Keras + TensorFlow
来源:互联网 发布:办公文件整理软件 编辑:程序博客网 时间:2024/05/22 02:28
Keras 是提供一些高可用的 Python API ,能帮助你快速的构建和训练自己的深度学习模型,它的后端是 TensorFlow 或者 Theano 。本文假设你已经熟悉了 TensorFlow 和卷积神经网络,如果,你还没有熟悉,那么可以先看看这个10分钟入门 TensorFlow 教程[http://cv-tricks.com/artificial- ... ensorflow-tutorial/]和卷积神经网络教程[http://cv-tricks.com/tensorflow- ... age-classification/],然后再回来阅读这个文章。
在这个教程中,我们将学习以下几个方面:
- 为什么选择 Keras?为什么 Keras 被认为是深度学习的未来?
- 在Ubuntu上面一步一步安装Keras。
- Keras TensorFlow教程:Keras基础知识。
- 了解 Keras 序列模型
4.1 实际例子讲解线性回归问题 - 使用 Keras 保存和回复预训练的模型
- Keras API
6.1 使用Keras API开发VGG卷积神经网络
6.2 使用Keras API构建并运行SqueezeNet卷积神经网络
1. 为什么选择Keras?
Keras 是 Google 的一位工程师 François Chollet [https://twitter.com/fchollet]开发的一个框架,可以帮助你在 Theano 上面进行快速原型开发。后来,这被扩展为 TensorFlow 也可以作为后端。并且最近,TensorFlow决定将其作为 contrib 文件中的一部分进行提供。
Keras 被认为是构建神经网络的未来,以下是一些它流行的原因:
- 轻量级和快速开发:Keras 的目的是在消除样板代码。几行 Keras 代码就能比原生的 TensorFlow 代码实现更多的功能。你也可以很轻松的实现 CNN 和 RNN,并且让它们运行在 CPU 或者 GPU 上面。
- 框架的“赢者”:Keras 是一个API,运行在别的深度学习框架上面。这个框架可以是 TensorFlow 或者 Theano。Microsoft 也计划让 CNTK 作为 Keras 的一个后端。目前,神经网络框架世界是非常分散的,并且发展非常快。具体,你可以看看 Karpathy 的这个推文:
想象一下,我们每年都要去学习一个新的框架,这是多么的痛苦。到目前为止,TensorFlow 似乎成为了一种潮流,并且越来越多的框架开始为 Keras 提供支持,它可能会成为一种标准。
目前,Keras 是成长最快的一种深度学习框架。因为可以使用不同的深度学习框架作为后端,这也使得它成为了流行的一个很大的原因。你可以设想这样一个场景,如果你阅读到了一篇很有趣的论文,并且你想在你自己的数据集上面测试这个模型。让我们再次假设,你对TensorFlow 非常熟悉,但是对Theano了解的非常少。那么,你必须使用TensorFlow 对这个论文进行复现,但是这个周期是非常长的。但是,如果现在代码是采用Keras写的,那么你只要将后端修改为TensorFlow就可以使用代码了。这将是对社区发展的一个巨大的推动作用。
2. 怎么安装Keras,并且把TensorFlow作为后端
a) 依赖安装
安装 h5py,用于模型的保存和载入:
[Python] 纯文本查看 复制代码
1
pip install h5py还有一些依赖包也要安装。
[Python] 纯文本查看 复制代码
1
2
pip install numpy scipypip install pillow如果你还没有安装TensorFlow,那么你可以按照这个教程[http://cv-tricks.com/artificial- ... 4-04-aws-p2-xlarge/]先去安装TensorFlow。一旦,你安装完成了 TensorFlow,你只需要使用 pip 很容易的安装 Keras。
[Python] 纯文本查看 复制代码
1
sudo pip install keras使用以下命令来查看 Keras 版本。
[Python] 纯文本查看 复制代码
1
2
>>> importkerasUsing TensorFlow backend.>>> keras.__version__'2.0.4'一旦,Keras 被安装完成,你需要去修改后端文件,也就是去确定,你需要 TensorFlow 作为后端,还是 Theano 作为后端,修改的配置文件位于~/.keras/keras.json 。具体配置如下:
[Python] 纯文本查看 复制代码
1
2
3
4
5
6
{ "floatx":"float32", "epsilon":1e-07, "backend":"tensorflow", "image_data_format":"channels_last"}请注意,参数 image_data_format 是 channels_last ,也就是说这个后端是 TensorFlow。因为,在TensorFlow中图像的存储方式是[height, width, channels],但是在Theano中是完全不同的,也就是[channels, height, width]。因此,如果你没有正确的设置这个参数,那么你模型的中间结果将是非常奇怪的。对于Theano来说,这个参数就是channels_first。
那么,至此你已经准备好了,使用Keras来构建模型,并且把TensorFlow作为后端。
3. Keras基础知识
在Keras中主要的数据结构是 model ,该结构定义了一个完整的图。你可以向已经存在的图中加入任何的网络结构。
[Python] 纯文本查看 复制代码
1
import kerasKeras 有两种不同的建模方式:
