Java集合源码学习(四)HashMap分析
来源:互联网 发布:js appendchild的用法 编辑:程序博客网 时间:2024/06/05 23:46
原文地址:https://yq.aliyun.com/articles/38410?spm=5176.8091938.0.0.01LA3v
摘要
ArrayList、LinkedList和HashMap的源码是一起看的,横向对比吧,感觉对这三种数据结构的理解加深了很多。 数据结构中有数组和链表来实现对数据的存储,这两者有不同的应用场景, 数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,插入和删除容易; 哈希表的实现结合了这两点,哈希表的实现方式有多种,在HashMap中使用的是链地址法,也就是拉链法。
数组、链表和哈希表结构
数据结构中有数组和链表来实现对数据的存储,这两者有不同的应用场景,
数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,插入和删除容易;
哈希表的实现结合了这两点,哈希表的实现方式有多种,在HashMap中使用的是链地址法,也就是拉链法。
看下面这张流传很广的图,

拉链法实际上是一种链表数组的结构,由数组加链表组成,在这个长度为16的数组中(HashMap默认初始化大小就是16),每个元素存储的是一个链表的头结点。
通过元素的key的hash值对数组长度取模,将这个元素插入到数组对应位置的链表中。
例如在图中,337%16=1,353%16=1,于是将其插入到数组位置1的链表头结点中。
关于HashMap
继承和实现
继承AbstractMap抽象类,Map的一些操作在AbstractMap里已经提供了默认实现,
实现Map接口,可以应用Map接口定义的一些操作,明确HashMap属于Map体系,
Cloneable接口,表明HashMap对象会重写java.lang.Object#clone()方法,HashMap实现的是浅拷贝(shallow copy),
Serializable接口,表明HashMap对象可以被序列化
内部数据结构
HashMap的实际数据存储在Entry类的数组中,
上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[]。
/** * 内部实际的存储数组,如果需要调整,容量必须是2的幂 */ transient Entry[] table;再来看一下Entry这个内部静态类,
static class Entry<K,V> implements Map.Entry<K,V> { final K key;//Key-value结构的key V value;//存储值 Entry<K,V> next;//指向下一个链表节点 final int hash;//哈希值 /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } ...... }线程安全
HashMap是非同步的,即线程不安全,在多线程条件下,可能出现很多问题,1. 多线程put后可能导致get死循环,具体表现为CPU使用率100%(put的时候transfer方法循环将旧数组中的链表移动到新数组)2. 多线程put的时候可能导致元素丢失(在addEntry方法的new Entry<K,V>(hash, key, value, e),如果两个线程都同时取得了e,则他们下一个元素都是e,然后赋值给table元素的时候有一个成功有一个丢失)需要线程安全的哈希表结构,可以考虑以下的方式:
- 使用Hashtable 类,Hashtable 是线程安全的;
- 使用并发包下的java.util.concurrent.ConcurrentHashMap,ConcurrentHashMap实现了更高级的线程安全;
- 或者使用synchronizedMap() 同步方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作.。
如:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) { return new SynchronizedMap<>(m); }常用方法
Map接口定义的方法
HashMap可以应用所有Map接口定义的方法:
public interface Map<K,V> { public static interface Entry<K,V> { //获取该Entry的key public abstract Object getKey(); //获取该Entry的value public abstract Object getValue(); //设置Entry的value public abstract Object setValue(Object obj); public abstract boolean equals(Object obj); public abstract int hashCode(); } //返回键值对的数目 int size(); //判断容器是否为空 boolean isEmpty(); //判断容器是否包含关键字key boolean containsKey(Object key); //判断容器是否包含值value boolean containsValue(Object value); //根据key获取value Object get(Object key); //向容器中加入新的key-value对 Object put(Object key, Object value); //根据key移除相应的键值对 Object remove(Object key); //将另一个Map中的所有键值对都添加进去 void putAll(Map<? extends K, ? extends V> m); //清除容器中的所有键值对 void clear(); //返回容器中所有的key组成的Set集合 Set keySet(); //返回所有的value组成的集合 Collection values(); //返回所有的键值对 Set<Map.Entry<K, V>> entrySet(); //继承自Object的方法 boolean equals(Object obj); int hashCode();}构造方法
HashMap使用Entry[] 数组存储数据,
