Hadoop 学习自定义数据类型
来源:互联网 发布:php兄弟连官网 编辑:程序博客网 时间:2024/05/22 00:22
序列化在分布式环境的两大作用:进程间通信,永久存储。 




Writable接口, 是根据 DataInput 和 DataOutput 实现的简单、有效的序列化对象.
MR的任意Value必须实现Writable接口:
MR的key必须实现WritableComparable接口,WritableComparable继承自Writable和Comparable接口:
(本节先讲自定义value值,下一节再讲自定义key值,根据key值进行自定义排序)
以一个例子说明,自定义数据类型(例子来源于学习的课程):
原始数据是由若干条下面数据组成:
数据格式及字段顺序如下:
现在要做的工作是以“手机号码”为关键字,计算同一个号码的upPackNum, downPackNum,upPayLoad,downPayLoad四个累加值。
运用MapReduce解决问题思路:
1、框架将数据分成<k1,v1>,k1是位置标记,v1表示一行数据;
2、map函数输入<k1,v1>,输入<k2,v2>,k2是选定数据的第1列(从0开始),v2是自定义的数据类型,包含第六、七、八、九列封装后的数据;
3、框架将<k2,v2>依据k2关键字进行map排序,然后进行combine过程,再进行Reduce段排序,得到<k2,list(v2...)>;
4、reduce函数处理<k2,list(v2...)>,以k2为关键字,计算list的内容。
要自定义的数据类型是Value值,因此要继承Writable接口,自定义数据类型如下:
import java.io.DataInput;import java.io.DataOutput;import java.io.IOException; import org.apache.hadoop.io.Writable; public class TrafficWritable implements Writable { long upPackNum, downPackNum,upPayLoad,downPayLoad; public TrafficWritable() { //这个构造函数不能省,否则报错 super(); // TODO Auto-generated constructor stub } public TrafficWritable(String upPackNum, String downPackNum, String upPayLoad, String downPayLoad) { super(); this.upPackNum = Long.parseLong(upPackNum); this.downPackNum = Long.parseLong(downPackNum); this.upPayLoad = Long.parseLong(upPayLoad); this.downPayLoad = Long.parseLong(downPayLoad); } @Override public void write(DataOutput out) throws IOException { //序列化 // TODO Auto-generated method stub out.writeLong(upPackNum); out.writeLong(downPackNum); out.writeLong(upPayLoad); out.writeLong(downPayLoad); } @Override public void readFields(DataInput in) throws IOException { //反序列化 // TODO Auto-generated method stub this.upPackNum=in.readLong(); this.downPackNum=in.readLong(); this.upPayLoad=in.readLong(); this.downPayLoad=in.readLong(); } @Override public String toString() { //不加toStirng函数,最后输出内存的地址 return upPackNum + "\t"+ downPackNum + "\t" + upPayLoad + "\t" + downPayLoad; } }最后实现map函数和Reduce函数如下,基本框架和wordCount相同:
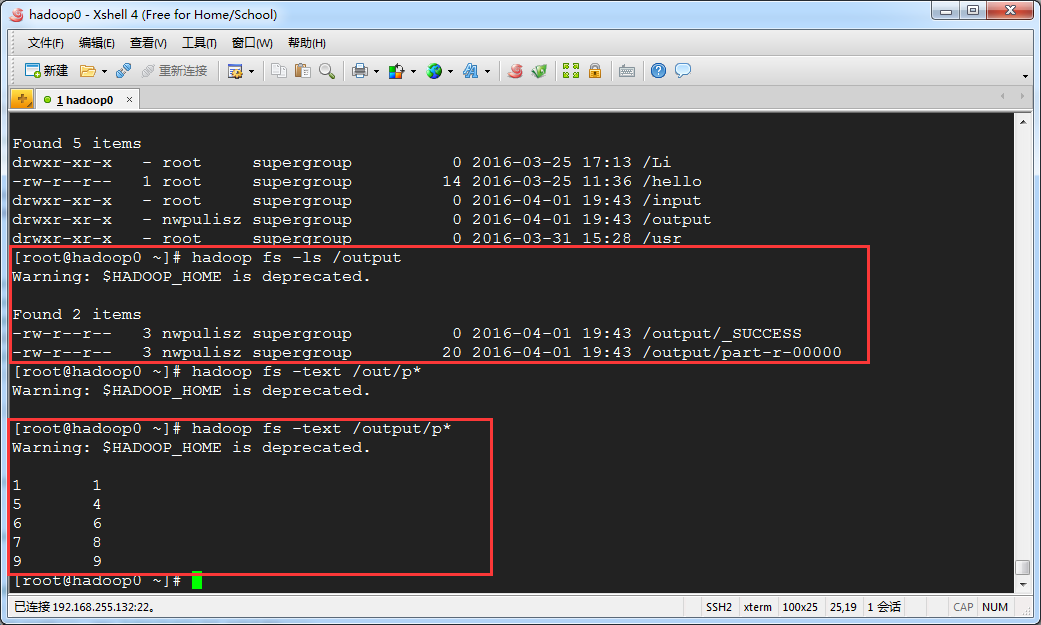
import java.io.IOException;import java.net.URI; import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TrafficCount { /** * @author nwpulisz * @date 2016.3.31 */ static final String INPUT_PATH="hdfs://192.168.255.132:9000/input"; static final String OUTPUT_PATH="hdfs://192.168.255.132:9000/output"; public static void main(String[] args) throws Throwable { // TODO Auto-generated method stub Configuration conf = new Configuration(); Path outPut_path= new Path(OUTPUT_PATH); Job job = new Job(conf, "TrafficCount"); //如果输出路径是存在的,则提前删除输出路径 FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf); if(fileSystem.exists(outPut_path)) { fileSystem.delete(outPut_path,true); } FileInputFormat.setInputPaths(job, INPUT_PATH); FileOutputFormat.setOutputPath(job, outPut_path); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(TrafficWritable.class); job.waitForCompletion(true); } static class MyMapper extends Mapper<LongWritable, Text, Text, TrafficWritable>{ protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { String[] splits = v1.toString().split("\t"); Text k2 = new Text(splits[1]); TrafficWritable v2 = new TrafficWritable(splits[6], splits[7], splits[8], splits[9]); context.write(k2, v2); } } static class MyReducer extends Reducer<Text, TrafficWritable, Text, TrafficWritable>{ protected void reduce(Text k2, Iterable<TrafficWritable> v2s, Context context ) throws IOException, InterruptedException { long upPackNum=0L, downPackNum=0L,upPayLoad=0L,downPayLoad=0L; for(TrafficWritable traffic: v2s) { upPackNum += traffic.upPackNum; downPackNum += traffic.downPackNum; upPayLoad += traffic.upPayLoad; downPayLoad += traffic.downPayLoad; } context.write(k2,new TrafficWritable(upPackNum+"",downPackNum+"",upPayLoad+"", downPayLoad+"")); } }}最终输出结果如下:
2
自定义排序,是基于k2的排序,设现有以下一组数据,分别表示矩形的长和宽,先按照面积的升序进行排序。
1
2
3
4
5
9 96 67 81 15 4
现在需要重新定义数据类型,MR的key值必须继承WritableComparable接口,因此定义RectangleWritable数据类型如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class RectangleWritable implementsWritableComparable { intlength,width; publicRectangleWritable() { super(); // TODO Auto-generated constructor stub } publicRectangleWritable(intlength, int width) { super(); this.length = length; this.width = width; } publicint getLength() { returnlength; } publicvoid setLength(intlength) { this.length = length; } publicint getWidth() { returnwidth; } publicvoid setWidth(intwidth) { this.width = width; } @Override publicvoid write(DataOutput out)throws IOException { // TODO Auto-generated method stub out.writeInt(length); out.writeInt(width); } @Override publicvoid readFields(DataInput in)throws IOException { // TODO Auto-generated method stub this.length=in.readInt(); this.width=in.readInt(); } @Override publicint compareTo(Object arg0) { // TODO Auto-generated method stub RectangleWritable other = (RectangleWritable)arg0; if(this.getLength() *this.getWidth() > other.length * other.width ) { return1; } if(this.getLength() *this.getWidth() < other.length * other.width ) { return-1; } return0; } @Override publicString toString() { return this.getLength() + "\t" + this.getWidth(); } }
