2017深度学习最新报告及8大主流深度学习框架超详细对比(内含PPT)
来源:互联网 发布:最新网络流行词汇 编辑:程序博客网 时间:2024/05/21 03:55
2017深度学习最新报告(PPT)
深度学习领军人物 Yoshua Bengio 主导的蒙特利尔大学深度学习暑期学校目前“深度学习”部分的报告已经全部结束。 本年度作报告的学术和行业领袖包括有来自DeepMind、谷歌大脑、蒙特利尔大学、牛津大学、麦吉尔大学、多伦多大学等等。覆盖的主题包括:时间递归神经网络、自然语言处理、生成模型、大脑中的深度学习等等。现在全部PPT已经公开,是了解深度学习发展和趋势不可多得的新鲜材料。
蒙特利尔大学的深度学习暑期学校久负盛名,在深度学习领军人物Yoshua Bengio 号召下,每年都聚集了顶尖的深度学习和人工智能方面的学者进行授课。今年的暑期学校更是首次增加了强化学习课程。
深度神经网络,即学习在多层抽象中表示数据的神经网络,已经极大地提升了语音识别、对象识别、对象检测、预测药物分子活性以及其他许多技术。深度学习通过构建分布式表示(监督学习、无监督学习、强化学习)在大型数据集中发现复杂结构。
今年的 DLSS 由 Graham Taylor,Aaron Courville 和 Yoshua Bengio 组织。
强化学习暑期学校
这是第一届的蒙特利尔大学强化学习暑期学校(RLSS),与 DLSS 是相辅相成的。RLSS 将涵盖强化学习的基础知识,并展示最新的研究趋势和成果,为研究生和该领域的高级研究人员提供互动的机会。
今年的 RLSS 由 Joelle Pineau 和 Doina Precup 组织。
目前,深度学习部分的课程已经结束,官方公开了全部的讲义PPT,今年的深度学习部分的课程内容包括:
蒙特利尔大学 Yoshua Bengio 主讲《循环神经网络》 。
谷歌的Phil Blunsom 主讲自然语言处理相关内容,分为两部分《自然语言处理、语言建模和机器翻译》和《自然语言的结构和基础》。
蒙特利尔大学的Aaron Courville 主讲《生成模型》。
谷歌大脑的Hugo Larocelle 主讲《 神经网络》。
麦吉尔大学的Doina Precup 主讲 《机器学习导论》。
牛津大学的 Mike Osborne主讲《深度学习中的概率数字》。
多伦多大学的 Blake Aaron Richards 主讲《大脑中的深度学习》。
Yoshua Bengio 主讲《时间递归神经网络》 :RNN 的 7个小贴士
Bengio 今年主讲的主题是《时间递归神经网络》。在神经网络中,时间递归神经网络模型通过一个递归的更新,从一个固定大小状态的向量中有选择性地对一个输入序列进行提炼。时间递归神经网络能在每一个时间点上产生一个输出。
一个RNN能表征一个全连接的定向生成模型,即,每一个变量都能从根据前序变量进行预测。
他在演讲中介绍了多种类型的RNN:双向RNN、递归网络,多维RNN 等等,根据演讲PPT,用梯度下降学习长依存性是非常困难的。1991年,Bengio在MIT时,所做的研究中的样本实验,只能做到2个类型的序列。
基于梯度的学习为什么很困难?Bengio认为,与短依存相比,长依存所获得的权重过小,指数级的小。由此,从RNN的例子可以看到,梯度消失在深度网络是非常困难的。所以,为了稳定的存储信息,动态性必须进行收缩。
关于 RNN的 7个小贴士:
剪裁梯度(避免梯度的过载)
漏洞融合(推动长期的依存性)
动能(便宜的第二等级)
初始化(在正确的范围开始,以避免过载/消失)
稀疏梯度(对称性破坏)
梯度传播的正则化(避免梯度消失)
门自循环(LSTM&GRU,减少梯度消失)
他在演讲中着重介绍了注意力机制:快速进步的20年:用于记忆权限的注意力机制
神经网络图灵机
记忆网络
使用基于内容的注意力机制来控制记忆的读写权限
注意力机制会输出一个超越记忆位置的Softmax
深度学习中的注意力机制示意图
注意力机制现在在端到端的机器翻译中得到应用,并且获得巨大成功。
设计RNN架构
Bengio 课程全部PPT地址:
https://drive.google.com/file/d/0ByUKRdiCDK7-LXZkM3hVSzFGTkE/view
谷歌Phil Blunsom 主讲自然语言处理
自然语言成为本期蒙特利尔大学深度学习暑期学校的一个重点。
来自谷歌的 Phil Blunsom 在两个报告中分别介绍了《自然语言处理、语言建模和机器翻译》和《自然语言的结构和基础》
本报告中,讲者介绍了语言建模的三种渠道:
通过计算基于 n-gram 的模型,我们用前面的 n 词近似观察词的历史。
在连续的空间中,神经网络的n-gram模型嵌入相同的固定n-gram历史中,进而更好地捕捉不同历史之间的关系。
使用时间递归神经网络,我们终止了固定的n-gram历史,并且将整个历史压缩到固定的长度向量,使得长距离的关联能够被捕捉。
蒙特利尔大学Aaron Courville 主讲:生成模型
CIFAR Fellow、蒙特利尔大学的 Aaron Courville 在这堂课中讲授了生成模型的一些重点。Aaron Courville 不是别人,正是人工智能领域的又一本“圣经级教材”《深度学习》(Deep Learning)一书的第三位作者——剩下两位是 Ian Goodfellow 和 Yoshua Bengio。
我们知道,从模型角度讲,无监督学习分为概率模型和非概率模型。稀疏编码、自编码器和 K-means 都属于非概率模型,而在概率模型中衍生出了两条分支:显式密度模型(Explicitly Density Model)和隐性密度模型(Implicit Density Model),生成对抗网络(GAN)就属于后者。
显式密度模型又分为易解模型(Tractable Model)和难解模型(Non-Tractable Model)。NADE、PixelRNN 都属于可解模型,而玻尔兹曼机(BMV)、变分自编码器(VAE)则属于难解模型。
Courvill 的这堂课内容分成两部分,以PixelCNN 为例讲自回归模型,以及 VAE 和 GAN(包括 WGAN)讲潜变量模型。
谷歌大脑的Hugo Larocelle 主讲神经网络
《神经网络》课程的形式是在线视频讲座,将非常细致地讲解人工神经网络相关知识,内容涵盖:①神经网络是如何从输入x得到预测的f(x),需要了解前向传播、神经元的类型;②怎样基于数据训练一个神经网络(分类器),需要了解损失函数、反向传播、梯度下降算法、训练的一些技巧等;③深度学习:无监督预训练、dropout、批标准化等。
麦吉尔大学的 Doina Precup 主讲机器学习导论
本讲介绍了机器学习的一些问题类型,以及线性逼近器、误差函数/目标函数机器优化方法、偏差方差折衷,过拟合和欠拟合、线性估计器的L2和L1正则化、正则化的贝叶斯解释,以及逻辑回归。机器学习问题的类型包括监督学习,强化学习和无监督学习,本讲课程以人脸检测和识别、TD-Gammon、肿瘤检测等作为实例分别讲解,并介绍解决这些问题类型的步骤和可用方法。
牛津大学的 Mike Osborne主讲深度学习中的概率数字
多伦多大学的 Blake Aaron Richards 主讲大脑中的深度学习
我们的感知、动作和记忆从何而来?从我们神经系统中神经元的活动而来。人脑里有着几十亿大脑神经元,这些神经元彼此之间的突触连接,还有这些连接强度的精确调谐,使这个地球上最复杂神秘的生理学功能成为可能。
但是,这些连接并不是由人类基因组所决定的。无论是昆虫还是人类,神经元的连接都是后天形成的,动物会使用从感官和运动经验中得到的信息来塑造神经元之间的突触连接。
CIFAR Associate Fellow,Blake Richards 的研究领域是神经生理学、系统神经科学和计算神经科学。计算神经科学通过在对神经系统建模和分析的过程中应用计算的方法和观念,整合各种对神经系统进行模拟的尝试性工作。这当中,会使用机器学习方法和应用数学解答神经科学问题。
Richards 在深度学习暑期学校讲的课题很有意思——《大脑里的深度学习》。人工神经网络本来就模仿了很多人类神经网络的概念,Deep learning本身就是做计算神经学的的人发明的。因此大脑里也会用到深度学习并不奇怪。Richards 介绍了当前的深度学习研究在真实大脑里的潜在应用。具体说,主要是反向传播(Backpropagation)。
在算法和数学公式推导中,体会大脑里的深度学习。
全部讲义下载
Bengio - Recurrent Neural Networks(下载:http://t.cn/RoD3NZY)
Phil Blunsom - Natural Language Processing, Language Modelling and Machine Translation (下载:http://t.cn/RoD3R3Y)
Blunsom - Structure and Grounding in Natural Language(下载:http://t.cn/RoD3dLy)
Courville - Generative Models II(下载:http://t.cn/RoD1hiV)
Larochelle - Neural Networks 1(下载:http://t.cn/RoD1LR2)
Larochelle - Neural Networks 2(下载:http://t.cn/RoD15cy)
Osborne - Future_of_Work_DLSS(下载:http://t.cn/RoD1Mpq)
Osborne - PN_BO_DLSS(下载:http://t.cn/RoD1a8C)
Precup - dlss-intro-2017(下载:http://t.cn/RoD1pfi)
Richards - Deep_Learning_in_the_Brain(下载:http://t.cn/RoD1QaZ)
AAAI 2017讲座:8大主流深度学习框架超详细对比(90PPT)
AI复始,万象更新 !
【导读】这一讲座介绍了深度学习框架设计原则的基本知识,其目标是为希望在自己的工作任务中利用深度学习的研究者 和 AI 实践者提供关于选择合适框架的指导。讲座分为三部分:1. 神经网络基础知识;2. 神经网络部署的常见设计;3.各种常见深度学习框架的优缺点比较。
全部PPT下载地址:https://sites.google.com/site/dliftutorial/
2017年2月5日的 AAAI 大会上,来自日本的Seiya Tokui 、Kenta Oono 和 Atsunori Kanemura三位AI研究员带来了《Deep Learning Implementations and Frameworks》的课程(Tutorial )介绍。
这一讲座介绍了深度学习框架设计原则的基本知识,其目标是为希望在自己的工作任务中利用深度学习的研究者 和AI 实践者提供关于选择合适框架的指导。
当下,深度学习中的一些软件框架,比如 TensorFlow 和 Caffe,已经被许多深度学习系统采纳,以加速研究和发展速度。深度学习在 AI 的核心技术中扮演基础性的作用,其中包括图像和语音识别、计划和自然语言处理。在AI 系统的搭建上,深度学习也起到了基础材料的作用,比如,在机器人、游戏、问答和药物诊断中都是。
深度学习模型的设计从本质上看,是组件和灵感的结合。深度学习的技术要素通常都是通用的。比如,对于图像识别来说,一个典型的深度学习架构就是一个多层的卷积栈(stack)和池化操作。许多行为,包括 dropout 和 batch 正则化通常都会被用于提升泛华能力。一个超大量级的部署可以简化为:好的组件(比如卷积网络和池化)以及灵感(比如dropout 和 batch 正则化)的结合。这是为什么深度学习能让编程更加有效的原因。
选择一个合适的深度学习框架要求对框架设计的基本原则有一定的知识储备。当下,深度学习中有各种各样的框架,这让用户在选择最合适的框架上存在不少困惑。除了重复利用性以外,竞争所需要的速度、可扩展性、代码简洁性、去bug的简便性以及社区的大小等等都为此添加了难度。选择一个次优的框架可能会使得研究和发展的效率降低,损害工作的实用性,降低声望。
基于深度学习在简单的模式识别任务之外的最新进展,这一讲座将提供一些面向一般性的AI应用的有用技术信息。
| 目标受众
讲座面向的是希望利用深度学习来开发AI 系统或者在具体任务中运用AI 的系统的研究者和相关从业者,讲座专门用于帮助他们从多个候选选项中为自己的应用选择最合适的软件框架。
改讲座提供了关于不同框架的设计和优化原则,以为选择合适的框架提供指导。听众从讲座将能学到,为什么一些框架会比另一些快,为什么一些框架中bug的去除很困难以及为什么一些框架对于动态的模型变化是无效的。讲座还提供了 TensorFlow、 Keras 和 Chainer 上的代码案例,不仅展示了这些框架的可用性,还对它们的内部机制进行了深度的介绍。整个讲座的视角是通用性的,对于讲座中提到的主题的理解,将有利于在评估目前还没有发布的一些框架。
| 讲者
Seiya Tokui ,东京大学博士、Preferred Networks研究员。深度学习框架Chainer 的主要开发者。
Kenta Oono ,Preferred Networks 工程师。深度学习框架Chainer 的主要开发者。
Atsunori Kanemura,日本国家高级工业科学技术研究所研究员。
第一部分 简介
讲座名称:深度学习部署和框架
主要内容概览:
Session 1:简介、神经网络基础、神经网络部署的常见设计
Session 2:不同的深度学习框架,框架的代码示例、结论
如此多的深度学习框架:Tensorflow、Caffe、CNTK、Theano、Torch、MXNet、Chainer、Keras等等。哪一个才是最适合你的?