另外维护了两个非常重要的变量:initialCapacity(初始容量)、loadFactor(加载因子)。
初始容量就是初始构造数组的大小,可以指定任何值,
但最后HashMap内部都会将其转成一个大于指定值的最小的2的幂,比如指定初始容量12,但最后会变成16,指定16,最后就是16。
加载因子是控制数组table的饱和度的,默认的加载因子是0.75,
DEFAULT_LOAD_FACTOR = 0.75f;也就是数组达到容量的75%,就会自动的扩容。
扩容每次*2
另外,HashMap的最大容量是2^30,
static final int MAXIMUM_CAPACITY = 1 << 30;
默认的初始化大小是16,
static final int DEFAULT_INITIAL_CAPACITY = 16;
HashMap提供了四种构造方法,可以使用默认的容量等进行初始化,
也可以显式制定大小和加载因子,还可以使用另外的map进行构造和初始化。
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR); table = new Entry[DEFAULT_INITIAL_CAPACITY]; init(); }public HashMap(Map<? extends K, ? extends V> m) { this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR); putAllForCreate(m); } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap(int initialCapacity, float loadFactor) { ...... }解决哈希冲突的办法
什么是哈希冲突
理论上哈希函数的输入域是无限的,优秀的哈希函数可以将冲突减少到最低,但是却不能避免,下面是一个典型的哈希冲突的例子:
解决哈希冲突的方法
常见的办法开放定址法,再哈希法,链地址法以及建立一个公共溢出区等,这里只考察链地址法。
链地址法就是最开始我们提到的链表-数组结构, 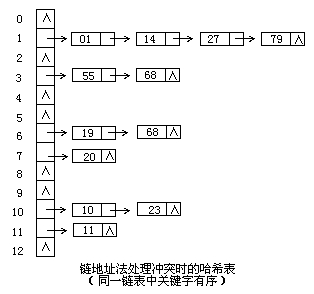
将所有关键字为同义词的记录存储在同一线性链表中。
源码分析
HashMap的存取实现
HashMap的存取主要是put和get操作的实现。
执行put方法时根据key的hash值来计算放到table数组的下标,
如果hash到相同的下标,则覆盖这个value,否则将新的对象put进去的元素放到Entry链的头部。
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return nullget操作的实现:
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) <br> { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }注意HashMap支持key=null的情况,看这个代码:
private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } ...... }哈希函数
下面看一下HashMap使用的哈希函数,源码来自JDK1.6:
/** * 哈希函数 * 看一下具体的操作,首先对h分别进行无符号右移20位和12位, * 然后对两个值进行按位异或,最后再与h进行按位异或, * 得到新的h后再进行一次同样的操作,分别右移7位和4位,具体的哈希函数优劣就不去研究了 * 这个方法可以尽量减少碰撞 */ static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。
当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一个新的table数组,将table数组的元素转移到新的table数组中。
/** * 再散列过程 * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically when the * number of keys in this map reaches its threshold. */ void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); } /** * 把当前Entry[]表的全部元素转移到新的table中 */ void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }- Java集合源码学习(四)HashMap分析
- 【Java集合学习系列】HashMap实现原理及源码分析
- java集合(4):HashMap源码分析(jdk1.8)
- java 中的集合(十二) HashMap源码分析
- Java集合2-HashMap详解(含源码分析)
- Java集合类之HashMap源码分析
- Java集合之HashMap源码实现分析
- java集合类源码分析一:HashMap
- 从源码分析java集合【HashMap】
- Java集合系列之HashMap源码分析
- Java集合之HashMap源码实现分析
- Java集合之HashMap源码分析
- Java集合源码分析→HashMap
- Java集合之HashMap源码分析
- 集合源码分析----HashMap
- JAVA集合源码分析系列:HashMap源码分析
- 【Java集合类源码分析】HashMap源码分析一
- 【Java集合类源码分析】HashMap源码分析二
- 数据结构 BFS层次遍历二叉树【C语言版本】
- 斯坦福大学机器学习课程线性回归编程作业二(多变量2)
- hibernate加载策略之lazy
- 剑指offer 二叉搜索树以及双向链表
- 1024. 科学计数法 (20)
- Java集合源码学习(四)HashMap分析
- 2016TID敏捷持续集成演讲材料——公开版
- C语言细节总结
- 冒泡排序(C实现)
- [leetcode]67. Add Binary@Java
- Linux配置虚礼机的网络和yum源
- Oracle 索引
- java中equals(),==与hashcode()的区别?
- Netty4启动ServerBootStrap源码分析


