相关性学习-皮尔逊相关系数
来源:互联网 发布:淘宝账号销号 编辑:程序博客网 时间:2024/06/05 11:59
链接:https://www.zhihu.com/question/19734616/answer/117730676
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
要理解Pearson相关系数,首先要理解协方差(Covariance),协方差是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反,公式如下:
<img src="https://pic3.zhimg.com/0dfac74fd0cc7e4670fc04e15a5d79e2_b.png" data-rawwidth="381" data-rawheight="67" class="content_image" width="381">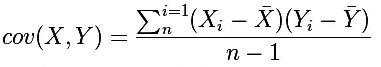
Pearson相关系数公式如下:
<img src="https://pic2.zhimg.com/95c7b4484dc46f28390c4de96c83b915_b.png" data-rawwidth="430" data-rawheight="62" class="origin_image zh-lightbox-thumb" width="430" data-original="https://pic2.zhimg.com/95c7b4484dc46f28390c4de96c83b915_r.png">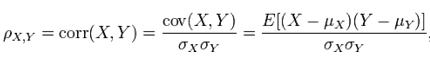
由公式可知,Pearson相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的关联程度,例如,现在二维空间中分布着一些数据,我们想知道数据点坐标X轴和Y轴的相关程度,如果X与Y的相关程度较小但是数据分布的比较离散,这样会导致求出的协方差值较大,用这个值来度量相关程度是不合理的,如下图:
<img src="https://pic3.zhimg.com/e7579024b7774f6f9b7fa80588e53532_b.png" data-rawwidth="406" data-rawheight="374" class="content_image" width="406">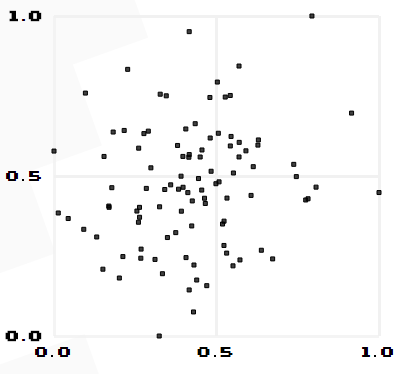
为了更好的度量两个随机变量的相关程度,引入了Pearson相关系数,其在协方差的基础上除以了两个随机变量的标准差,容易得出,pearson是一个介于-1和1之间的值,当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。《数据挖掘导论》给出了一个很好的图来说明:
<img src="https://pic2.zhimg.com/e31afcd8a6fa446a5b5b0bdd87606f1d_b.png" data-rawwidth="561" data-rawheight="383" class="origin_image zh-lightbox-thumb" width="561" data-original="https://pic2.zhimg.com/e31afcd8a6fa446a5b5b0bdd87606f1d_r.png">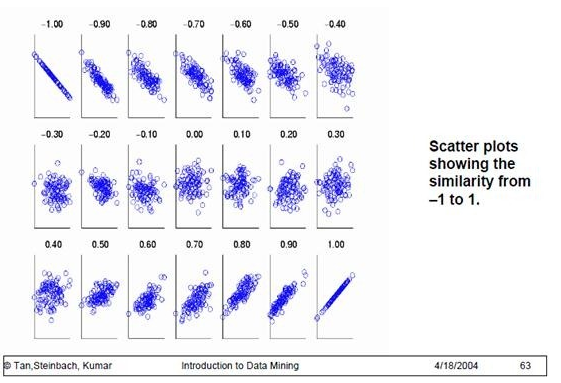
链接:https://www.zhihu.com/question/19734616/answer/174098489
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
cos<a, b> = a • b / |a|•|b|
假设a = (3, 1, 0), b = (2, -1, 2)
分子是a, b两个向量的内积, (3, 1, 0) • (2, -1, 2) = 3•2 + 1•(-1) + 0•2 = 5
分母是两个向量模的乘积.
总之这个cos的计算不要太简单...高考一向这是送分题...
然后问题来了, 皮尔逊系数和这个cos啥关系...(不好意思借用了我们学校老师的课件...)
&lt;img src="https://pic2.zhimg.com/v2-71de3ac89fb7e62a24eae9bdbb56aa8d_b.png" data-rawwidth="627" data-rawheight="172" class="origin_image zh-lightbox-thumb" width="627" data-original="https://pic2.zhimg.com/v2-71de3ac89fb7e62a24eae9bdbb56aa8d_r.png"&gt;
其实皮尔逊系数就是cos计算之前两个向量都先搞个标准化...就这么简单...
还是解释下吧:
标准化的意思是说, 对每个向量, 我先计算所有元素的平均值avg, 然后每个元素减去这个avg, 得到的这个向量叫做被标准化(也叫正规化)的向量. 基本上所有的机器学习, 数据挖掘用到向量的时候, 都要预处理做标准化.
我们观察皮尔逊系数的公式:
分子部分: 每个向量的每个数字要先减掉向量各个数字的平均值, 这就是在标准化.
分母部分: 两个根号式子就是在做取模运算, 里面的所有r也要减掉平均值, 其实也就是在做标准化.
- 相关性学习-皮尔逊相关系数
- 相关性学习-皮尔逊相关系数2
- 相关性学习—python实现Pearson相关系数
- 【机器学习系列】皮尔逊相关系数
- 相关性检验--Spearman秩相关系数和皮尔森相关系数
- 相关性检验-Spearman秩相关系数和皮尔森相关系数
- 相关性检验–Spearman秩相关系数和皮尔森相关系数
- 相关性、平均值、标准差、相关系数、回归线及最小二乘法
- 相关性、平均值、标准差、相关系数、回归线及最小二乘法
- 相关性学习
- 机器学习笔记——皮尔逊相关系数
- 机器学习笔记——皮尔逊相关系数
- 皮尔逊相关系数
- 皮尔逊相关系数
- 皮尔逊相关系数
- 皮尔逊相关系数
- 皮尔逊相关系数
- 相似度度量2:皮尔森相关系数和斯皮尔曼相关性
- 二分查找
- shell--鸟哥私房菜(1)
- win7命令行 端口占用 查询进程号 杀进程
- css选择器
- 【面经笔记】深信服电话二面
- 相关性学习-皮尔逊相关系数
- Parallel Scavenge收集器
- LFR简单使用入门
- 超强自定义TabLayout
- Codis源码解析——codis-server添加到集群
- 【nginx-rtmp】04、获取客户端订阅/连接数(Getting number of subscribers)
- Mysql 中!=和 <>
- aix下扩充swap大小
- JDNI配置和使用