讲座目标:
介绍深度学习框架背后的设计原则
提供选择合适框架的要领
了解大多数深度学习框架中常见的技术栈的组成部分
了解不同的部署之间的差别
标准受众:希望开发包含神经网络系统的人
背景准备:
一般的机器学习术语,特别是关于监督式学习的
基本的神经网络知识或者实践(推荐)
基本的 Python 编程语言(推荐)
介绍到(或者不会介绍到)的框架
附带编码示例进行深度解释的有:
Chainer-Python
Keras-Python
TensorFlow-Python
也对比了以下几个框架:
Torch-Lua
Theano-Python
Caffe-C++& Python & Matlab
MXnet-Many
PyTorch-Python
其他没有介绍的:
云计算、Matlab toolboxes、DL4J、H2O、CNTK
TensorBoard,DIGITS
神经网络基础
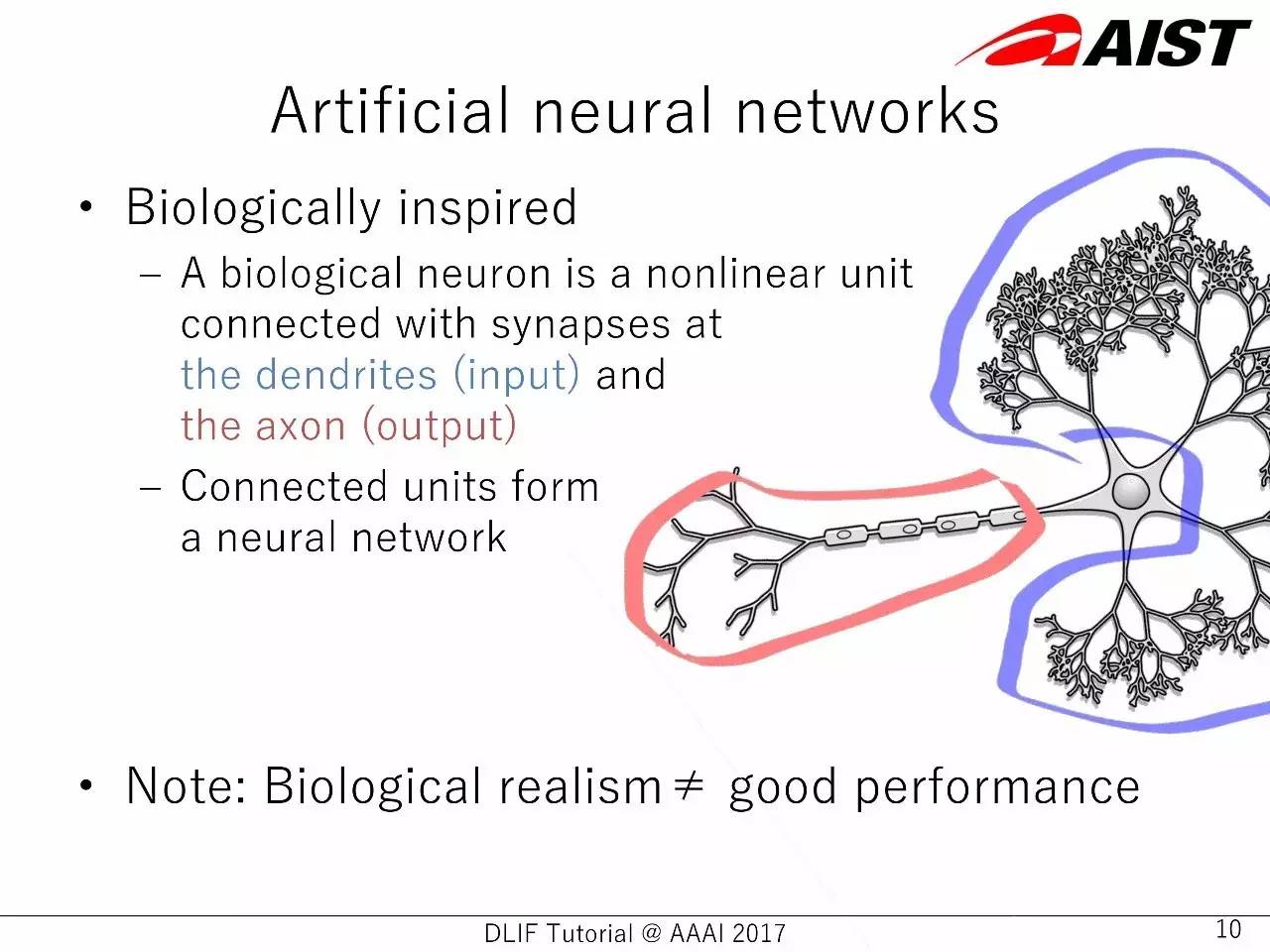
人工神经网络从生物学获得启发,但是,生物学上的实现不等于好的性能。
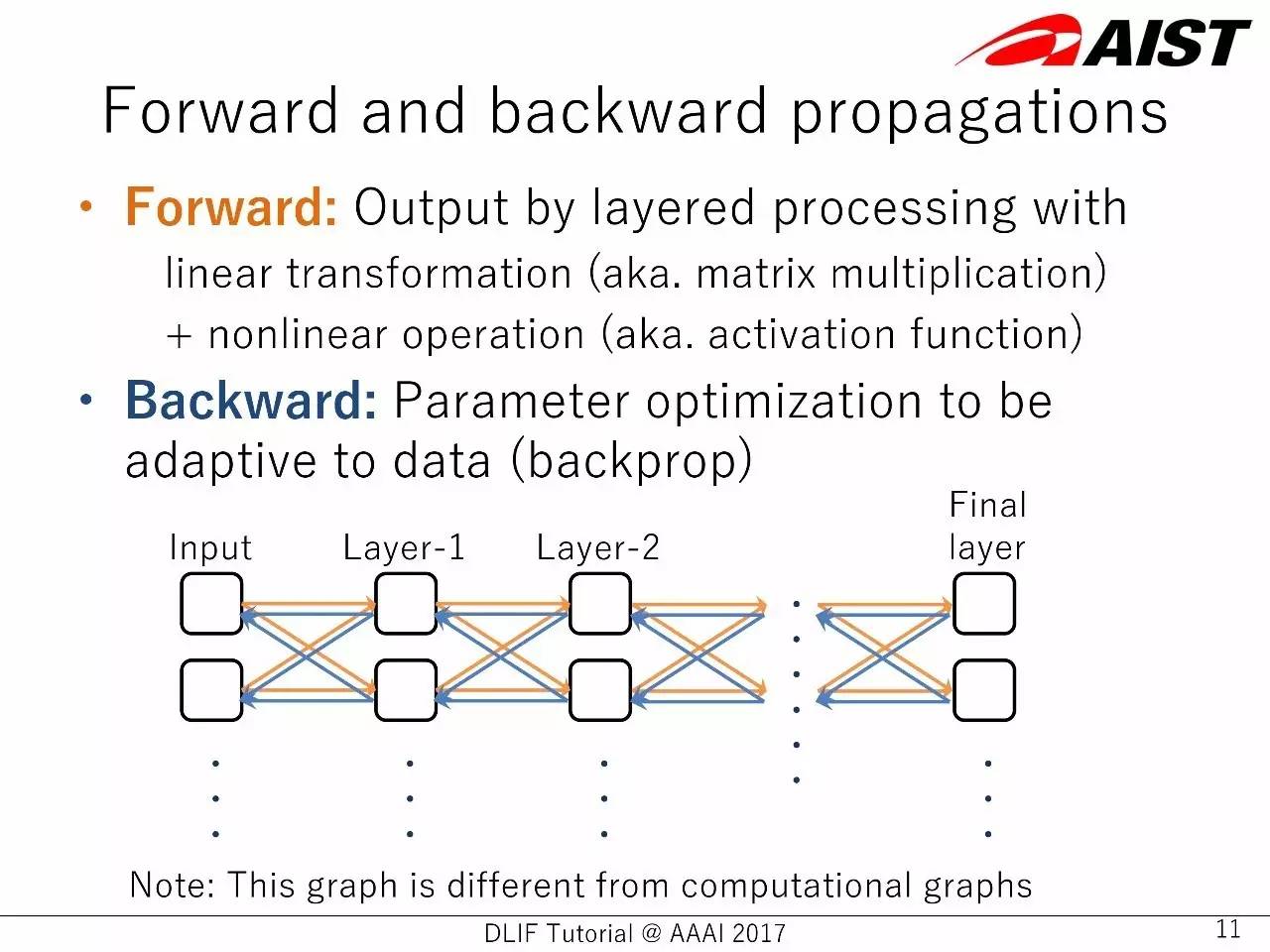
前向和反向传播
前向:(神经网络层)处理线性信息(比如,矩阵乘法)+非线性信操作(比如,激活函数)得到的输出
反向:对参数进行优化,以更适应数据(反向传播)
神经网络的灵活性使得多个应用成为可能:
图像识别,ImageNet LSVR 挑战中,超越人类表现
玩游戏,AlphaGo,击败人类专家
连接多种形式的内容,比如,图像和文本。用中间的表征(嵌入)从图像中生成文字。
生成模型:生成对抗模型
翻译、语音识别等等……
例子:分类
D代表维度输入向量(特征),比如,一张100X100的照片
K代表分类目标,比如,对象类型,猫、桌子、椅子等等
N代表数据集大小
目标:给神经网络一个新的输入向量,预测其类型
一个神经元的数学模型
计算输入x 和参数 w,通过一个非线性的激活函数 f 转化。
一般的线性判别式
一层神经网络的例子
一般线性判别式
在损失最小化下进行学习
从多个样本中进行学习
双输出
定义损失函数
把定义函数最小化,以学习(评估)参数
梯度下降
一层神经网络中的损失梯度的公式表示
升级的规则
其他类型的损失函数:Cross entropy,Exponential,Zero-one,Kullback-Leiber
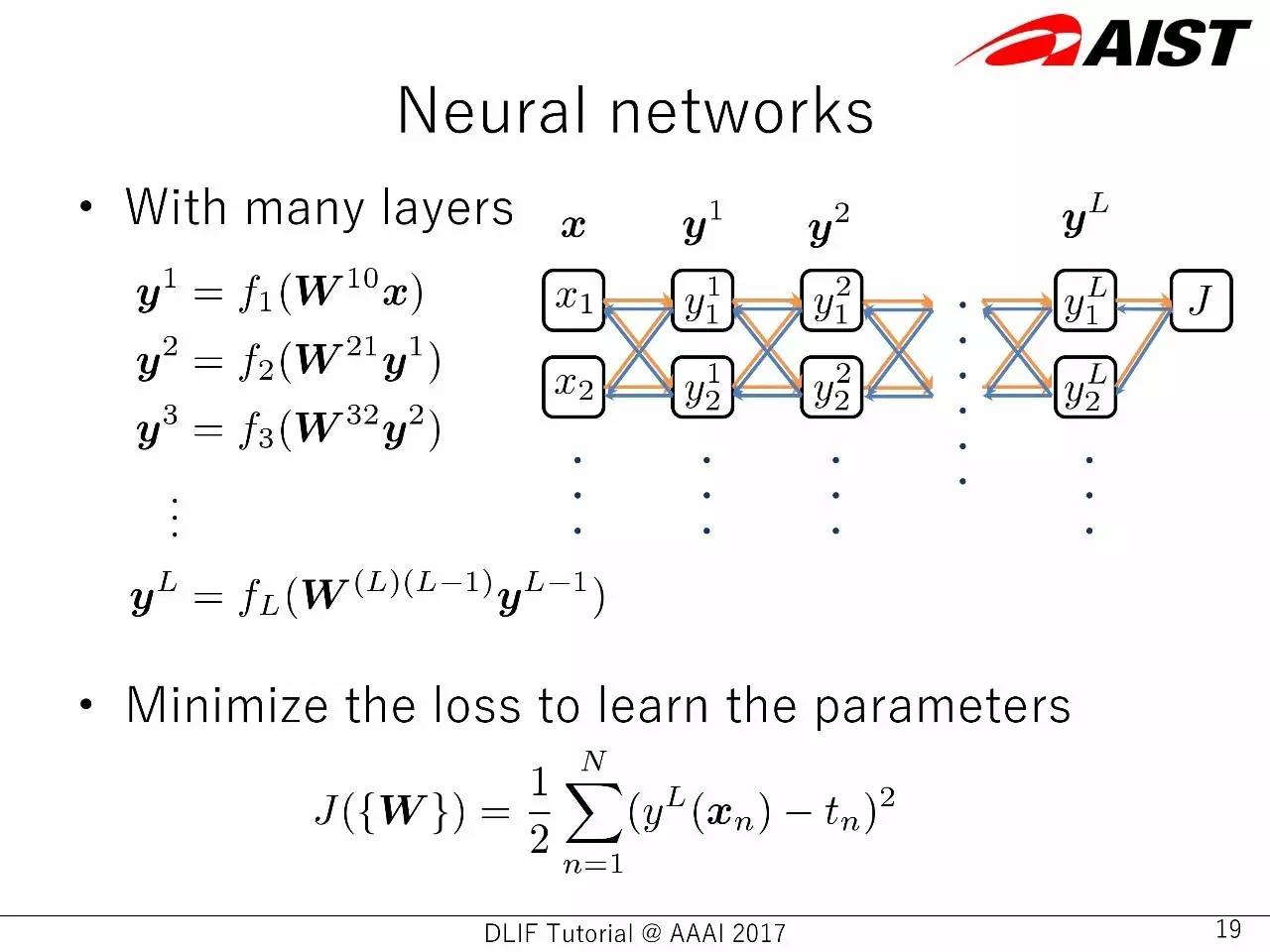
多层神经网络中的,损失函数最小化
两层神经网络的例子
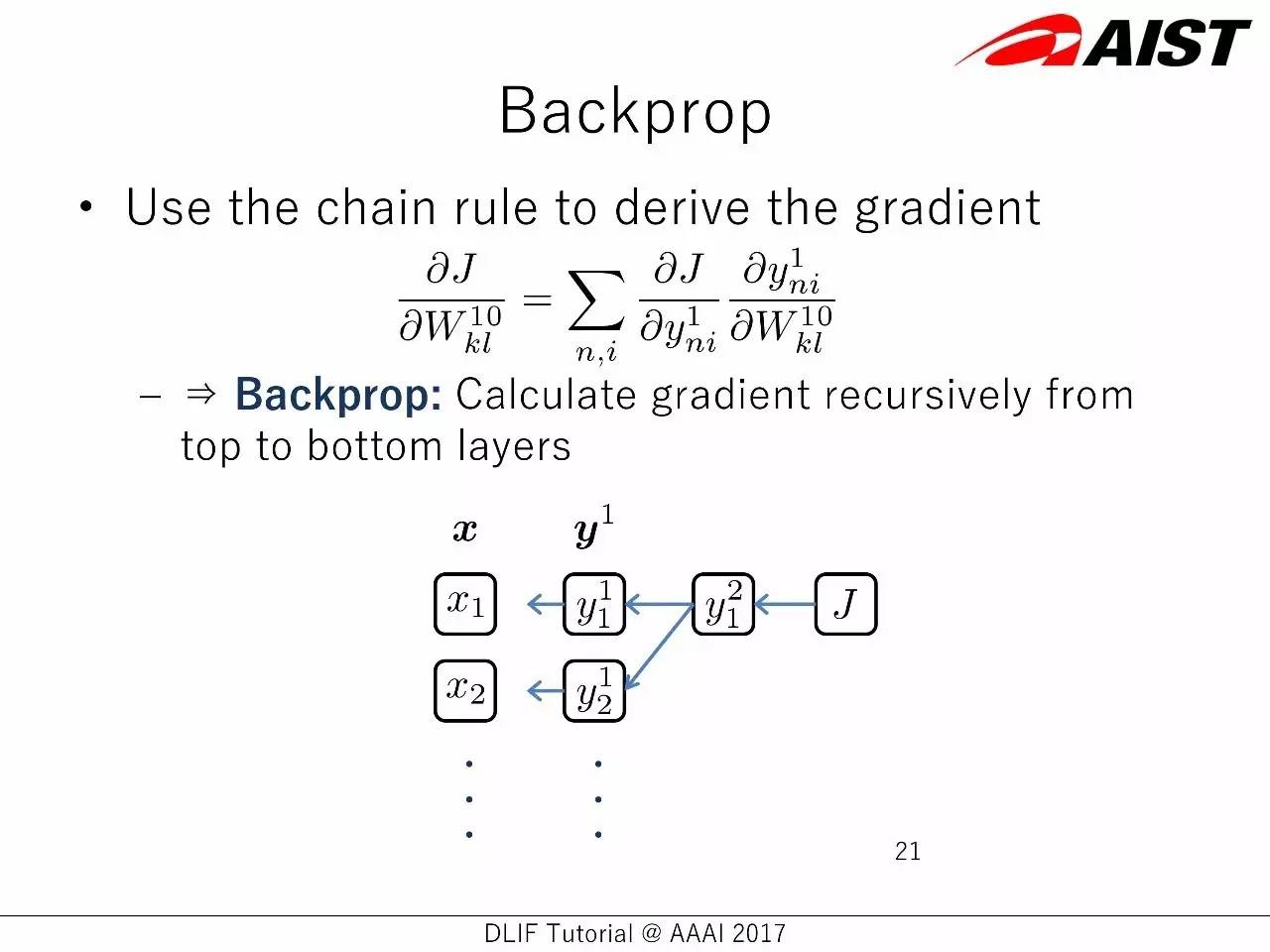
反向传播:
使用链规则来获得梯度
反向传播:从顶层到底层,计算梯度的回归
自动差分:
不需要考虑链规则
反向传播的计算是手动的,而且枯燥的
在定义了神经网络架构后,梯度能够自动地被计算
这被称为自动差分(这是利用链规则的一般概念)
在算法上的定义
区分了象征的差分和数字的差分
参数升级的诀窍
梯度下降
动态梯度下降
vanilla SGD 的更快变化
常见的错误和过拟合
学习的目标是减少常见错误,以及此前没见过的数据中的错误。
但是,当前使用的数据中的错误太少(过拟合)也不是好事(甚至是有害的)。
如何检查过拟合?
