深度学习入门 --- 自我学习与半监督学习
来源:互联网 发布:阿里云大数据 编辑:程序博客网 时间:2024/06/02 04:38
该章节参考ufldl
1.什么是自我学习(Self-Taught Learning)与半监督学习
首先,什么是半监督学习?当你手头上拥有在大量未标注数据和少量的已标注数据,那这种场景就可以说是半监督学习。自我学习和半监督学习的场景一样,不过有个细节不一样。
自学习(self-taught learning) 是更为一般的、更强大的学习方式,它不要求未标注数据 和已标注数据有同样的分布。而半监督学习不一样,它要求未标注数据 和已标注数据服从同样的分布。下面通过例子解释二者的区别。
假定有一个计算机视觉方面的任务,目标是区分汽车和摩托车图像;哪里可以获取大量的未标注数据呢?最简单的方式可能是从互联网上下载一些随机的图像数据集,在这些数据上训练出一个稀疏自编码器,从中得到有用的特征。这个例子里,未标注数据对比已标注数据,是一个完全不同的数据分布(未标注数据集中,或许其中一些图像包含汽车或者摩托车,但不是所有的图像都如此)。这种情形被称为自学习。
相反,如果有大量的未标注图像数据,要么是汽车图像,要么是摩托车图像,仅仅是缺失了类标号(没有标注每张图片到底是汽车还是摩托车)。也可以用这些未标注数据来学习特征。这种方式,即要求未标注样本和带标注样本服从相同的分布,有时候被称为半监督学习。在实践中,常常无法找到满足这种要求的未标注数据(到哪里找到一个每张图像不是汽车就是摩托车,只是丢失了类标号的图像数据库?)因此,自学习在无标注数据集的特征学习中应用更广。
2.自我学习的模型
###2.1 数据预处理
首先对未标记数据和已标记数据进行相同的数据预处理。比如进行相同的归一化。如果对未标记数据进行PCA,那么PCA过程得到的特征向量矩阵U需要保留下来。之后对于已标记数据,应用
###2.2未标记数据训练稀疏自编码器
不懂稀疏自编码器的同学,可以参考我这篇博客
首先我们利用未标记数据训练一个自编码器。 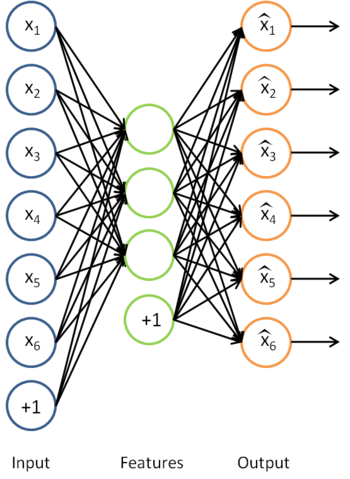
利用训练得到的模型参数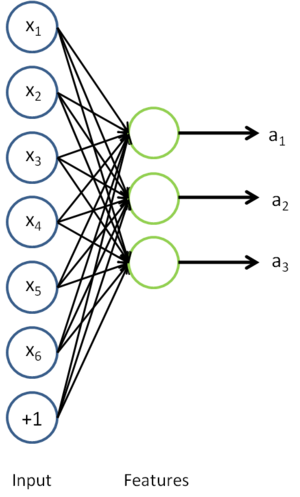
这实际上就是之前得到的稀疏自编码器,在这里去掉了最后一层。
###2.3 有标记数据特征转换,然后实现监督学习
假定有大小为
经过变换后,训练集就变成
最终,可以训练出一个有监督学习算法(例如 svm, logistic regression 等),得到一个判别函数对 y 值进行预测。预测过程如下:给定一个测试样本
3.补充
在有标记示例较少时,如何利用大量的未标记示例来改善学习性能已成为当前机器学习研究中最受关注的问题之一。目前,利用未标记示例的主流学习技术主要有三大类[Zhou06],即半监督学习(semi-supervisedlearning)、直推学习(transductive learning)和主动学习(active learning)。这三类技术都是试图利用大量的未标记示例来辅助对少量有标记示例的学习,但它们的基本思想却有显著的不同。在半监督学习[ChapelleSZ06][Zhu06]中,学习器试图自行利用未标记示例,即整个学习过程不需人工干预,仅基于学习器自身对未标记示例进行利用。直推学习[Vapnik98][Joachims99]与半监督学习的相似之处是它也是由学习器自行利用未标记示例,但不同的是,直推学习假定未标记示例就是测试例,即学习的目的就是在这些未标记示例上取得最佳泛化能力。换句话说,半监督学习考虑的是一个“开放世界”,即在进行学习时并不知道要预测的示例是什么,而直推学习考虑的则是一个“封闭世界”,在学习时已经知道了需要预测哪些示例。主动学习[SeungOS92][LewisG94][AbeM98]和前面两类技术不同,它假设学习器对环境有一定的控制能力,可以“主动地”向学习器之外的某个“神谕”(oracle) 2 进行查询来获得训练例的标记。因此,在主动学习中,学习器自行挑选出一些未标记示例并通过神谕查询获得这些示例的标记,然后再将这些有标记示例作为训练例来进行常规的监督学习,而其技术难点则在于如何使用尽可能少的查询来获得强泛化能力。对比半监督学习、直推学习和主动学习可以看出,后者在利用未标记示例的过程中需要与外界进行交互,而前两者则完全依靠学习器自身,正因为此,也有一些研究者将直推学习作为一种半监督学习技术来进行研究。(出自周志华教授)
- 深度学习入门 --- 自我学习与半监督学习
- ufldl 深度学习入门 第三发: 自我学习与无监督特征学习
- 自我学习与半监督学习的区别
- 监督学习,非监督学习与半监督学习
- 概念:监督学习、无监督学习与半监督学习
- 机器学习入门:监督学习与无监督学习
- 弱监督深度学习
- 自我学习,监督学习,半监督学习和迁移学习的区别
- 【机器学习 基本概念】监督学习、无监督学习、半监督学习与强化学习
- 非监督特征学习与深度学习(十)----池化
- 一文读懂监督学习、无监督学习、半监督学习、强化学习这四种深度学习方式
- 监督学习与无监督学习
- 监督学习与非监督学习
- 监督学习与无监督学习
- 监督学习与无监督学习
- 无监督学习与监督学习
- 监督学习与无监督学习
- 监督学习与无监督学习
- java三大特性之封装
- rac连接failover,连接时负载均衡,客户/服务端taf
- 关于居中,不管是文字或图片
- Hopscotch
- 沃顿商学院自我管理课——埃里克.格雷腾斯
- 深度学习入门 --- 自我学习与半监督学习
- Vue引入远程JS文件
- 2017 Multi-University Training Contest
- hbase的基本指令
- Drainage Ditches
- bzoj2049 [Sdoi2008]Cave 洞穴勘测 [LCT]
- python连接SQL报错:1366, "Incorrect string value: '\\xF0\\x9F\\x98\\x81'
- Mac 安装 hadoop+hive+hbase+spark
- 深度学习(一)