- Sequential models:这种方法用于实现一些简单的模型。你只需要向一些存在的模型中添加层就行了。
- Functional API:Keras的API是非常强大的,你可以利用这些API来构造更加复杂的模型,比如多输出模型,有向无环图等等。
在本文的下一节中,我们将学习Keras的Sequential models 和 Functional API的理论和实例。
在这一部分中,我将来介绍Keras Sequential models的理论。我将快速的解释它是如何工作的,还会利用具体代码来解释。之后,我们将解决一个简单的线性回归问题,你可以在阅读的同时运行代码,来加深印象。
以下代码是如何开始导入和构建序列模型。
[Python] 纯文本查看 复制代码
1
2
from keras.models import Sequentialmodels =Sequential()接下来我们可以向模型中添加 Dense(full connected layer),Activation,Conv2D,MaxPooling2D函数。
[Python] 纯文本查看 复制代码
1
2
3
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten, Dropoutmodel.add(Conv2D(64, (3,3), activation='relu', input_shape= (100,100,32)))# This ads a Convolutional layer with 64 filters of size 3 * 3 to the graph以下是如何将一些最流行的图层添加到网络中。我已经在卷积神经网络教程[http://cv-tricks.com/tensorflow- ... age-classification/]中写了很多关于图层的描述。
1. 卷积层
这里我们使用一个卷积层,64个卷积核,维度是33的,之后采用 relu 激活函数进行激活,输入数据的维度是 `100100*32`。注意,如果是第一个卷积层,那么必须加上输入数据的维度,后面几个这个参数可以省略。
[Python] 纯文本查看 复制代码
1
model.add(Conv2D(64, (3,3), activation='relu', input_shape= (100,100,32)))2. MaxPooling 层
指定图层的类型,并且指定赤的大小,然后自动完成赤化操作,酷毙了!
[Python] 纯文本查看 复制代码
1
model.add(MaxPooling2D(pool_size=(2,2)))3. 全连接层
这个层在 Keras 中称为被称之为 Dense 层,我们只需要设置输出层的维度,然后Keras就会帮助我们自动完成了。
[Python] 纯文本查看 复制代码
1
model.add(Dense(256, activation='relu'))4. Dropout
[Python] 纯文本查看 复制代码
1
model.add(Dropout(0.5))5. 扁平层
model.add(Flatten())
4. 数据输入
网络的第一层需要读入训练数据。因此我们需要去制定输入数据的维度。因此,input_shape 参数被用于制定输入数据的维度大小。
[Python] 纯文本查看 复制代码
1
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(224,224, 3)))在这个例子中,数据输入的第一层是一个卷积层,输入数据的大小是 224*224*3 。
以上操作就帮助你利用序列模型构建了一个模型。接下来,让我们学习最重要的一个部分。一旦你指定了一个网络架构,你还需要指定优化器和损失函数。我们在Keras中使用compile函数来达到这个功能。比如,在下面的代码中,我们使用rmsprop 来作为优化器,binary_crossentropy 来作为损失函数值。
[Python] 纯文本查看 复制代码
1
model.compile(loss='binary_crossentropy', optimizer='rmsprop')如果你想要使用随机梯度下降,那么你需要选择合适的初始值和超参数:
[Python] 纯文本查看 复制代码
1
2
3
from keras.optimizers import SGDsgd =SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)model.compile(loss='categorical_crossentropy', optimizer=sgd)现在,我们已经构建完了模型。接下来,让我们向模型中输入数据,在Keras中是通过 fit 函数来实现的。你也可以在该函数中指定batch_size 和 epochs 来训练。
[Python] 纯文本查看 复制代码
1
model.fit(x_train, y_train, batch_size= 32, epochs= 10, validation_data(x_val, y_val))最后,我们使用 evaluate 函数来测试模型的性能。
[Python] 纯文本查看 复制代码
1
score =model.evaluate(x_test, y_test, batch_size =32)这些就是使用序列模型在Keras中构建神经网络的具体操作步骤。现在,我们来构建一个简单的线性回归模型。
问题陈述
在线性回归问题中,你可以得到很多的数据点,然后你需要使用一条直线去拟合这些离散点。在这个例子中,我们创建了100个离散点,然后用一条直线去拟合它们。
a) 创建训练数据
TrainX 的数据范围是 -1 到 1,TrainY 与 TrainX 的关系是3倍,并且我们加入了一些噪声点。
[Python] 纯文本查看 复制代码
1
2
3
4
5
6
7