把数据分成两个部分:训练数据集、测试数据集。
实践上的考虑
架构:有多少层/单元? 卷积、循环、残差连接
权重初始化:随机、预训练、从另一个已经训练好的网络进行迁移
避免过拟合的技巧:Dropout,Batch正则化
可视化
第二部分 神经网络部署的常见设计
目标
深度学习框架如何表征和运行神经网络。
各种深度学习框架中常见的技术堆栈。
对技术堆栈的例子的检验:Chainer、TensorFlow、Theano、Keras
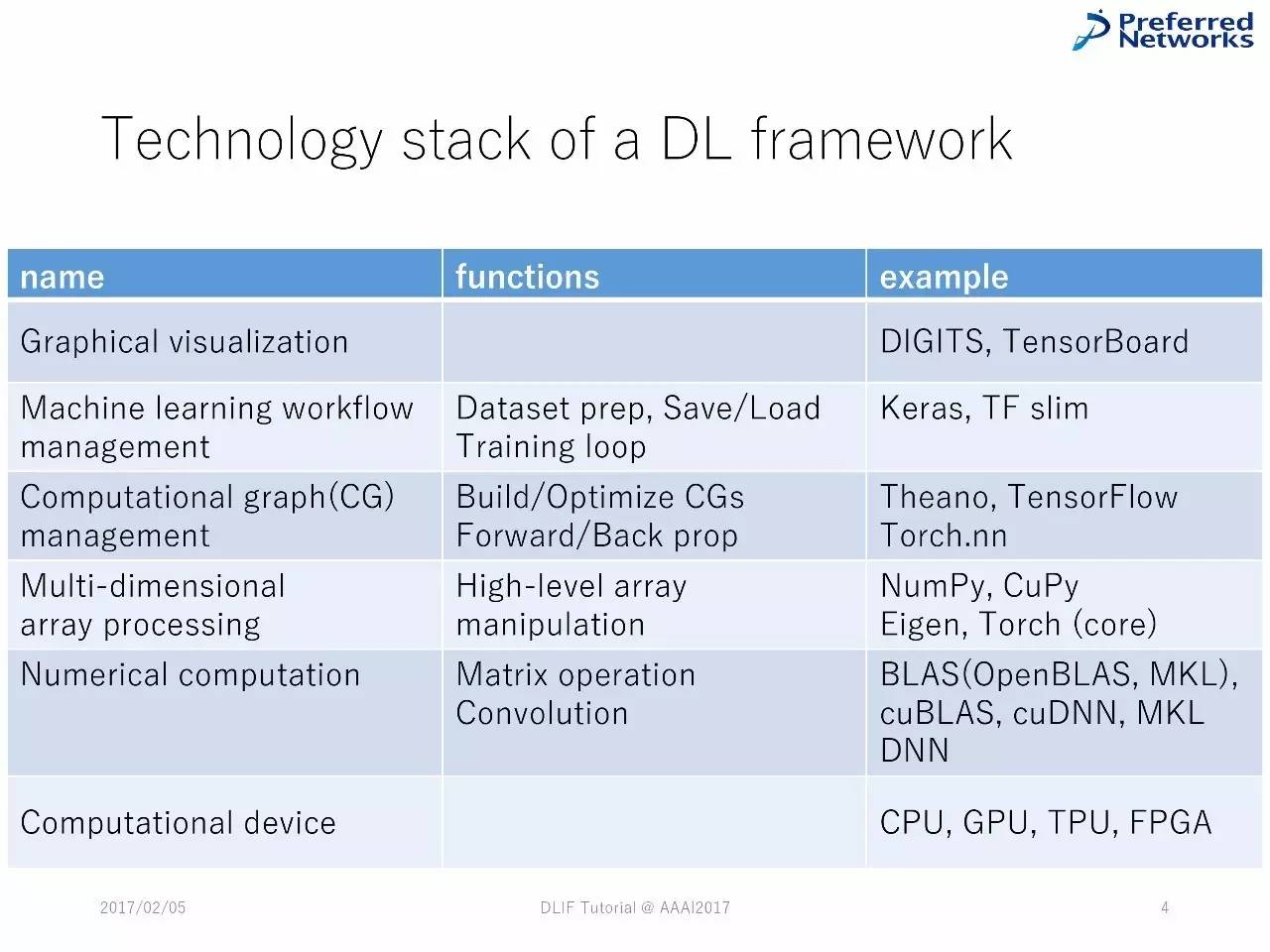
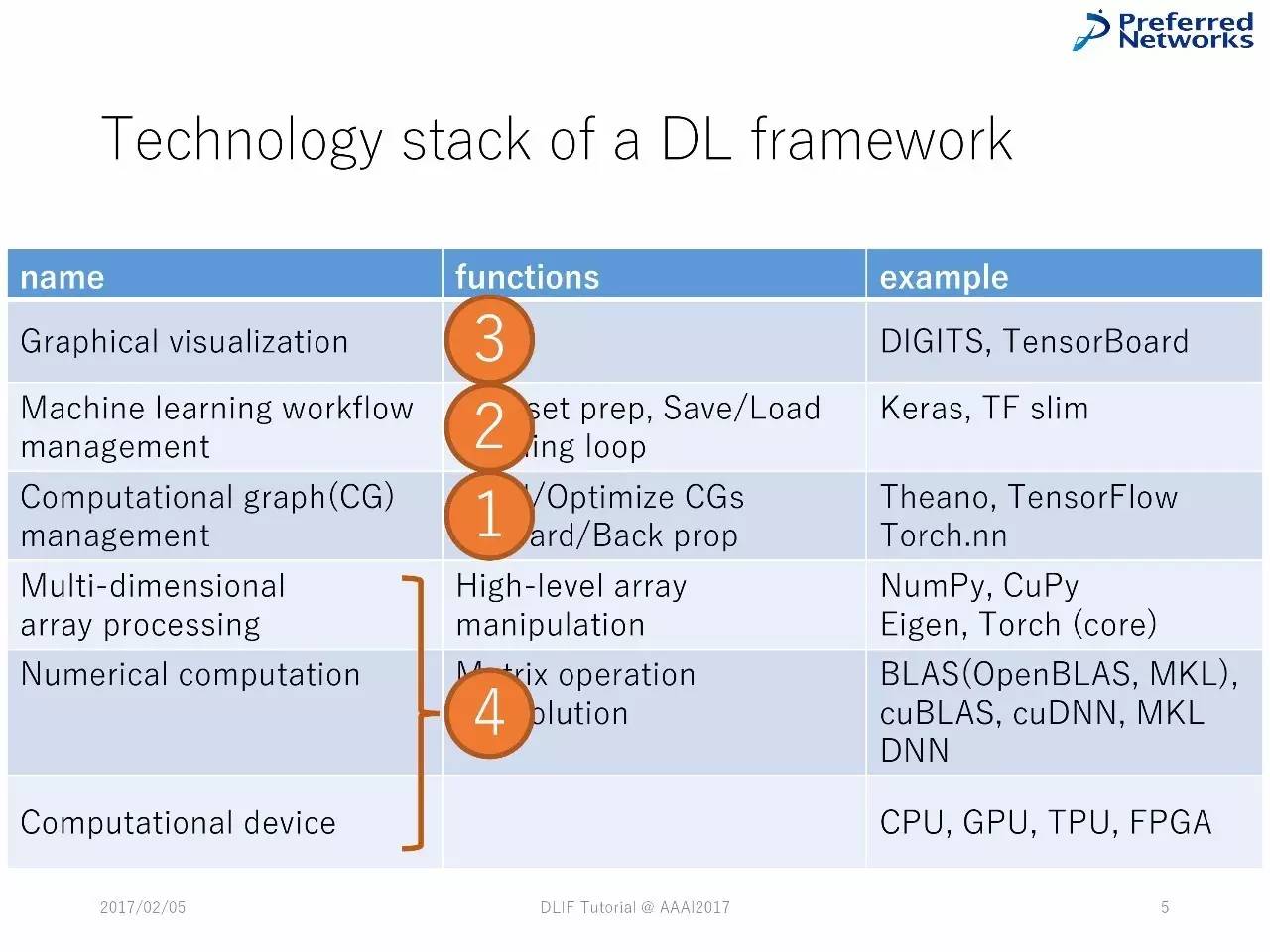
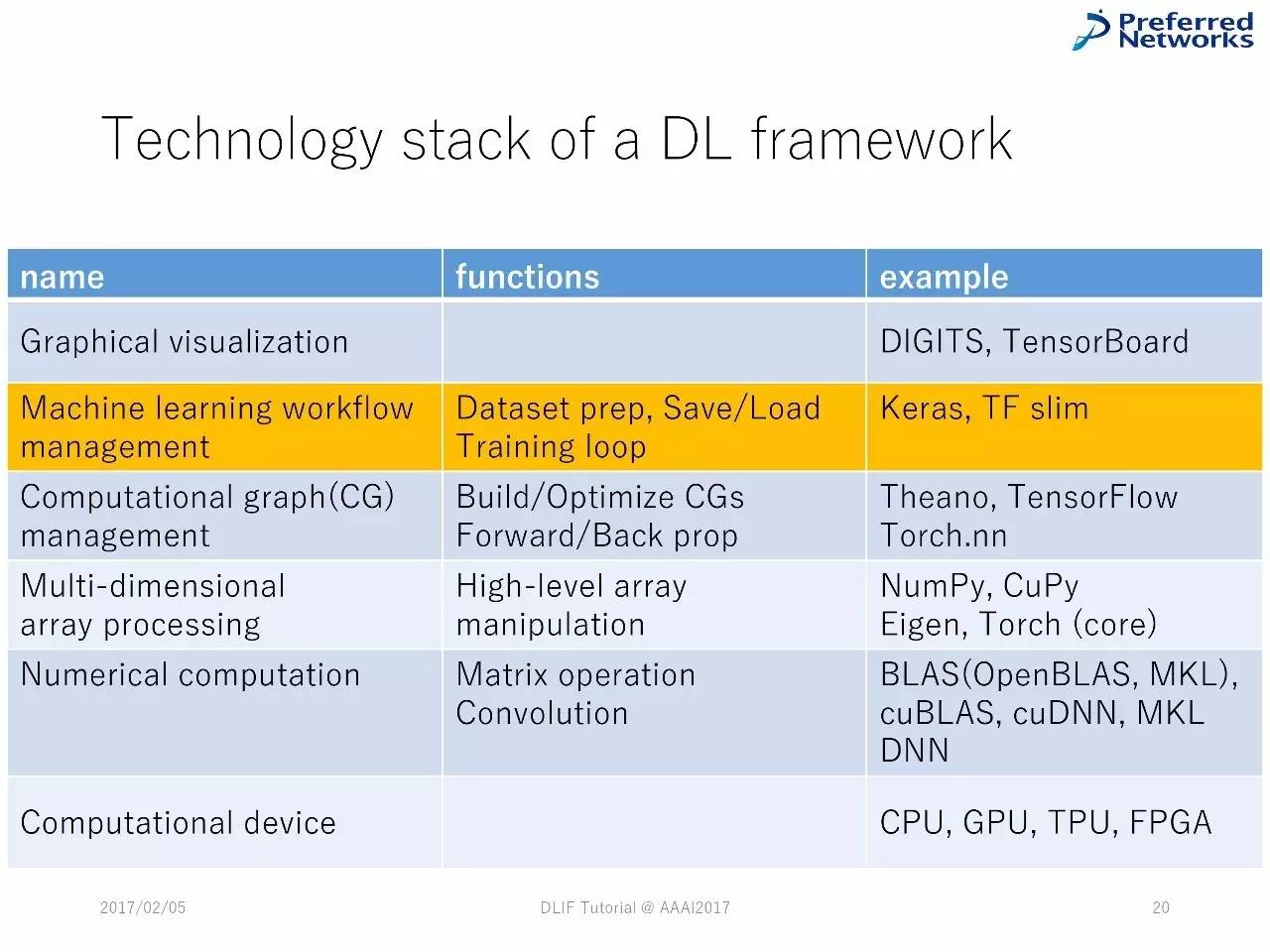
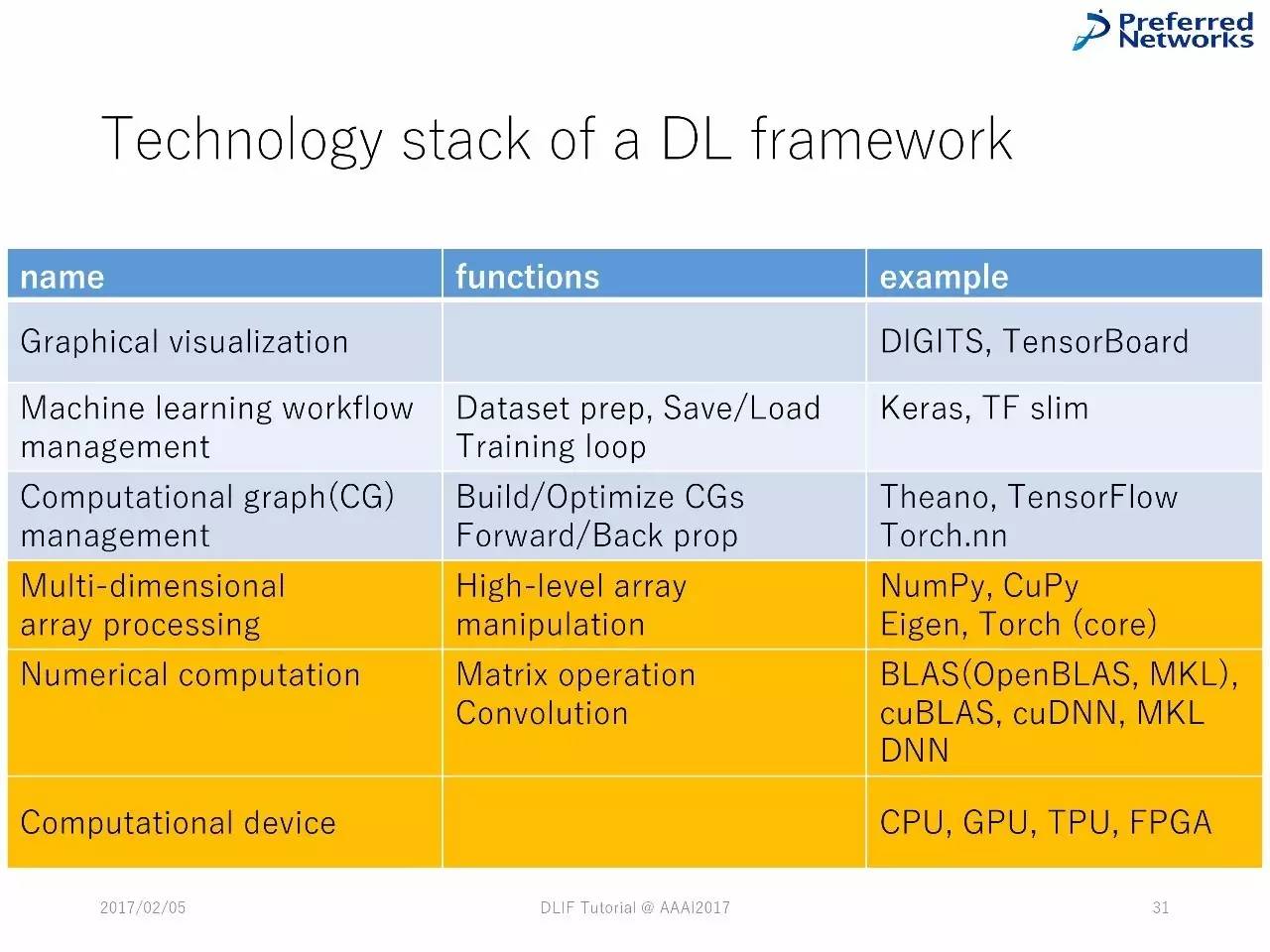
深度学习框架中技术堆栈的列表
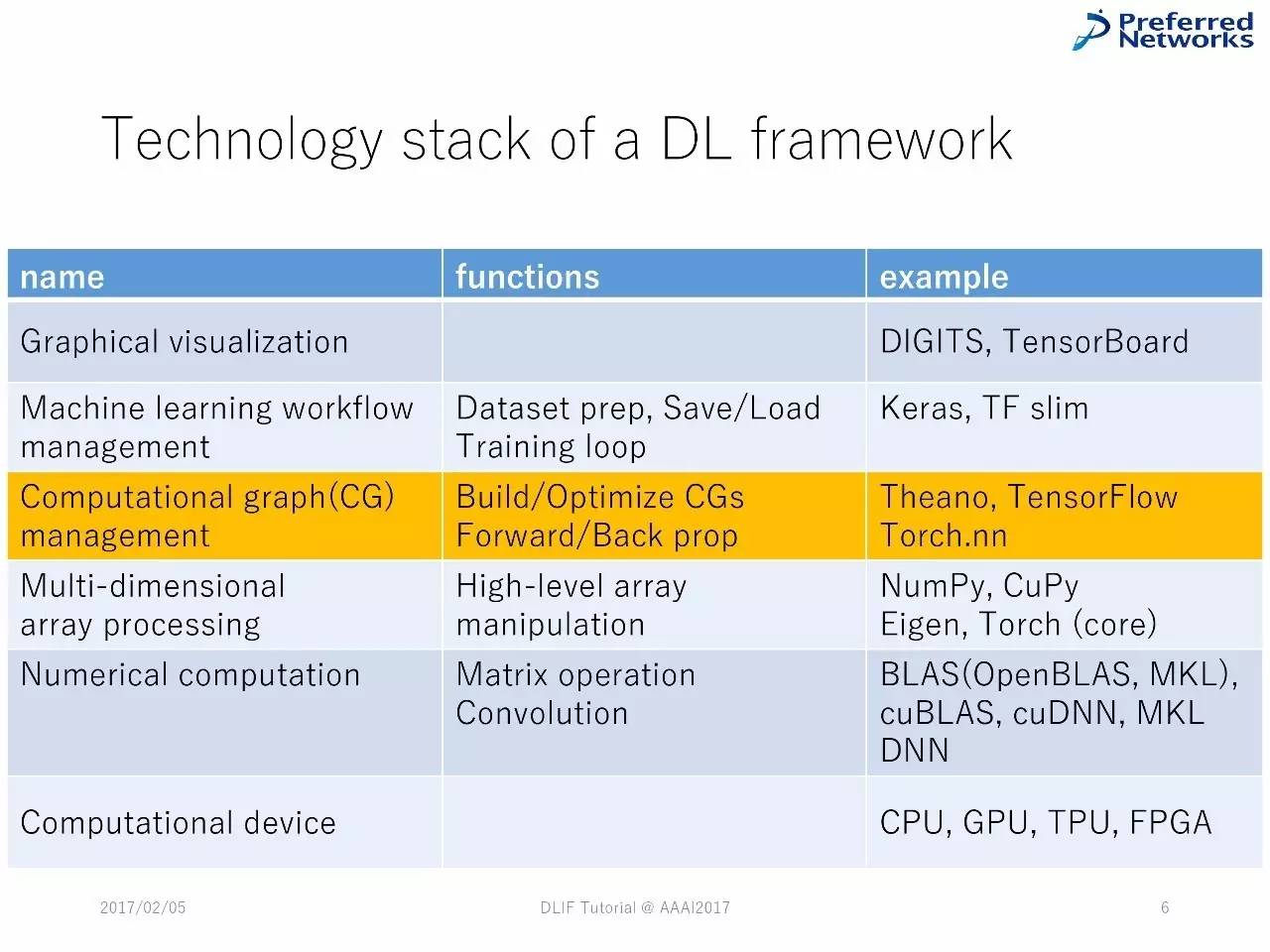
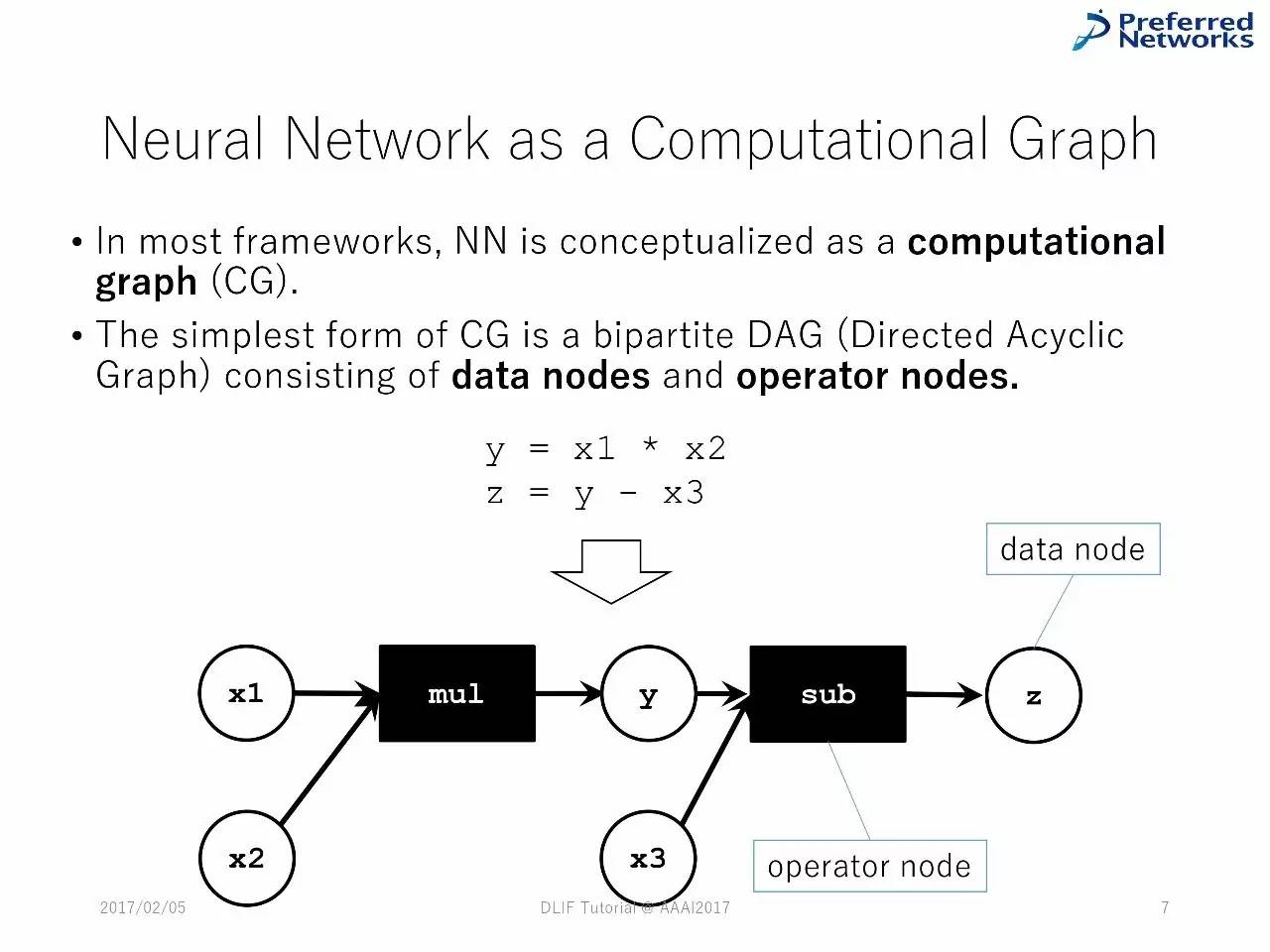
