java快速排序专栏
来源:互联网 发布:win7摄像头软件ecap 编辑:程序博客网 时间:2024/06/05 04:19
快速排序
像合并排序一样,QuickSort是一个分割和征服算法。它选择一个元素作为枢轴,并将给定的数组围绕拾取的枢轴分隔。 quickSort有许多不同的版本,以不同的方式选择枢纽。
- 始终选择第一个元素作为枢轴。
- 始终选择最后一个元素作为枢轴(实现如下)
- 选择随机元素作为枢轴。
- 选择中位数作为枢轴。
quickSort的关键过程是partition()。目标分区是给定一个数组和数组的元素x作为枢轴,将x放在排序数组中的正确位置,并将所有较小的元素(小于x)放在x之前,并将所有更大的元素(大于x)放在X。所有这一切都应该在线性时间完成。
递归QuickSort函数的伪代码:
像合并排序一样,QuickSort是一个分割和征服算法。它选择一个元素作为枢轴,并将给定的数组围绕拾取的枢轴分隔。 quickSort有许多不同的版本,以不同的方式选择枢纽。
- 始终选择第一个元素作为枢轴。
- 始终选择最后一个元素作为枢轴(实现如下)
- 选择随机元素作为枢轴。
- 选择中位数作为枢轴。
quickSort的关键过程是partition()。目标分区是给定一个数组和数组的元素x作为枢轴,将x放在排序数组中的正确位置,并将所有较小的元素(小于x)放在x之前,并将所有更大的元素(大于x)放在X。所有这一切都应该在线性时间完成。
递归QuickSort函数的伪代码:
/* low --> Starting index, high --> Ending index */quickSort(arr[], low, high){ if (low < high) { /* pi is partitioning index, arr[p] is now at right place */ pi = partition(arr, low, high); quickSort(arr, low, pi - 1); // Before pi quickSort(arr, pi + 1, high); // After pi }}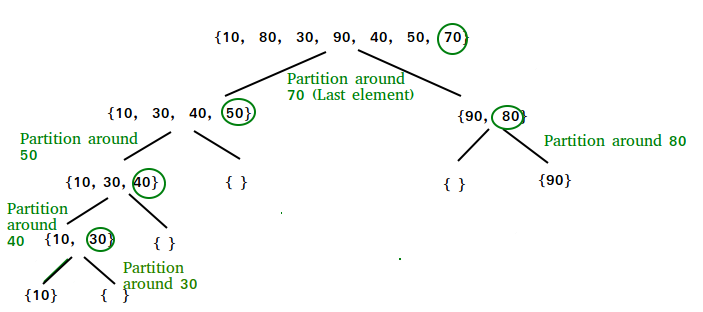
分区算法
可以有很多方法来做分区,伪代码采用CLRS书中给出的方法。逻辑很简单,我们从最左边的元素开始,并跟踪较小(或等于)元素的索引。当遍历时,如果我们找到一个较小的元素,我们用arr [i]交换当前元素。否则我们忽略当前元素。/* low --> Starting index, high --> Ending index */quickSort(arr[], low, high){ if (low < high) { /* pi is partitioning index, arr[p] is now at right place */ pi = partition(arr, low, high); quickSort(arr, low, pi - 1); // Before pi quickSort(arr, pi + 1, high); // After pi }}partition()的伪代码
/* This function takes last element as pivot, places the pivot element at its correct position in sorted array, and places all smaller (smaller than pivot) to left of pivot and all greater elements to right of pivot */partition (arr[], low, high){ // pivot (Element to be placed at right position) pivot = arr[high]; i = (low - 1) // Index of smaller element for (j = low; j <= high- 1; j++) { // If current element is smaller than or // equal to pivot if (arr[j] <= pivot) { i++; // increment index of smaller element swap arr[i] and arr[j] } } swap arr[i + 1] and arr[high]) return (i + 1)}partition() 的插图:
arr[] = {10, 80, 30, 90, 40, 50, 70}Indexes: 0 1 2 3 4 5 6 low = 0, high = 6, pivot = arr[h] = 70Initialize index of smaller element, i = -1Traverse elements from j = low to high-1j = 0 : Since arr[j] <= pivot, do i++ and swap(arr[i], arr[j])i = 0 arr[] = {10, 80, 30, 90, 40, 50, 70} // No change as i and j // are samej = 1 : Since arr[j] > pivot, do nothing// No change in i and arr[]j = 2 : Since