import kerasfrom keras.models import Sequentialfrom keras.layers import Denseimport numpy as nptrX =np.linspace(-1,1, 101)trY =3 * trX + np.random.randn(*trX.shape)* 0.33b) 构建模型
首先我们需要构建一个序列模型。我们需要的只是一个简单的链接,因此我们只需要使用一个 Dense 层就够了,然后用线性函数进行激活。
[Python] 纯文本查看 复制代码
1
2
model =Sequential()model.add(Dense(input_dim=1, output_dim=1, init='uniform', activation='linear'))下面的代码将设置输入数据 x,权重 w 和偏置项 b。然我们来看看具体的初始化工作。如下:
[Python] 纯文本查看 复制代码
1
2
3
4
5
weights =model.layers[0].get_weights()w_init =weights[0][0][0]b_init =weights[1][0]print('Linear regression model is initialized with weights w: %.2f, b: %.2f'% (w_init, b_init))## Linear regression model is initialized with weight w: -0.03, b: 0.00现在,我们可以l利用自己构造的数据 trX 和 trY 来训练这个线性模型,其中 trY 是 trX 的3倍。因此,权重 w 的值应该是 3。
我们使用简单的梯度下降来作为优化器,均方误差(MSE)作为损失值。如下:
[Python] 纯文本查看 复制代码
1
model.compile(optimizer='sgd', loss='mse')最后,我们使用 fit 函数来输入数据。
[Python] 纯文本查看 复制代码
1
model.fit(trX, trY, nb_epoch=200, verbose=1)在经过训练之后,我们再次打印权重:
[Python] 纯文本查看 复制代码
1
2
3
4
5
6
weights =model.layers[0].get_weights()w_final =weights[0][0][0]b_final =weights[1][0]print('Linear regression model is trained to have weight w: %.2f, b: %.2f'% (w_final, b_final))##Linear regression model is trained to have weight w: 2.94, b: 0.08正如你所看到的,在运行 200 轮之后,现在权重非常接近于 3。你可以将运行的轮数修改为区间 [100, 300] 之间,然后观察输出结构有什么变化。现在,你已经学会了利用很少的代码来构建一个线性回归模型,如果要构建一个相同的模型,在 TensorFlow 中需要用到更多的代码。
5. 使用 Keras 保存和回复预训练的模型
HDF5 二进制格式
一旦你利用Keras完成了训练,你可以将你的网络保存在HDF5里面。当然,你需要先安装 h5py。HDF5 格式非常适合存储大量的数字收,并从 numpy 处理这些数据。比如,我们可以轻松的将存储在磁盘上的多TB数据集进行切片,就好像他们是真正的 numpy 数组一样。你还可以将多个数据集存储在单个文件中,遍历他们或者查看.shape 和 .dtype 属性。
如果你需要信心,那么告诉你,NASA也在使用 HDF5 进行数据存储。h5py 是python对HDF5 C API 的封装。几乎你可以用C在HDF5上面进行的任何操作都可以用python在h5py上面操作。
保存权重
如果你要保存训练好的权重,那么你可以直接使用 save_weights 函数。
[Python] 纯文本查看 复制代码
1
model.save_weights("my_model.h5")载入预训练权重
如果你想要载入以前训练好的模型,那么你可以使用 load_weights 函数。
[Python] 纯文本查看 复制代码
1
model.load_weights('my_model_weights.h5')6. Keras API
如果对于简单的模型和问题,那么序列模型是非常好的方式。但是如果你要构建一个现实世界中复杂的网络,那么你就需要知道一些功能性的API,在很多流行的神经网络中,我们都有一个最小的网络结构,完整的模型是根据这些最小的模型进行叠加完成的。这些基础的API可以让你一层一层的构建模型。因此,你只需要很少的代码就可以来构建一个完整的复杂神经网络。
让我们来看看它是如何工作的。首先,你需要导入一些包。
[Python] 纯文本查看 复制代码
1
from keras.models import Model现在,你需要去指定输入数据,而不是在顺序模型中,在最后的 fit 函数中输入数据。这是序列模型和这些功能性的API之间最显著的区别之一。我们使用input() 函数来申明一个 1*28*28 的张量。
[Python] 纯文本查看 复制代码
1
2
3
4
from keras.layers import Input## First, define the vision modulesdigit_input = Input(shape=(1,28, 28))现在,让我们来利用API设计一个卷积层,我们需要指定要在在哪个层使用卷积网络,具体代码这样操作:
[Python] 纯文本查看 复制代码
1
2
3
4
x =Conv2D(64, (3,3))(digit_input)x =Conv2D(64, (3,3))(x)x =MaxPooling2D((2,2))(x)out =Flatten()(x)最后,我们对于指定的输入和输出数据来构建一个模型。