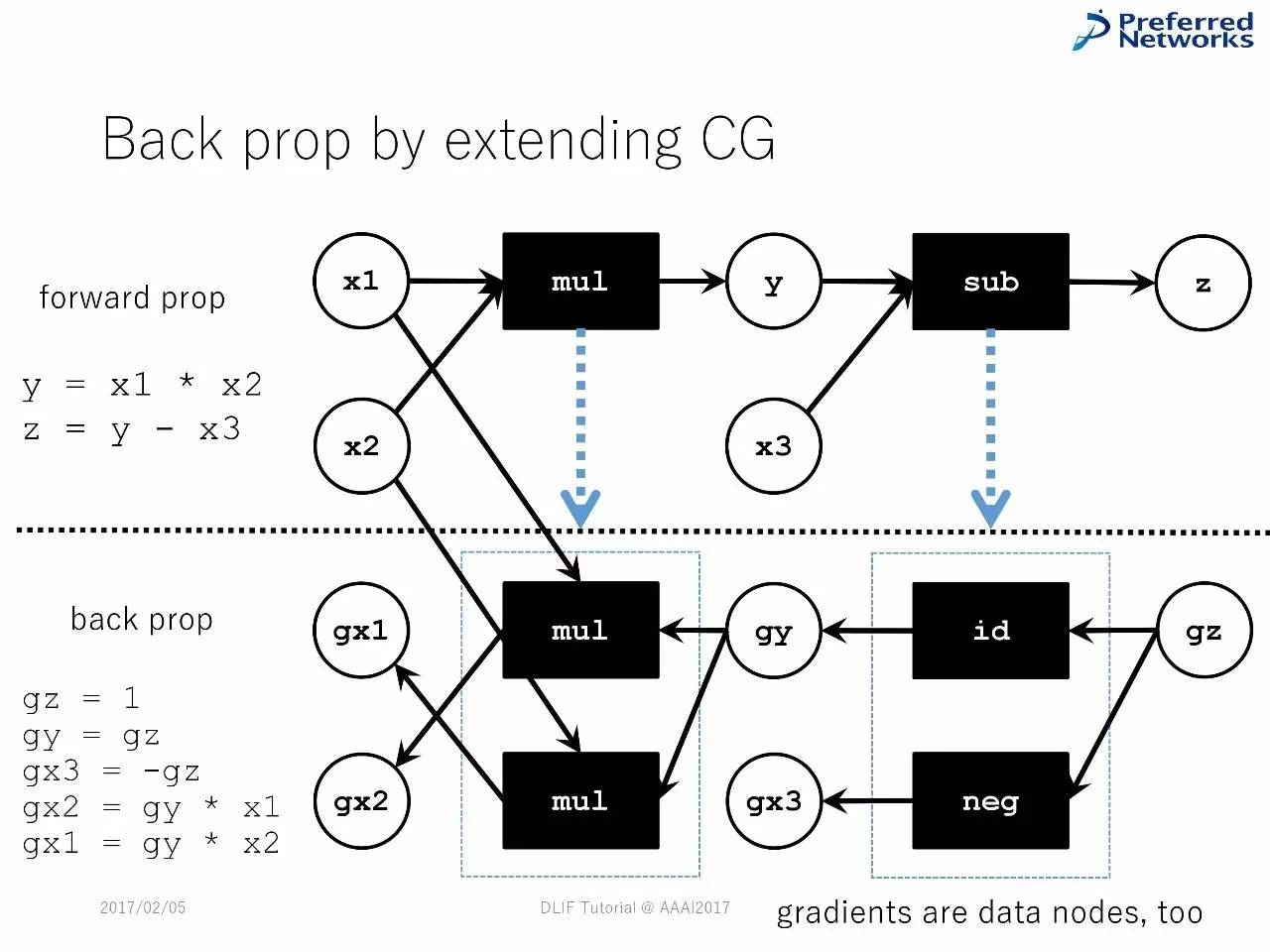
作为一种图计算的神经网络
在绝大多数的框架中,神经网络被当成一种图像计算。
最简单的图计算形式是双边的DAG(直线非循环图),由数字节点和操作节点组成。
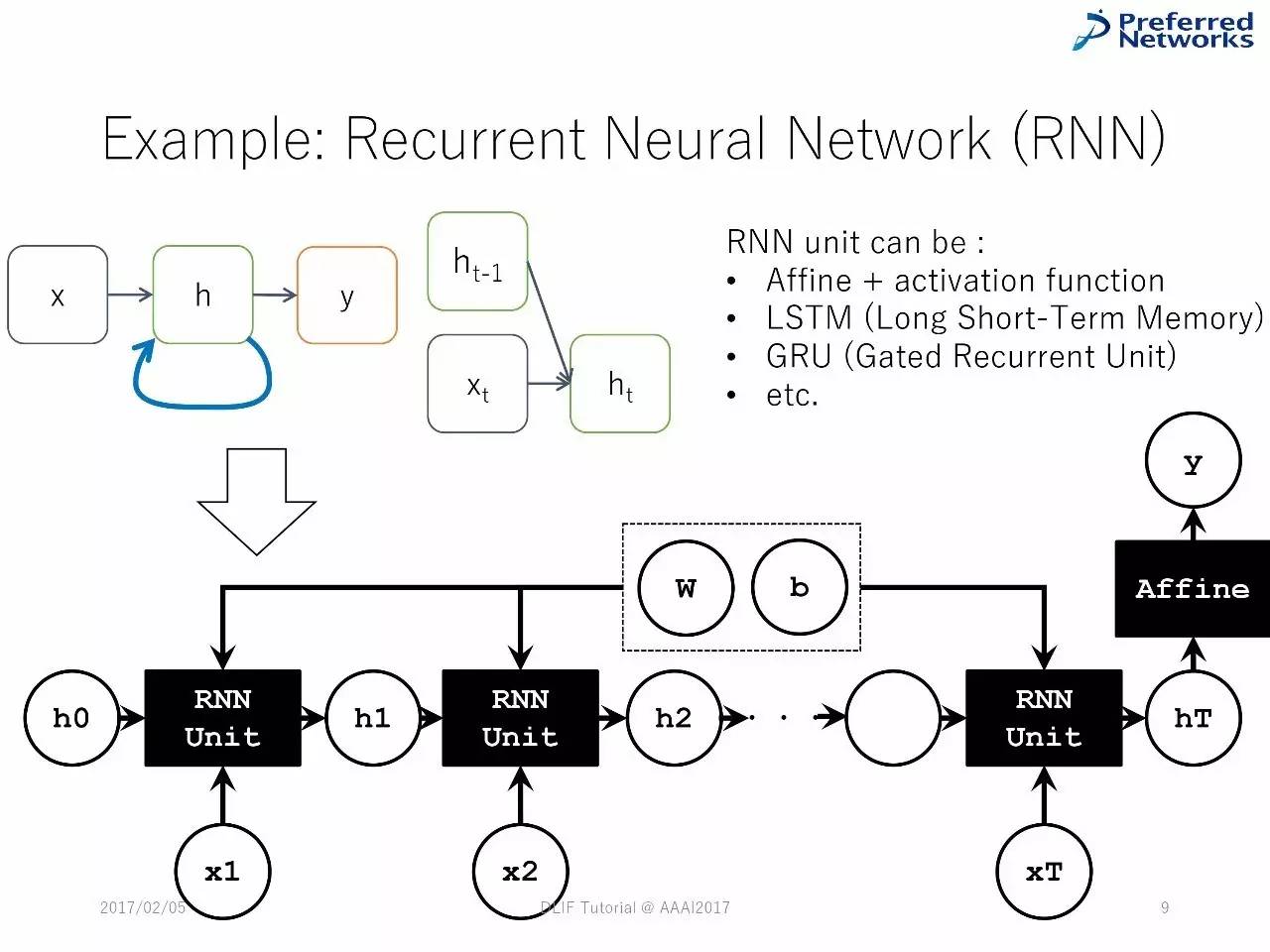
例子:多层感知机
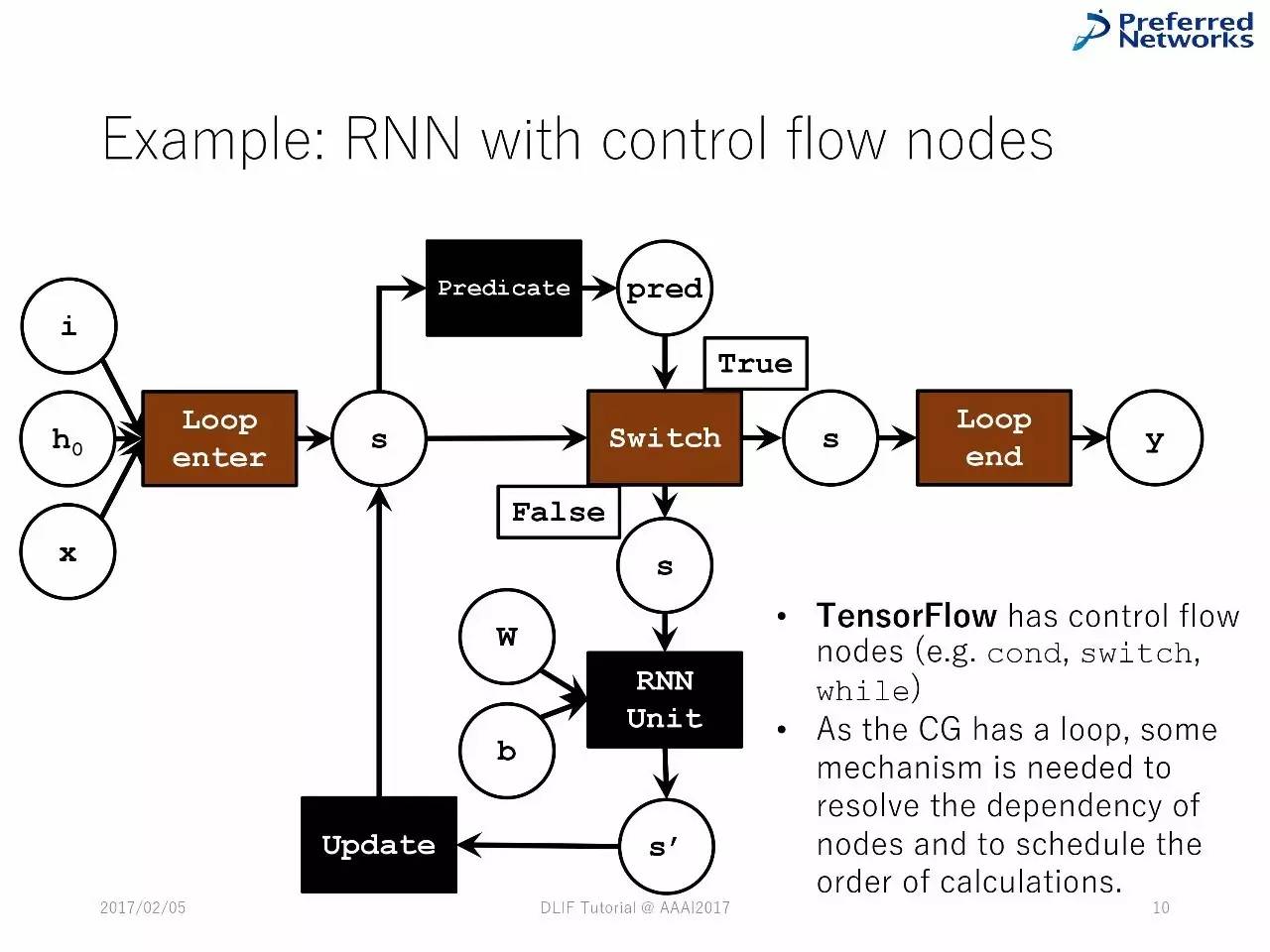
例子:循环神经网络
控制流动节点的循环神经网络
例子:对抗生成网络
对抗生成网络由生成器和辨别器组成
生成器和辨别器可以是任意的图计算
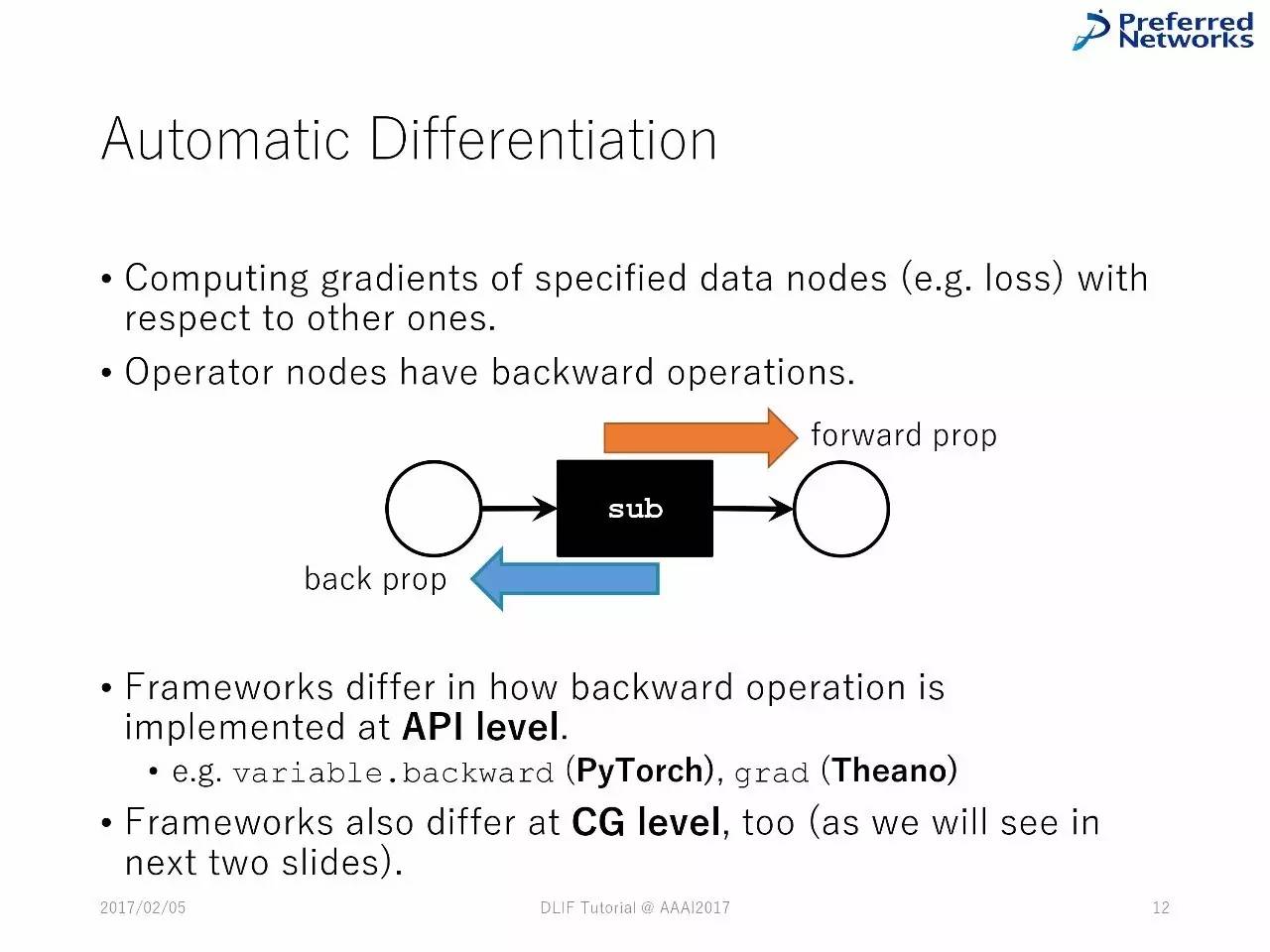
自动差分
计算特殊数字节点(比如损失)的梯度
操作器节点有反向操作
在API上,反向操作的不同会造成框架的不一样
框架在图计算上也有差别。正如以下两张PPT中展示的那样
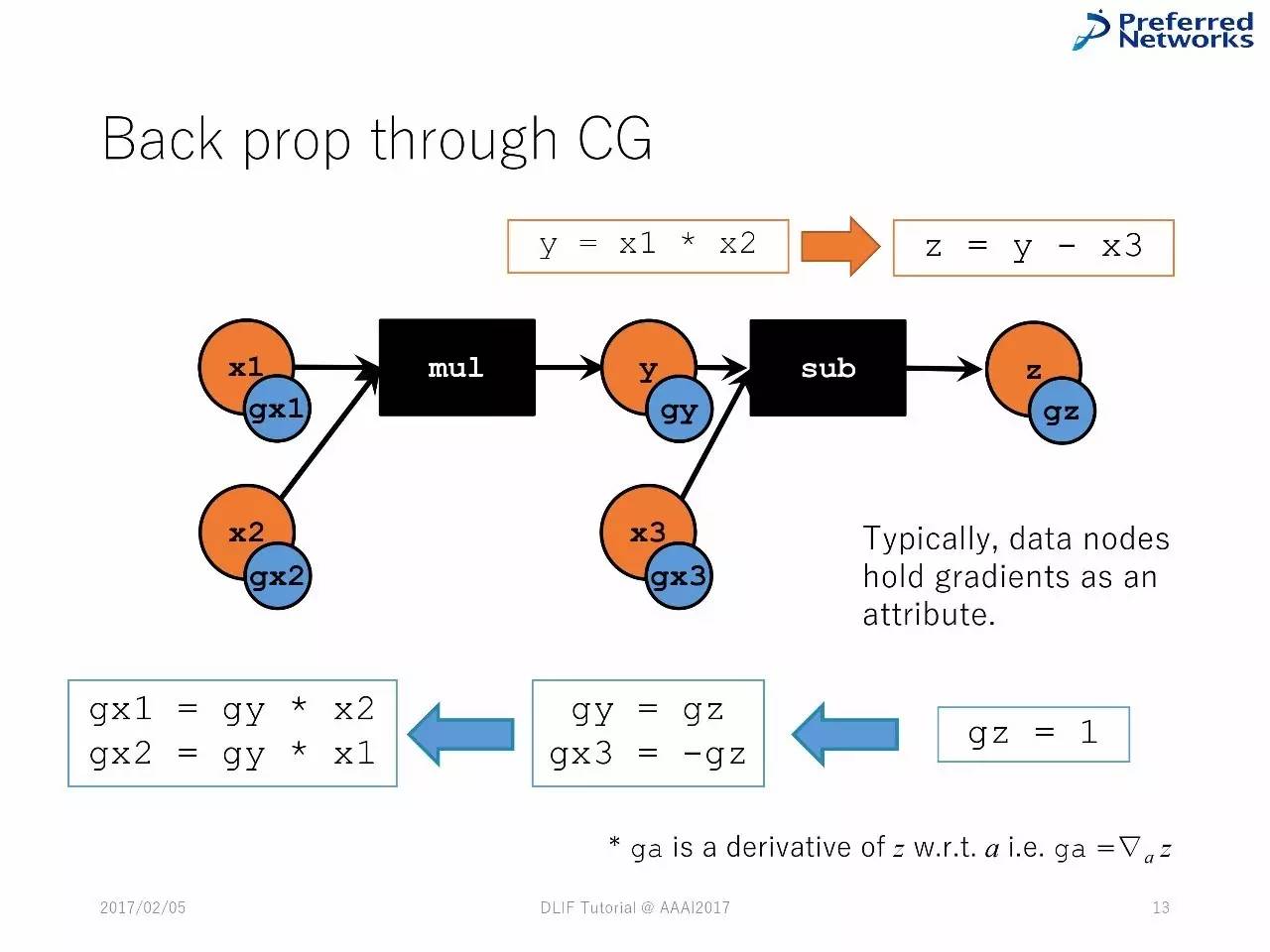
图计算中的反向传播
延展图计算中的反向传播