其中,compareTo方法自定义排序规则,然后由框架进行排序。
map函数和Reduce函数并无大变化,还是按照WrodCount的思路进行,具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import java.io.IOException;import java.net.URI;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.Reducer;public class SelfDefineSort { /** * @param args * @author nwpulisz * @date 2016.4.1 */ staticfinal String INPUT_PATH="hdfs://192.168.255.132:9000/input"; staticfinal String OUTPUT_PATH="hdfs://192.168.255.132:9000/output"; publicstatic void main(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf =new Configuration(); Path outPut_path=new Path(OUTPUT_PATH); Job job =new Job(conf, "SelfDefineSort"); //如果输出路径是存在的,则提前删除输出路径 FileSystem fileSystem = FileSystem.get(newURI(OUTPUT_PATH), conf); if(fileSystem.exists(outPut_path)) { fileSystem.delete(outPut_path,true); } job.setJarByClass(RectangleWritable.class); FileInputFormat.setInputPaths(job, INPUT_PATH); FileOutputFormat.setOutputPath(job, outPut_path); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setMapOutputKeyClass(RectangleWritable.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); job.waitForCompletion(true); } staticclass MyMapper extends Mapper<LongWritable, Text, RectangleWritable, NullWritable>{ protectedvoid map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException { String[] splits = v1.toString().split("\t"); RectangleWritable k2 =new RectangleWritable(Integer.parseInt(splits[0]), Integer.parseInt(splits[1])); context.write(k2,NullWritable.get()); } } staticclass MyReducer extends Reducer<RectangleWritable, NullWritable, IntWritable, IntWritable>{ protectedvoid reduce(RectangleWritable k2, Iterable<NullWritable> v2s, Context context) throwsIOException, InterruptedException { // TODO Auto-generated method stub context.write(newIntWritable(k2.getLength()), newIntWritable(k2.getWidth())); } }}
根据自定义结果,输出结果如下:
阅读全文
0 0
- Hadoop 学习自定义数据类型
- Hadoop学习笔记(八)---内置数据类型与自定义数据类型
- hadoop自定义数据类型
- hadoop自定义数据类型
- 【转】自定义Hadoop数据类型
- hadoop 自定义数据类型
- hadoop自定义数据类型
- hadoop自定义数据类型
- hadoop-自定义数据类型
- Hadoop自定义数据类型
- Hadoop自定义数据类型
- Hadoop 自定义数据类型
- hadoop自定义数据类型
- hadoop自定义数据类型
- Hadoop自定义数据类型编程练习
- Hadoop 1.x自定义数据类型
- Hadoop 自定义数据类型和自定义排序
- Hadoop自定义数据类型和输入格式
- hdu2326 枚举高度差和两两高度之间的组合出来的差
- 给初学者的weex教程(一)
- LightOJ_1282 Leading and Trailing 快速幂
- C语言:递归
- HDU 1863 畅通工程(最小生成树-Kruskal)
- Hadoop 学习自定义数据类型
- freemarker 和JSP 的区别
- OAuth2 logout
- javascript笔记
- 触摸物体的旋转 移动 缩放功能
- this关键字static关键字
- 1024.科学计数法 (20)
- 解决WebStrom、PhpStorm等JetBrains软件最新版(2017.2)的中文打字法不兼容问题
- SDUT-山峰---栈的单步调用