[Python] 纯文本查看 复制代码
1
vision_model = Model(digit_input, out)当然,我们还需要指定损失函数,优化器等等。但这些和我们在序列模型中的操作一样,你可以使用 fit 函数和compile 函数来进行操作。
接下来,让我们来构建一个vgg-16模型,这是一个很大很“老”的模型,但是由于它的简洁性,它是一个很好的学习模型。
6.1 使用Keras API开发VGG卷积神经网络
VGG:
VGG卷积神经网络是牛津大学在2014年提出来的模型。当这个模型被提出时,由于它的简洁性和实用性,马上成为了当时最流行的卷积神经网络模型。它在图像分类和目标检测任务中都表现出非常好的结果。在2014年的ILSVRC比赛中,VGG 在Top-5中取得了92.3%的正确率。 该模型有一些变种,其中最受欢迎的当然是 vgg-16,这是一个拥有16层的模型。你可以看到它需要维度是 224*224*3 的输入数据。
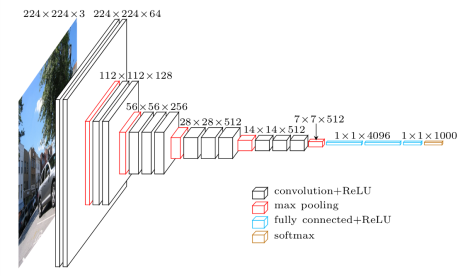
Vgg 16 architecture
让我们来写一个独立的函数来完整实现这个模型。
[Python] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
img_input = Input(shape=input_shape)# Block 1x =Conv2D(64, (3,3), activation='relu', padding='same', name='block1_conv1')(img_input)x =Conv2D(64, (3,3), activation='relu', padding='same', name='block1_conv2')(x)x =MaxPooling2D((2,2), strides=(2,2), name='block1_pool')(x)# Block 2x =Conv2D(128, (3,3), activation='relu', padding='same', name='block2_conv1')(x)x =Conv2D(128, (3,3), activation='relu', padding='same', name='block2_conv2')(x)x =MaxPooling2D((2,2), strides=(2,2), name='block2_pool')(x)# Block 3x =Conv2D(256, (3,3), activation='relu', padding='same', name='block3_conv1')(x)x =Conv2D(256, (3,3), activation='relu', padding='same', name='block3_conv2')(x)x =Conv2D(256, (3,3), activation='relu', padding='same', name='block3_conv3')(x)x =MaxPooling2D((2,2), strides=(2,2), name='block3_pool')(x)# Block 4x =Conv2D(512, (3,3), activation='relu', padding='same', name='block4_conv1')(x)x =Conv2D(512, (3,3), activation='relu', padding='same', name='block4_conv2')(x)x =Conv2D(512, (3,3), activation='relu', padding='same', name='block4_conv3')(x)x =MaxPooling2D((2,2), strides=(2,2), name='block4_pool')(x)# Block 5x =Conv2D(512, (3,3), activation='relu', padding='same', name='block5_conv1')(x)x =Conv2D(512, (3,3), activation='relu', padding='same', name='block5_conv2')(x)x =Conv2D(512, (3,3), activation='relu', padding='same', name='block5_conv3')(x)x =MaxPooling2D((2,2), strides=(2,2), name='block5_pool')(x)x =Flatten(name='flatten')(x)x =Dense(4096, activation='relu', name='fc1')(x)x =Dense(4096, activation='relu', name='fc2')(x)x =Dense(classes, activation='softmax', name='predictions')(x)我们可以将这个完整的模型,命名为 vgg16.py。
在这个例子中,我们来运行 imageNet 数据集中的某一些数据来进行测试。具体代码如下:
[Python] 纯文本查看 复制代码
1
2
3
4
5
6
7
8
9
model =applications.VGG16(weights='imagenet')img =image.load_img('cat.jpeg', target_size=(224,224))x =image.img_to_array(img)x =np.expand_dims(x, axis=0)x =preprocess_input(x)preds =model.predict(x)for results in decode_predictions(preds): forresult in results: print('Probability %0.2f%% => [%s]'% (100*result[2], result[1]))