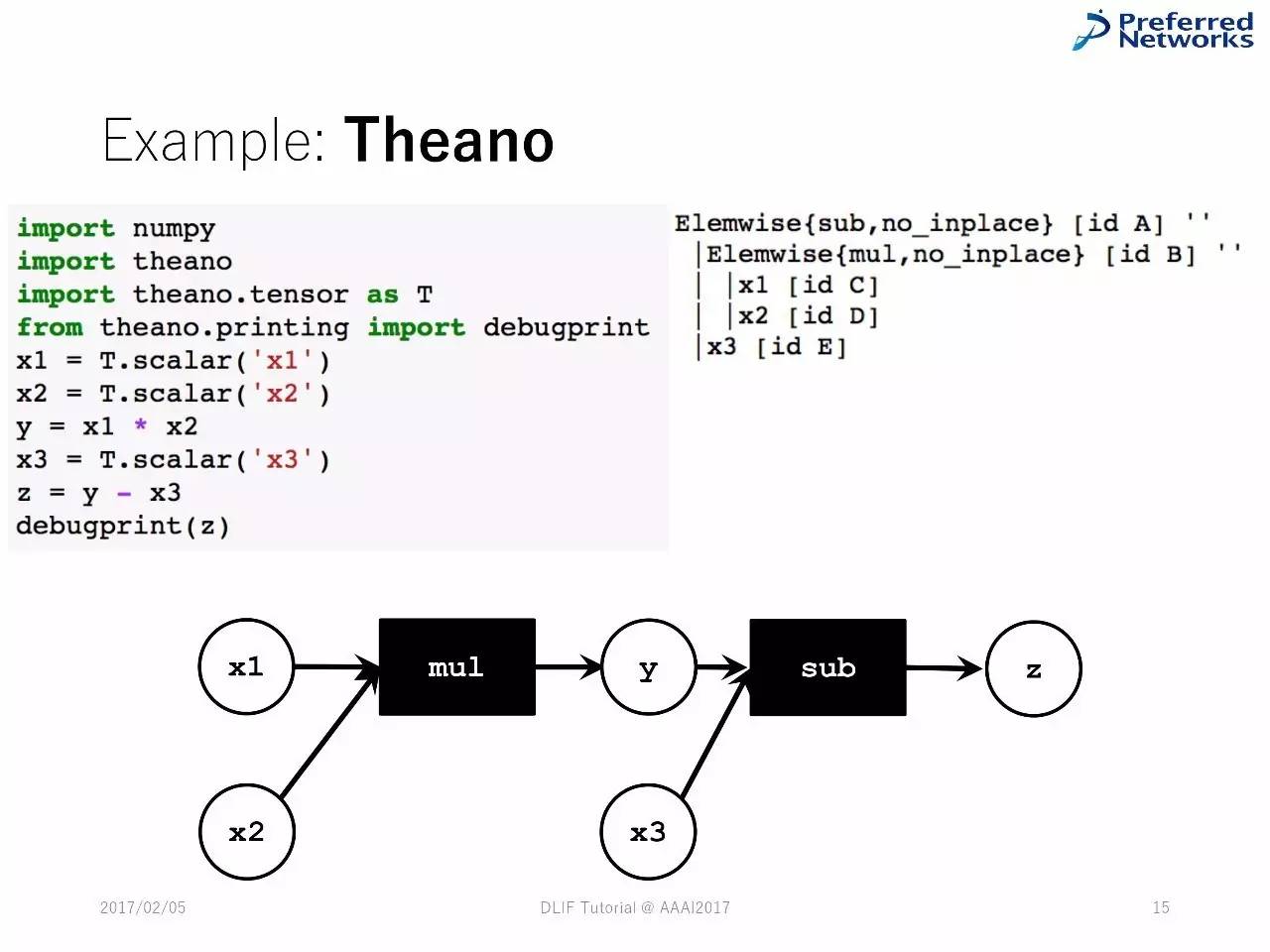
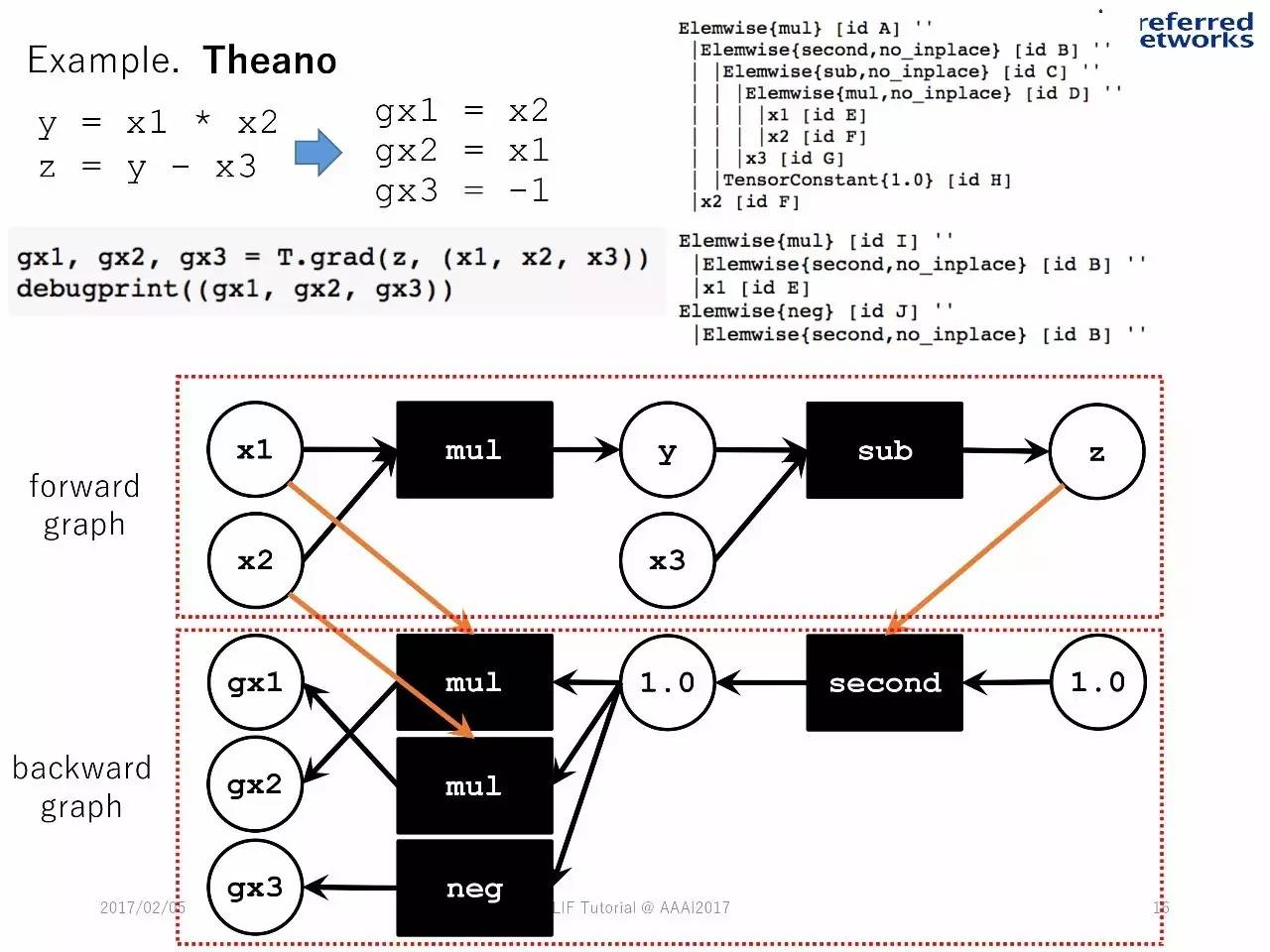
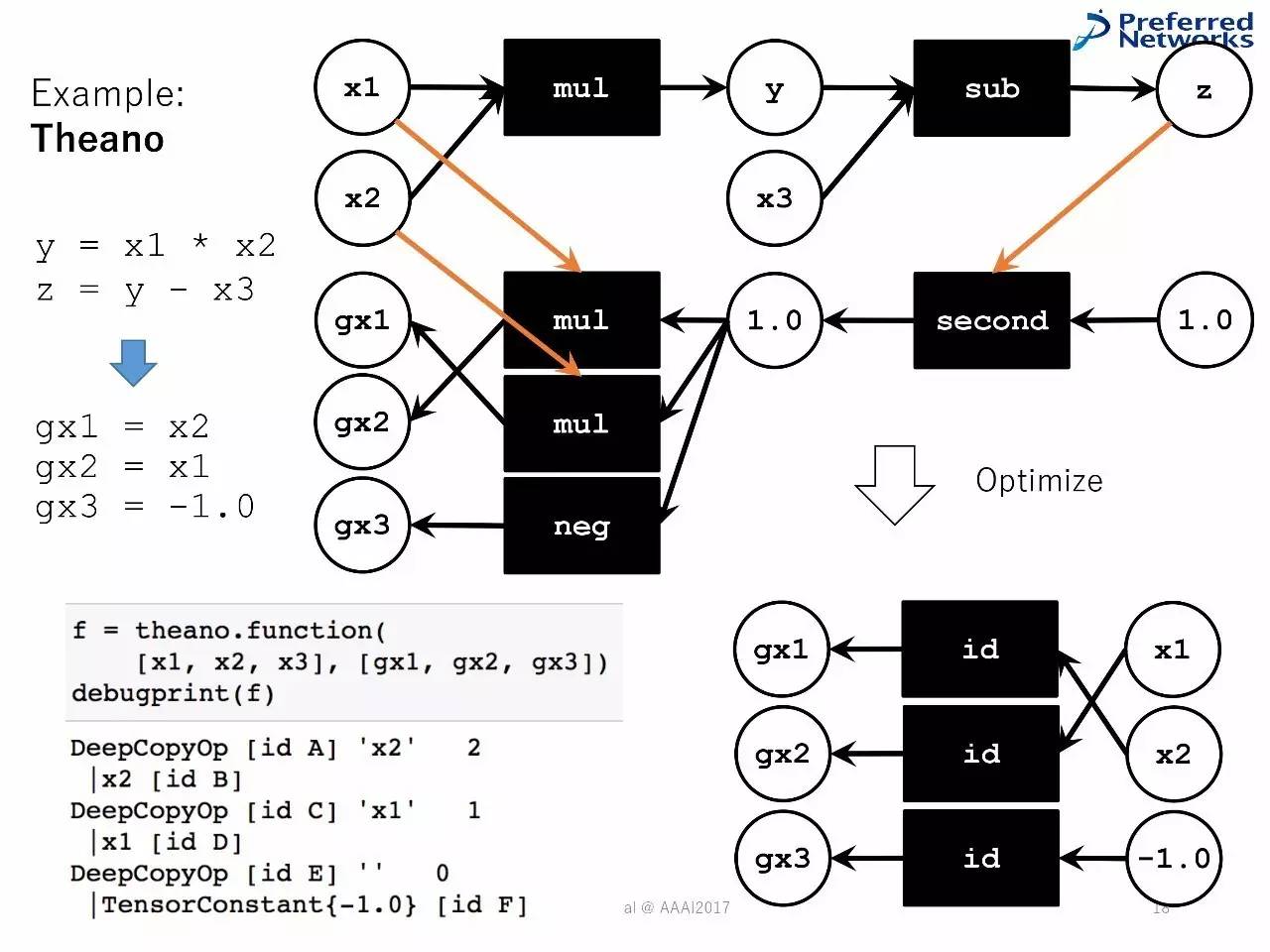
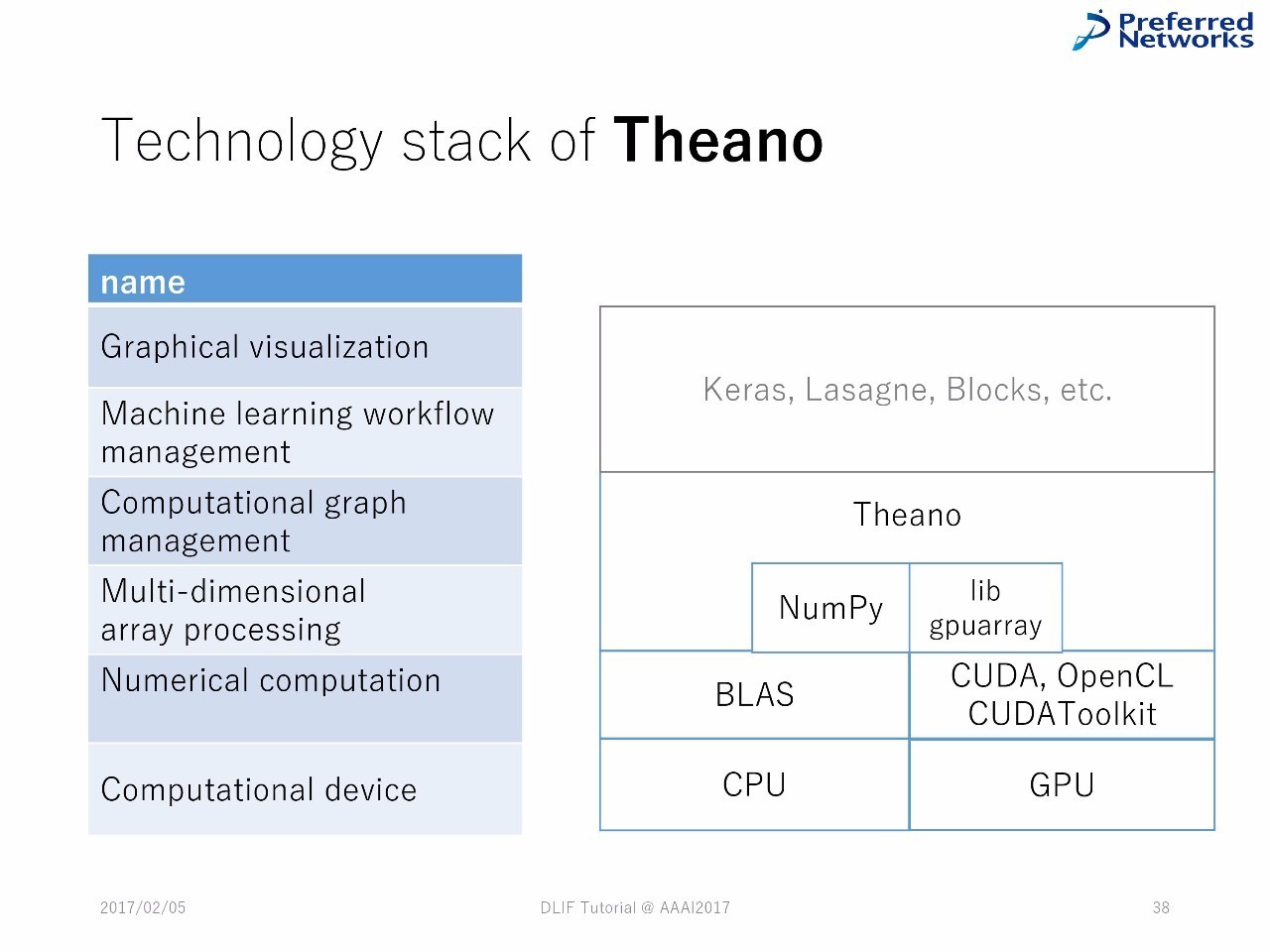
例子:Theano
计算的优化器
将图计算变成简单和高效的:删除冗余节点、用内置的操作器,以减少记忆足迹。
以Theano为例
数字优化器
DL框架中的技术堆栈
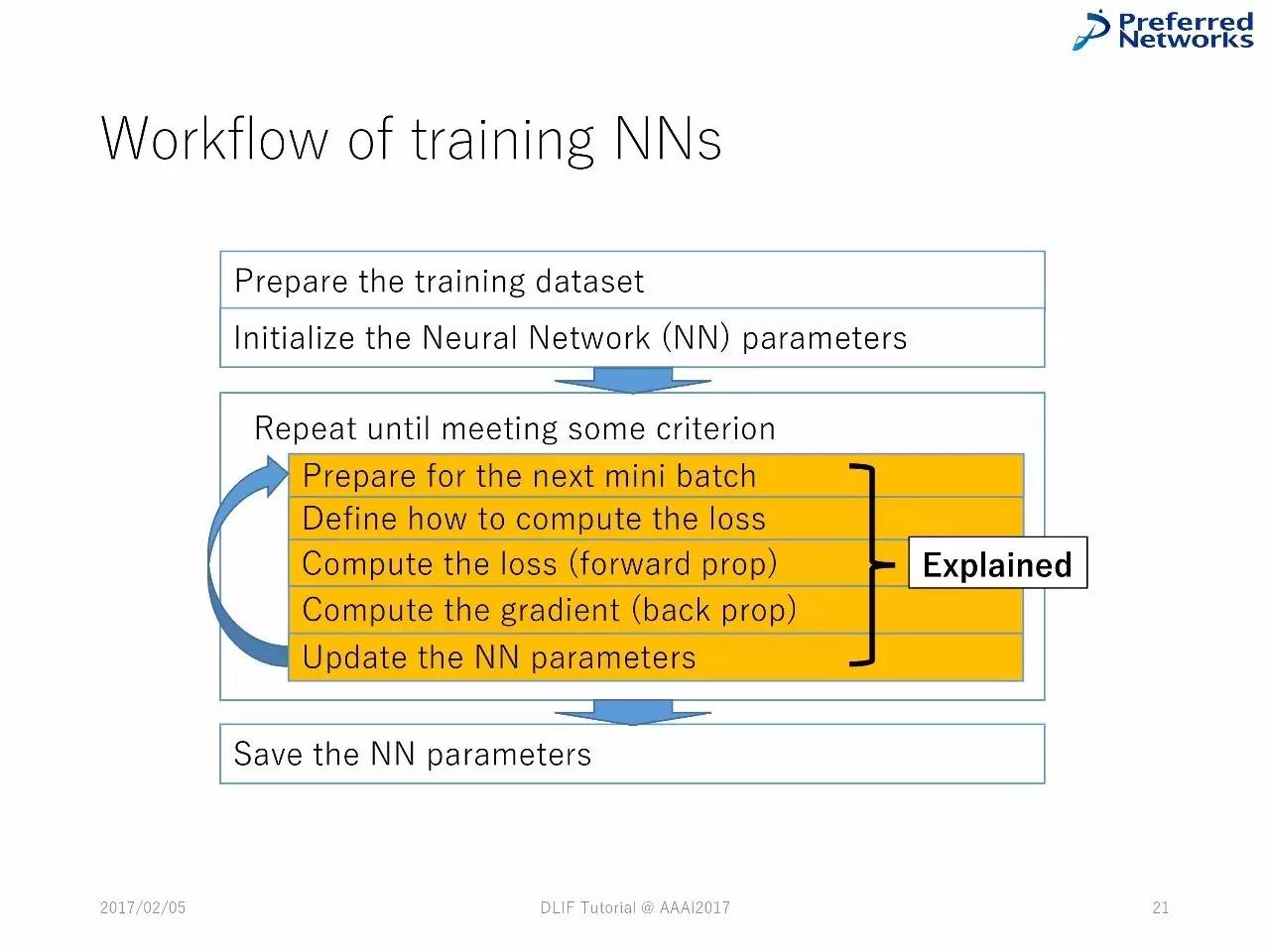
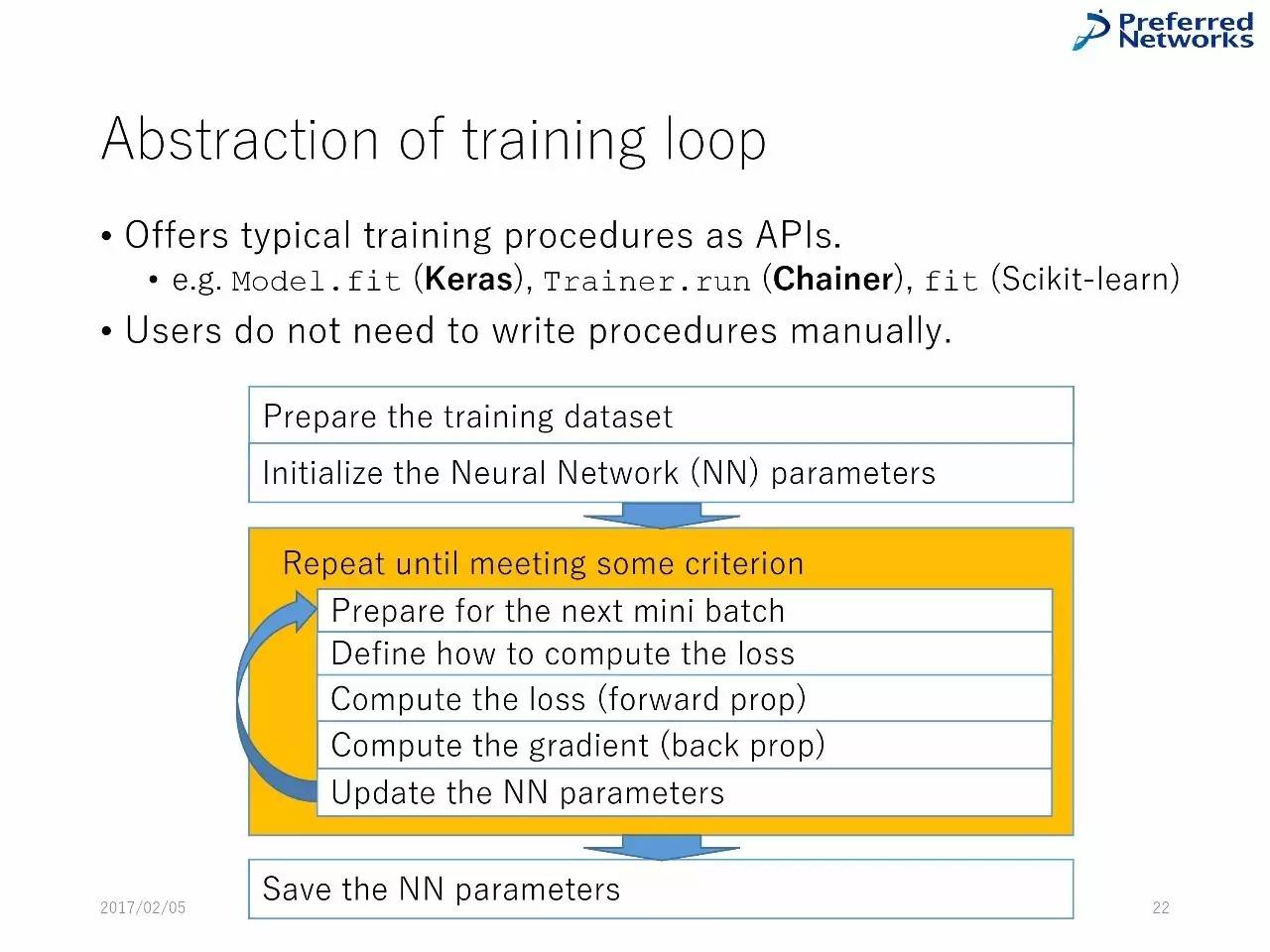
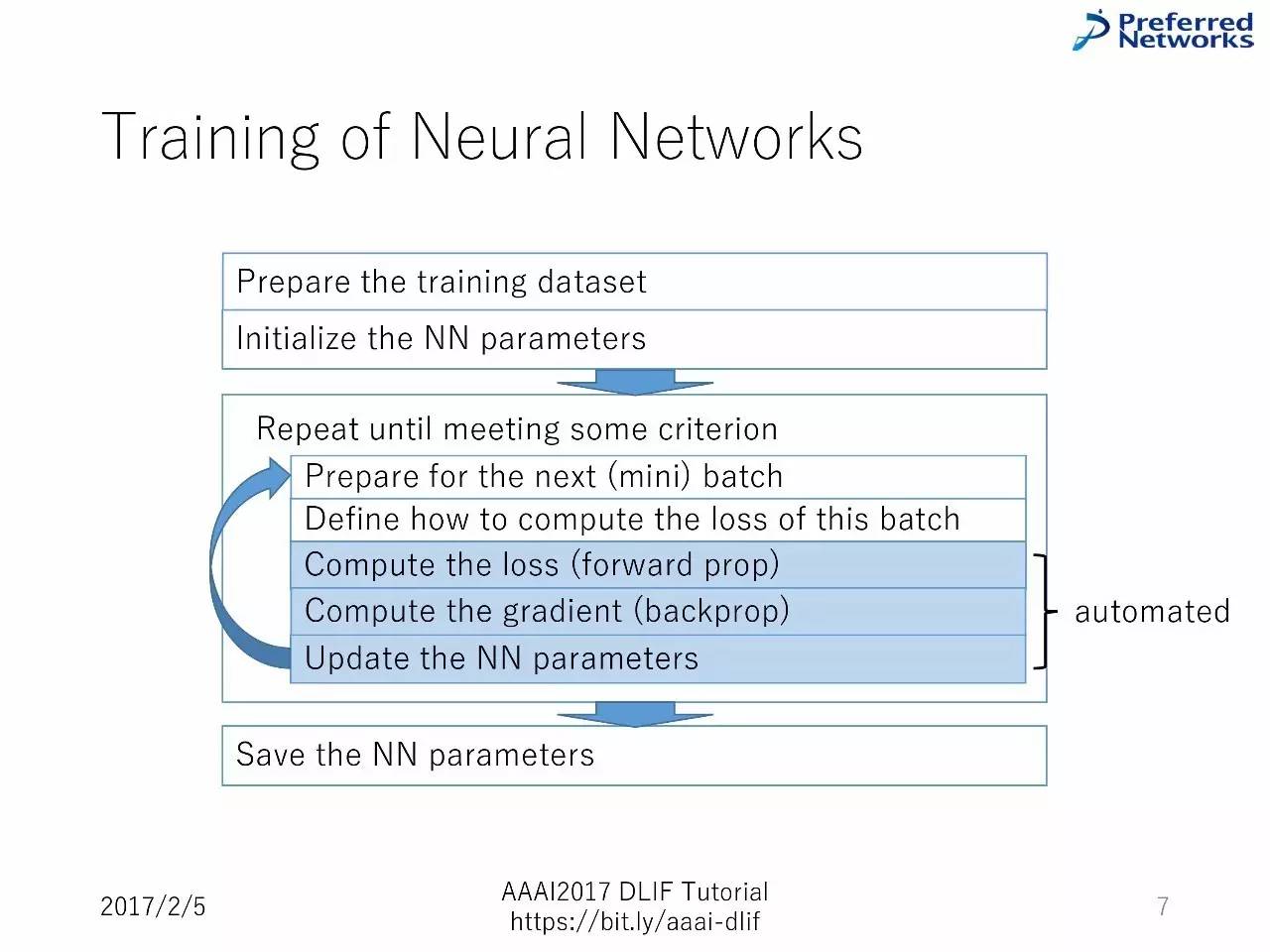
训练神经网络的工作流程:
准备数据集--对神经网络参数进行初始化--不断重复知道得到一些标准的东西--准备好进行下一次小的batch--定义如何计算损失--计算损失(前向)--计算梯度(反向)--升级神经网络参数--保存神经网络参数。