arr[j] <= pivot, do i++ and swap(arr[i], arr[j])i = 1arr[] = {10, 30, 80, 90, 40, 50, 70} // We swap 80 and 30 j = 3 : Since arr[j] > pivot, do nothing// No change in i and arr[]j = 4 : Since arr[j] <= pivot, do i++ and swap(arr[i], arr[j])i = 2arr[] = {10, 30, 40, 90, 80, 50, 70} // 80 and 40 Swappedj = 5 : Since arr[j] <= pivot, do i++ and swap arr[i] with arr[j] i = 3 arr[] = {10, 30, 40, 50, 80, 90, 70} // 90 and 50 Swapped We come out of loop because j is now equal to high-1.Finally we place pivot at correct position by swappingarr[i+1] and arr[high] (or pivot) arr[] = {10, 30, 40, 50, 70, 90, 80} // 80 and 70 Swapped Now 70 is at its correct place. All elements smaller than70 are before it and all elements greater than 70 are afterit.实现:
以下是Java实现。
// Java program for implementation of QuickSortclass QuickSort{/* This function takes last element as pivot,places the pivot element at its correctposition in sorted array, and places allsmaller (smaller than pivot) to left ofpivot and all greater elements to rightof pivot */int partition(int arr[], int low, int high){int pivot = arr[high]; int i = (low-1); // index of smaller elementfor (int j=low; j Array to be sorted,low --> Starting index,high --> Ending index */void sort(int arr[], int low, int high){if (low < high){/* pi is partitioning index, arr[pi] is now at right place */int pi = partition(arr, low, high);// Recursively sort elements before// partition and after partitionsort(arr, low, pi-1);sort(arr, pi+1, high);}}/* A utility function to print array of size n */static void printArray(int arr[]){int n = arr.length;for (int i=0; i 输出:
排序数组:1 5 7 8 9 10
QuickSort分析QuickSort
所用的时间一般可以写成如下。
T(n)= T(k)+ T(nk-1)+(n)
前两个术语是两个递归调用,最后一个术语是分区过程。k是小于枢轴的元素的数量。
QuickSort所用的时间取决于输入数组和分区策略。以下是三例。
最差情况: 最坏的情况发生在分区过程总是选择最大或最小的元素作为枢轴。如果我们考虑以上分析策略,其中最后一个元素总是被选为枢轴,则最坏的情况将发生在数组已经按递增或递减的顺序排列时。以下是最坏情况的复发。
T(n)= T(0)+ T(n-1)+
上述复发的解决方案为(n 2)。
最佳情况: 当分区过程总是将中间元素选为枢轴时,会发生最佳情况。以下是最佳情况下的复发。
T(n)= 2T(n / 2)+
上述复发的解决方案是(nLogn)。可以使用大师定理的案例2来解决。
平均情况:
要进行平均案例分析,我们需要考虑数组的所有可能的排列,并计算每个排列所花费的时间并不容易。
通过考虑分区将O(n / 9)个元素放在一个集合中的情况,并且其他集合中的O(9n / 10)个元素,我们可以得到平均情况的想法。以下是这种情况的复发。
T(n)= T(n / 9)+ T(9n / 10)+
上述复发的解决方案也是O(nLogn)
尽管QuickSort的最糟糕的时间复杂度是O(n 2),它比许多其他排序算法(如合并排序和堆排序)更多,但QuickSort在实践中更快,因为它的内部循环可以在大多数架构上高效地实现,而在大多数现实世界的数据。QuickSort可以通过改变枢轴的选择以不同的方式实现,因此,给定类型的数据很少发生最坏的情况。然而,当数据庞大并存储在外部存储器中时,合并排序通常被认为更好。
什么是3路QuickSort?