正如你在图中看到的,模型会对图片中的物体进行一个识别预测。
我们通过API构建了一个VGG模型,但是由于VGG是一个很简单的模型,所以并没有完全将API的能力开发出来。接下来,我们通过构建一个 SqueezeNet模型,来展示API的真正能力。
6.2 使用Keras API构建并运行SqueezeNet卷积神经网络
SequeezeNet 是一个非常了不起的网络架构,它的显著点不在于对正确性有多少的提高,而是减少了计算量。当SequeezeNet的正确性和AlexNet接近时,但是ImageNet上面的预训练模型的存储量小于5 MB,这对于在现实世界中使用CNN是非常有利的。SqueezeNet模型引入了一个 Fire模型,它由交替的 Squeeze 和 Expand 模块组成。
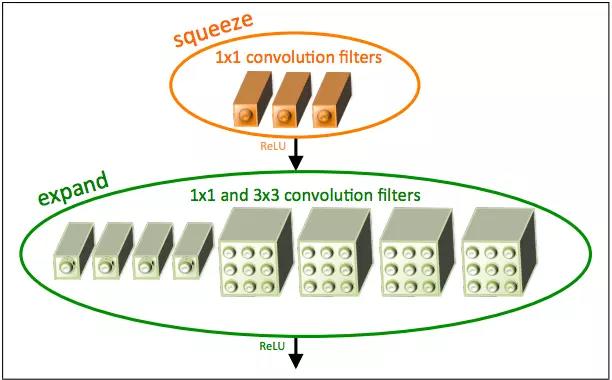
SqueezeNet fire module
现在,我们对 fire 模型进行多次复制,从而来构建完整的网络模型,具体如下:
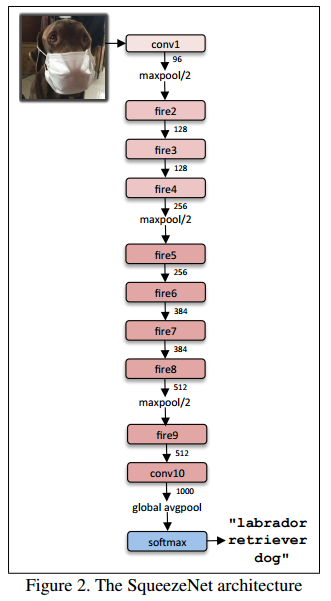
为了去构建这个网络,我们将利用API的功能首先来构建一个单独的 fire 模块。
[Python] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
# Squeeze part of fire module with 1 * 1 convolutions, followed by Relux =Convolution2D(squeeze, (1,1), padding='valid', name='fire2/squeeze1x1')(x)x =Activation('relu', name='fire2/relu_squeeze1x1')(x)#Expand part has two portions, left uses 1 * 1 convolutions and is called expand1x1left =Convolution2D(expand, (1,1), padding='valid', name='fire2/expand1x1')(x)left =Activation('relu', name='fire2/relu_expand1x1')(left)#Right part uses 3 * 3 convolutions and is called expand3x3, both of these are follow#ed by Relu layer, Note that both receive x as input as designed.right =Convolution2D(expand, (3,3), padding='same', name='fire2/expand3x3')(x)right =Activation('relu', name='fire2/relu_expand3x3')(right)# Final output of Fire Module is concatenation of left and right.x =concatenate([left, right], axis=3, name='fire2/concat')[Python] 纯文本查看 复制代码
1
2
3
4
5
sq1x1 ="squeeze1x1"exp1x1 ="expand1x1"exp3x3 ="expand3x3"relu ="relu_"WEIGHTS_PATH = "https://github.com/rcmalli/keras-squeezenet/releases/download/v1.0/squeezenet_weights_tf_dim_ordering_tf_kernels.h5"模块化处理
[Python] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
sq1x1 ="squeeze1x1"exp1x1 ="expand1x1"exp3x3 ="expand3x3"relu ="relu_"def fire_module(x, fire_id, squeeze=16, expand=64): s_id= 'fire'+ str(fire_id)+ '/' x= Convolution2D(squeeze, (1,1), padding='valid', name=s_id+ sq1x1)(x) x= Activation('relu', name=s_id+ relu + sq1x1)(x) left= Convolution2D(expand, (1,1), padding='valid', name=s_id+ exp1x1)(x) left= Activation('relu', name=s_id+ relu + exp1x1)(left) right= Convolution2D(expand, (3,3), padding='same', name=s_id+ exp3x3)(x) right= Activation('relu', name=s_id+ relu + exp3x3)(right) x= concatenate([left, right], axis=3, name=s_id+ 'concat')returnx现在,我们可以利用我们构建好的单独的 fire 模块,来构建完整的模型。
[Python] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