训练的精华内容:把典型的训练程序作为API,用户不需要手动写程序。
数据载入
支持从大型的数据库中载入预先定义的数据,比如,MNIST、CIFAR、PenTreeBank等等。
训练过程的序列化
什么是序列化:训练过的模型(也就是神经网络的架构和参数)、训练过程的状态。
序列化可以提高模型的可移植性
预训练模型的发布:
用户可以在自己的任务总使用与训练的模型
许多框架,包括Caffe、MXNet 和 TensorFlow 都推出了大的模型(比如,VGG, AlexNet 和ResNet)
虽然分享预训练模型的大型网站很少,比如说 Model Zoo,但是,许多作者还是会私下分享他们的模型。
从其他框架中引入预训练模型:比如,Chainer 支持Caffe 的 BVLC-official 参考模型
并行计算:模型的并行和数据的并行
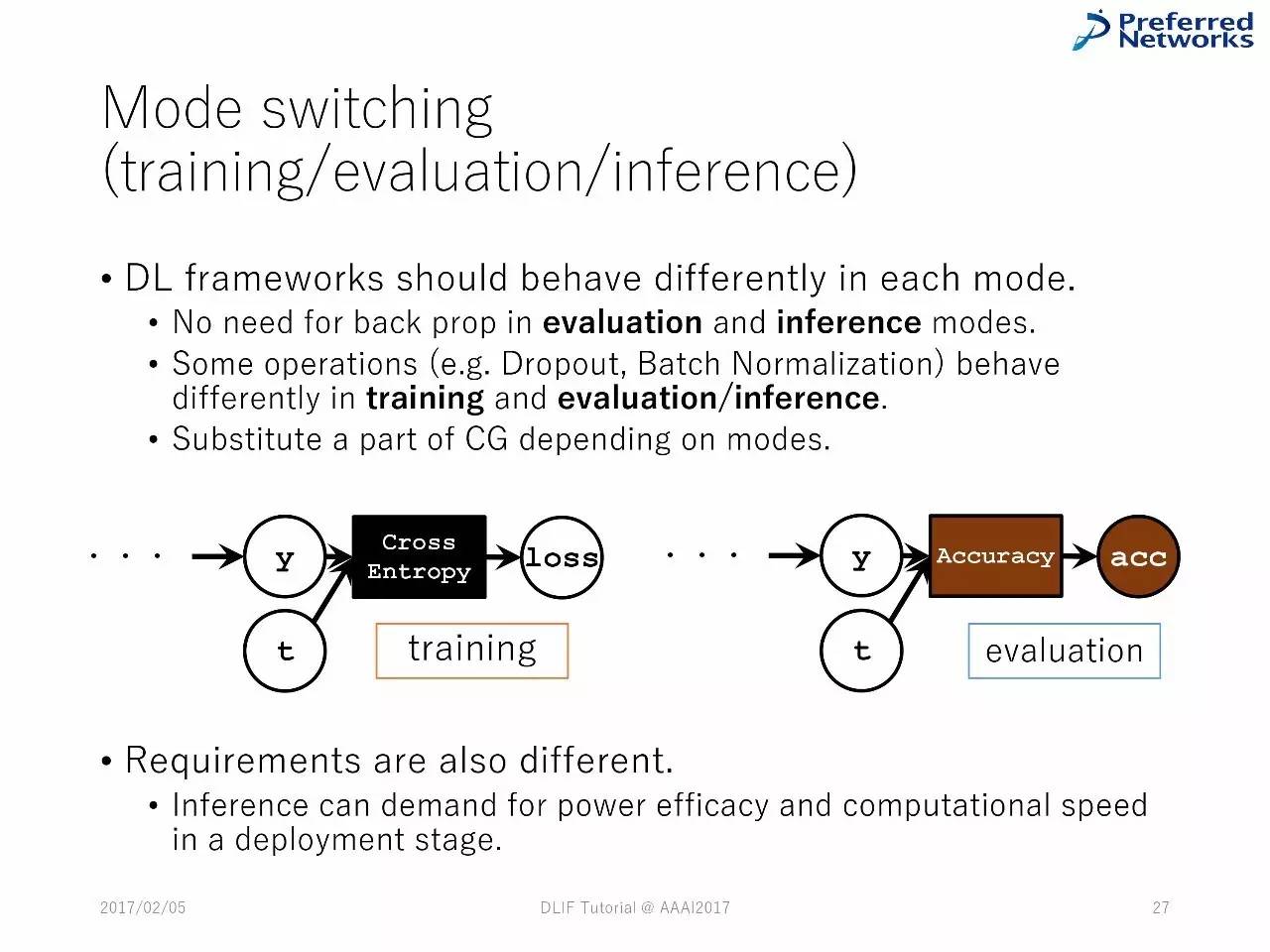
在每一种模式中,深度学习框架应该有不同的表现。
在模型的衡量和推理中,不需要反向传播
一些操作,比如Dropout和Batch 正则化,在训练和衡量或者推理中,是不同的。
