RN 是一个随机数。在实际程序中应预先用随机数发生器产生一个随机序列,将此序列作为依次探测的步长。这样就能使不同的关键字具有不同的探测次序,从而可以避 免或减少堆聚。基于与线性探测法相同的理由,在线性补偿探测法和随机探测法中,删除一个记录后也要打上删除标记。
b)再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
c)链地址法
将所有关键字为同义词的记录存储在同一线性链表中。如下: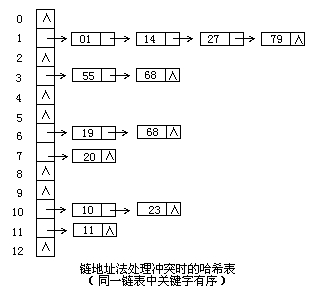
因此这种方法,可以近似的认为是筒子里面套筒子
d)建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。阅读全文
0 0
- hash算法冲突
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- java解决hash算法冲突
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- hash冲突及处理算法
- Hash算法冲突解决方法分析
- Hash算法冲突解决方法分析
- 常用 Hash 算法冲突解决方法分析
- 常用 Hash 算法冲突解决方法分析
- 【java基础 10】hash算法冲突解决方法
- Hash算法解决冲突的方法
- hash算法以及解决冲突的方法
- 软件调试的一些心得
- u-boot 编译改动了那些文件(1)make xxx_config
- JAVA计算题
- 向前向后兼容
- Java统计字符串中子字符串个数的两种方法:
- hash算法冲突
- CJSON, license,卷积,加密,同步异步阻塞非阻塞
- Android Studio进行真机调试的相关设置
- 堆排序原理及实现
- 类加载器
- c++primer5 第一章
- mac boot2docker 代理
- OpenCV之findContours函数及参数讲解
- CSS基础知识(三)