x =Convolution2D(64, (3,3), strides=(2,2), padding='valid', name='conv1')(img_input)x =Activation('relu', name='relu_conv1')(x)x =MaxPooling2D(pool_size=(3,3), strides=(2,2), name='pool1')(x)x =fire_module(x, fire_id=2, squeeze=16, expand=64)x =fire_module(x, fire_id=3, squeeze=16, expand=64)x =MaxPooling2D(pool_size=(3,3), strides=(2,2), name='pool3')(x)x =fire_module(x, fire_id=4, squeeze=32, expand=128)x =fire_module(x, fire_id=5, squeeze=32, expand=128)x =MaxPooling2D(pool_size=(3,3), strides=(2,2), name='pool5')(x)x =fire_module(x, fire_id=6, squeeze=48, expand=192)x =fire_module(x, fire_id=7, squeeze=48, expand=192)x =fire_module(x, fire_id=8, squeeze=64, expand=256)x =fire_module(x, fire_id=9, squeeze=64, expand=256)x =Dropout(0.5, name='drop9')(x)x =Convolution2D(classes, (1,1), padding='valid', name='conv10')(x)x =Activation('relu', name='relu_conv10')(x)x =GlobalAveragePooling2D()(x)out =Activation('softmax', name='loss')(x)model =Model(inputs, out, name='squeezenet')完整的网络模型我们放置在 squeezenet.py 文件里。我们应该先下载 imageNet 预训练模型,然后在我们自己的数据集上面进行训练和测试。下面的代码就是实现了这个功能:
[Python] 纯文本查看 复制代码
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
import numpy as npfrom keras_squeezenet import SqueezeNetfrom keras.applications.imagenet_utils importpreprocess_input, decode_predictionsfrom keras.preprocessing import imagemodel =SqueezeNet()img =image.load_img('pexels-photo-280207.jpeg', target_size=(227,227))x =image.img_to_array(img)x =np.expand_dims(x, axis=0)x =preprocess_input(x)preds =model.predict(x)all_results = decode_predictions(preds)for results in all_results: forresult in results: print('Probability %0.2f%% => [%s]'% (100*result[2], result[1]))对于相同的一幅图预测,我们可以得到如下的预测概率。

至此,我们的Keras TensorFlow教程就结束了。希望可以帮到你 :-)
阅读全文
0 0
- Keras + TensorFlow
- Keras使用tensorflow代码
- tensorflow theano keras介绍
- kaggle mnist tensorflow+keras
- Keras——Tensorflow
- python tensorflow keras
- ubuntu install tensorflow keras
- keras tensorflow 代码
- tensorflow & keras fine tune
- 安装TensorFlow和keras
- TensorFlow, Keras, TensorLayer, Tflearn 比较
- Anaconda+Tensorflow+Theano+Keras安装
- Keras Tensorflow TF_NewStatus错误修改
- windows安装tensorflow和keras
- ubuntu上安装keras + tensorflow
- vgg16 on keras for tensorflow
- Linux+Anaconda+ tensorflow + keras 安装
- tensorflow75 Keras on Tensorflow 入门
- 01--类型
- ssh用法及命令
- C++之对象包含与成员函数不兼容的类型限定符---补充(5)《Effective C++》
- Linux下深度解析history命令来显示曾执行过的命令
- html5 video 元素
- Keras + TensorFlow
- 数位dp hdu2089 ,4734,bzoj 1026
- 博客分类暗语
- 理解mysql_如何优雅的设计表结构
- 《Python自然语言处理》学习笔记-第一章
- ionic中ion-multi-picker报错Cannot find module 'ion-multi-picker'.以及ion-multi-picker用法
- H5游戏的日渐壮大
- STM32之GPIO的8种配置模式
- 文件权限的修改