图计算的替代依赖于模式的不同
深度学习框架中的技术堆栈
图的可视化:帮助用户用更加简便的工具来开发模型。
设计、监测和分析都可以使用。
深度学习框架中的技术堆栈
GPU 支持:绝大多数深度学习中的计算包含了大型的矩阵乘法和函数应用,GPU可以加速这些计算。(在大多数的情况下)。
DL 框架可以在CPU 和 GPU 间无缝切换。一般来说,框架会通过隐藏的CUDA来支持GPU。
多维数组库(CPU/GPU)
负责数据节点中的具体计算
严重依赖于BLAS(CPU)或CUDA 工具(GPU)
第三方库:Tensorflow(CPU/GPU)、 NumPy (CPU)、PyCUDA(GPU)、 gpuarray (GPU)。
Scratch:ND4J,mshadow(MXNet),Torch,Cupy (Chainer)
大多数的GPU 数组库希望能在CPU和GPU中进行切换。
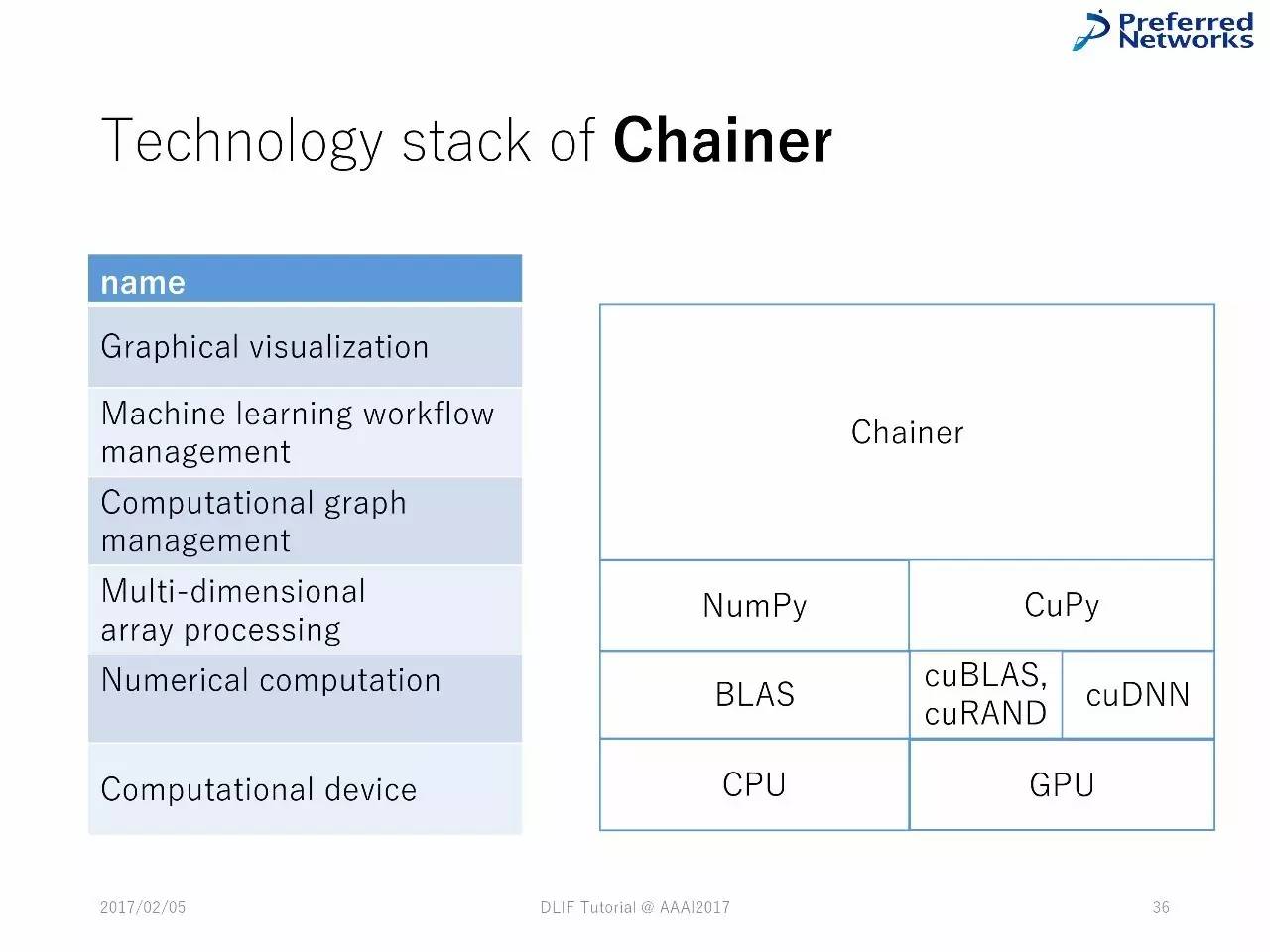
例子:Chainer/CuPy
使用哪一个设备?