在简单的QuickSort算法中,我们选择一个元素作为枢轴,对数组围绕枢轴进行分区,并在枢轴的左侧和右侧重新生成子阵列。
考虑一个有许多冗余元素的数组。例如,{1,2,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4。如果在Simple QuickSort中选择4作为枢轴,我们仅修复一个4并递归处理剩余的事件。在3 Way QuickSort中,数组arr [l..r]分为3部分:
a)arr [l..i]少于枢轴的元素。
b)arr [i + 1..j-1]元素等于枢轴。
c)arr [j..r]大于枢轴的元素。
看到这个实现。
如何为链接列表实现QuickSort?
QuickSort单链接列表
QuickSort双重链接列表
我们可以迭代地实现QuickSort吗?
是的,请参考迭代快速排序。
为什么快速排序比MergeSort优先于排序数组
快速排序的一般形式是一个就地排序(即它不需要任何额外的存储),而合并排序需要O(N)个额外的存储,N表示数组大小可能相当昂贵。分配和分配用于合并排序的额外空间增加了算法的运行时间。比较平均复杂度,我们发现这两种类型都具有O(NlogN)平均复杂度,但常数不同。对于数组,由于使用额外的O(N)存储空间,合并排序丢失。
快速排序的最实用的实现使用随机化版本。随机化版本预计O(nLogn)的时间复杂度。最坏的情况也可能在随机化版本中,但是对于特定模式(如排序的数组)并不会发生最坏的情况,并且随机的快速排序在实践中运行良好。
快速排序也是一种缓存友好的排序算法,因为它在数组使用时具有良好的参考位置。
快速排序也是尾递归,因此尾调用优化完成。
为什么MergeSort是优先于QuickSort的链接列表?
在链表的情况下,情况不同,主要是由于数组和链表的内存分配不同。与数组不同,链表列表节点在内存中可能不相邻。与数组不同,在链表中,我们可以在O(1)个额外空间和O(1)时间的中间插入项目。因此,可以实现合并排序的合并操作,而不需要额外的链接列表空间。
在数组中,随着元素在内存中的连续性,我们可以随机访问。让我们说我们有一个整数(4字节)数组A,让A [0]的地址为x然后访问A [i],我们可以直接访问(x + i * 4)的内存。与数组不同,我们不能在链表中进行随机访问。快速排序需要很多这种访问。在链接列表中访问第i个索引,我们必须将每个节点从头到尾传播到第i个节点,因为我们没有连续的内存块。因此,开销增加了快速排序。合并排序顺序访问数据,随机访问的需求很低。
如何优化QuickSort,以便在最坏的情况下需要O(Log n)额外的空间?
请参阅QuickSort尾部调用优化(将最坏情况下降到日志n)
花絮:







QuickSort测验
参考文献:http :
//en.wikipedia.org/wiki/Quicksort
GeeksforGeeks / GeeksQuiz上的其他排序算法:
选择排序,气泡排序,插入排序,合并排序,堆排序,QuickSort,基数排序, 计数排序, 铲斗排序, ShellSort, 梳子排序,鸽子排序
原文参考:http://www.geeksforgeeks.org/quick-sort/
- java快速排序专栏
- 排序-快速排序-Java
- java排序之快速排序
- Java排序算法 快速排序
- 快速排序(java排序)
- java 快速排序,冒泡排序
- 算法:排序----Java快速排序
- 【交换排序】快速排序--Java
- java 插入排序+快速排序
- Java 排序之 快速排序
- java排序之快速排序
- Java排序算法:快速排序
- Java排序-快速排序
- Java排序算法:快速排序
- Java排序算法--》快速排序
- JAVA排序算法---快速排序
- Java 快速排序 归并排序
- Java排序算法--快速排序
- Lua中可完美运行的三目运算符
- 2017 Multi-University Training Contest
- vm中Linux无法ping通网站的解决办法
- java 基于springboot使用ssh(spring + springmvc + hibernate)分库配置多数据源方式
- get、put、post、delete的区别
- java快速排序专栏
- 关于turbine集群监控与消息代理结合出错的问题
- 语言 ,规范,协议,框架
- Balala Power!
- Android开发注意问题
- C语言 pow() 用法及分析
- 剑指Offer读书笔记(1)
- 引用及操作符的重载
- spring对接InfluxDB(二)--数据获取之单条查询