GPU是第一选择,但是,GPU 不是一个永远正确的选择。
Chainer 中的技术堆栈
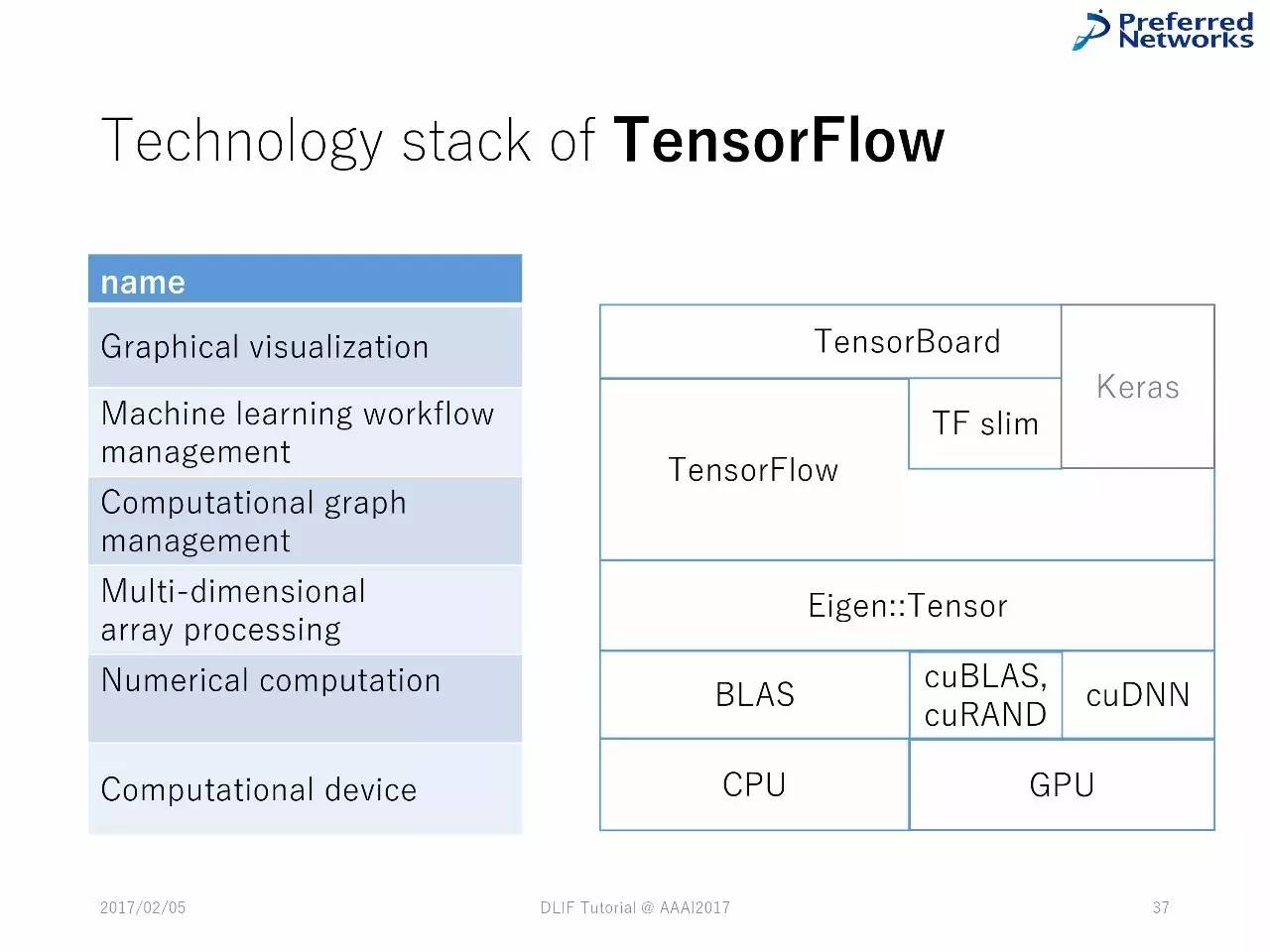
TensorFlow 中的技术堆栈
Theano 中的技术堆栈
Keras中的技术堆栈
总结
绝大多数的深度学习框架的组件都有共通之处,由类似的技术堆栈组成。
在更层的堆栈中,框架被设计用于支持用户完成典型的机器学习流程。在中间层,对图计算的操作是自动化的。在最更底层,经过优化的向量被采纳。
对这些组件的不同实现,会造成框架的不一样,正如我们在下面这部分会看到的。
第三部分 各种深度学习框架的不同
这一部分的目标
列举神经网络框架设计的选择
介绍既有的框架在这些选择上的客观区别
每个主题都有两个或者更多的选择
每个选择的好处和坏处
在Chainer中实践的例子
大纲
回忆训练神经网络的步骤
对既有的框架进行快速地对比
设计选择的细节
神经网络的训练步骤(上文已经提到过)
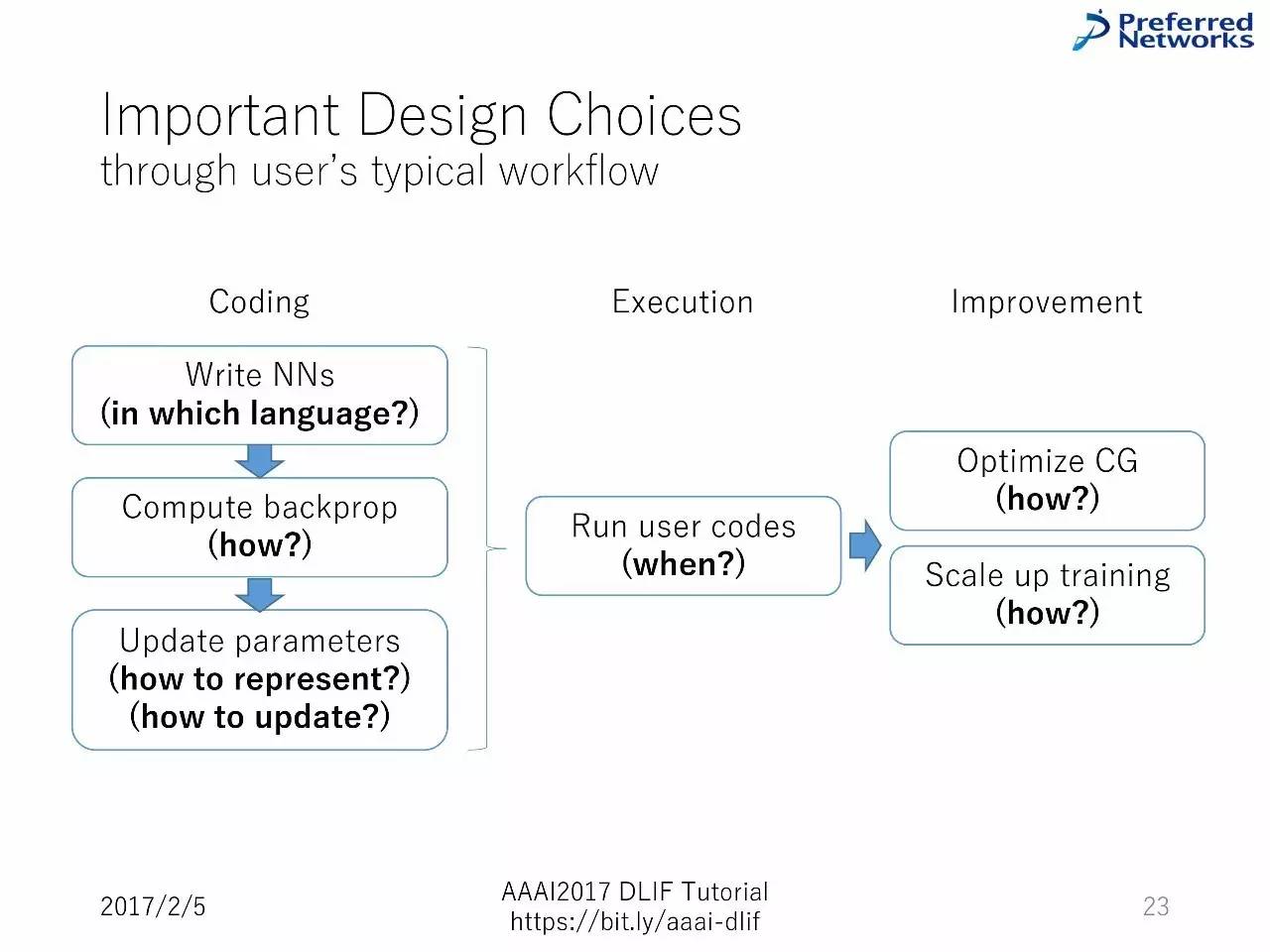
用户典型的工作流
从编码到执行再到提升
写代码—计算反向传播—升级参数—运行用户的代码—优化图计算和扩展训练
框架设计选择
神经网络中最关键的部分
如何定义要优化的参数
如何定义参数的损失函数=如何写计算图
这也会影响用于前向传播、反向传播和参数更新的API
所有的这一切都取决于如何运行计算图
其他部分也很重要,但是大多数与运行其他类型的机器学习方法类似
对既有框架的快速对比
框架列表:
Torch.nn
Theano
Caffe
Keras
Chainer
MXNet
TensorFlow
PyTorch
Torch.nn
MATLAB 类似的环境,建立在LuaJIT上
快速的脚本语言编写,CPU/GPU 支持,有统一的数列(array)后端
Theano
用于建立计算图的Python 程序包
支持图计算的优化器和编译器
Caffe
使用C++语言,神经网络的快速部署
主要聚焦于计算机视觉应用
Keras
干净的神经网络压缩API,用于Theano 和 TensorFlow
将会加入TensoFlow库
Chainer
通过动态地构建架构化的图表,支持反向传播
面向GPU,提供兼容 NumPY的数组后端
MXNet
支持混合的范式
还支持分布式计算
TensorFlow
通过分布计算快速地执行
支持一些图顶部的流动
PyTorch
Torch 的Python I/F,带有通过动态图的反向传播
有C/C++后端部署,可获得高性能
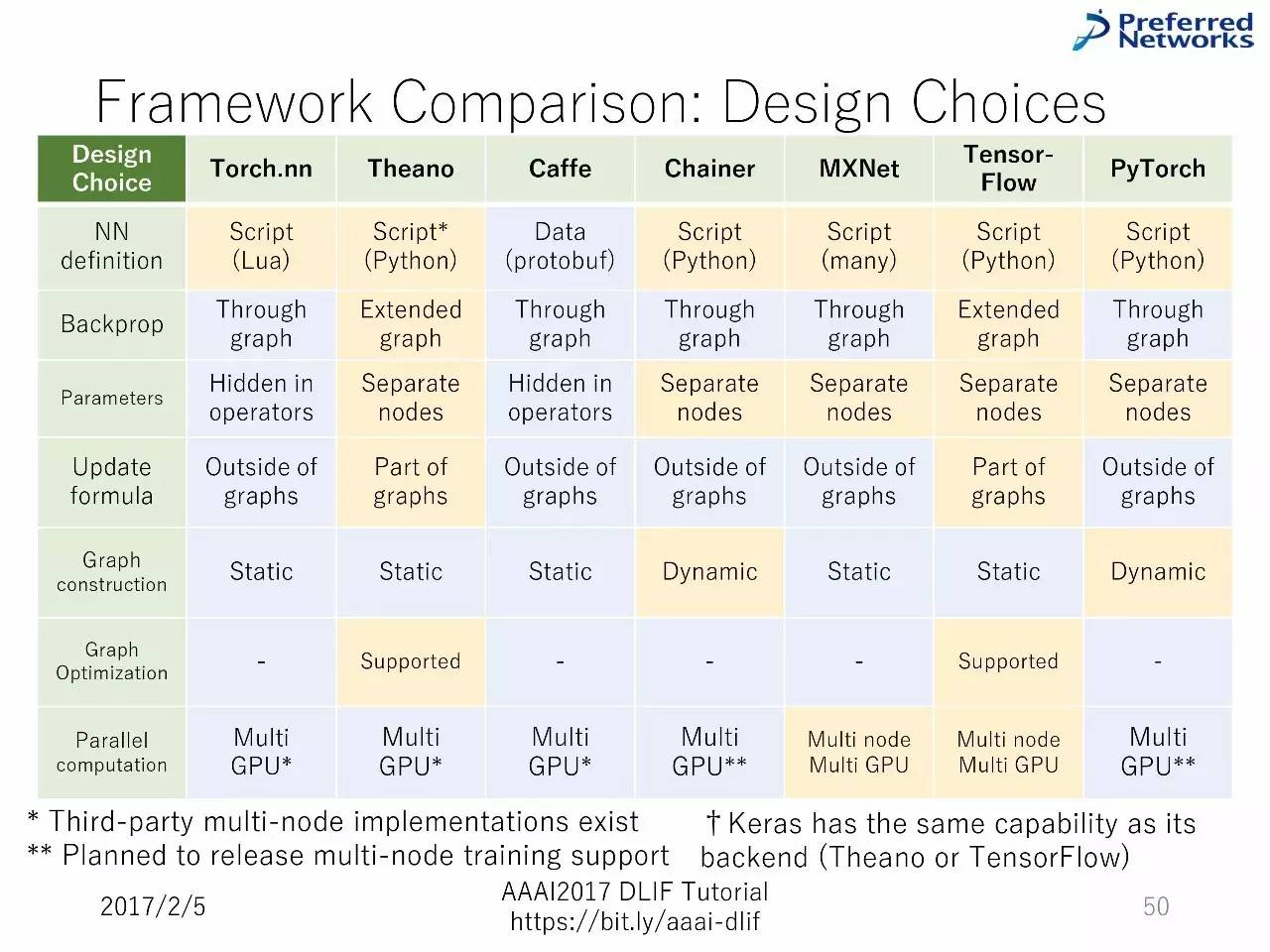
框架对比:基本信息
设计选择的细节
重要的设计选择:通过用户的典型工作流进行阐述。
如何用文本格式写神经网络
以陈述式的配置文件:框架建立的神经网络层就如写在文件中一样
通过程序上的脚背写神经网络:框架提供脚本语言的API,用来搭建神经网络
以陈述式的配置文件:高移植性,较低的灵活性。
通过程序上的脚背写神经网络:低移植性,高灵活性。
例子:50层的ResNet
在Chainer 中搭建50层的 ResNet (总共100 行代码)
如何计算反向传播
通过图的反向传播
作为扩展图的反向传播
通过图的反向传播:便于部署,反向传播的计算不需要被定义为图。但是灵活性低,因为图可用的特征可能不能用于反向传播的计算。
作为扩展图的反向传播:部署变得复杂。但是灵活性高,因为任何图可用的特征都能用于反向传播的计算。
如何表征参数
作为操作器节点的一部分的参数
图中作为独立节点的参数
作为操作器节点的一部分的参数:直觉,这种表征和经典的神经网络形式很像,但是有较低的灵活性和重复利用性。
图中作为独立节点的参数:灵活性和重复利用性很高。
Chainer 的例子
Chainer 最初使用的是经典的设计
后来被重新设计为两层的视角:一个是现代视角,一个是经典的视角。
这种多层的压缩,在现代的框架中很常见。(比如,Keras,PyTorch)
如何升级参数?
通过图以外的常规升级参数:容易部署,但是一致性很低。
把升级的方程式作为图的一部分进行表征:部署变得复杂,但是一致性高。
什么时候运行用户的代码?
什么时候运行用户的代码?
静态计算图:计算容易优化,灵活性和重复利用性低
动态计算图:计算很难优化,灵活性和重复利用性高
运行时间语言句法的灵活性和可用性
如何实现计算性能?
图迁移,以优化计算,
提供简单的方式来写定制的运行节点
如何扩展计算
多GPU平行计算
分布式计算
以下是BenchMark的比较:
我们主要介绍了每一个框架的能力
但是,并没有包括围绕框架的详细比较
框架的选择实际上依赖于写神经网络时的舒适度
在这里,试错很重要
















































































- 2017深度学习最新报告及8大主流深度学习框架超详细对比(内含PPT)
- 主流深度学习框架对比
- 主流深度学习框架对比
- 深度学习几大主流框架的对比
- TensorFlow与主流深度学习框架对比
- TensorFlow与主流深度学习框架对比
- 主流深度学习框架
- 系统学习深度学习(七)--主流深度学习开源框架对比
- 深度学习框架对比
- 深度学习框架对比
- 深度学习框架对比
- 主流开源深度学习框架对比分析
- 主流开源深度学习框架对比分析
- 深度学习主流框架Caffe
- 深度学习框架 横向对比
- [人工智能]主流深度学习框架和通用机器学习框架对比
- 系统学习深度学习(七)--主流深度学习开源框架对比 2017-01-23 11:05 2292人阅读 评论(0) 收藏 举报 分类: 深度学习(30) 目录(?)[+] 转自:http://b
- 斯坦福CS231n 2017最新课程:李飞飞详解深度学习的框架实现与对比
- ORM框架EF随笔记
- 翻译:Pong Game Tutorial
- 一种肯定能提高开发者编程能力的方法
- 杭电1241
- python hist的使用
- 2017深度学习最新报告及8大主流深度学习框架超详细对比(内含PPT)
- POJ 1185 炮兵布阵 (经典状压DP)
- 层次聚类
- 【笔记】RxJava2.0新特性简单介绍并实现RxBus
- Python判断语句
- POJ2718 解题报告
- 各类模板
- ionic2 页面跳转传参
- map hashMap


