在讲解内核中用于组织内存的数据结构之前,考虑到术语不总是容易理解,所以先来看看几个概念。我们首先考虑NUMA系统,这样,在UMA系统上介绍这些概念就非常容易了。
下图给出内存划分的图示:
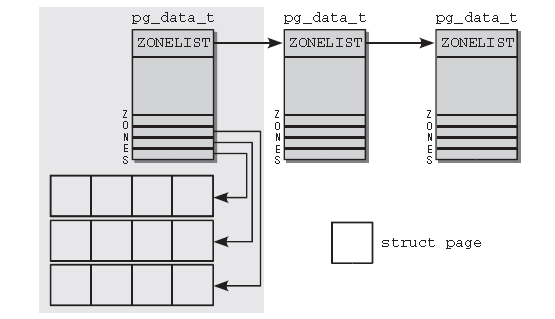
首先,内核划分为结点。每个结点关联到系统中的一个处理器,在内核中表示为pa_data_t的实例(稍后定义该数据结构)。各个结点又划分为内存域,是内存的进一步细分。例如,对可用于(ISA设备的)DMA操作的内存区是有限制的。只有钱16MB适用,还有一个高端内存区无法直接映射,在二者之间是通用的“普通”内存区。内核引入下列常量来枚举系统中的所有内存域:
- enum zone_type {
- #ifdef CONFIG_ZONE_DMA
- ZONE_DMA,
- #endif
- #ifdef CONFIG_ZONE_DMA32
- ZONE_DMA32,
- #endif
- ZONE_NORMAL,
- #ifdef CONFIG_HIGHMEM
- ZONE_HIGHMEM,
- #endif
- ZONE_MOVABLE,
- MAX_NR_ZONES
- };
各个内存域都关联了一个数组,用来阻止属于该内存域的物理内存页(在内核中称之为页帧)。对每个页帧,都分配了一个struct page实例以及所需的管理数据。各个内存结点都保存在一个单链表中,供内核遍历。处于性能考虑,在为进程分配内存时,内核总是试图在当前运行的CPU相关联的NUMA结点上进行。但这并不总是可行的,例如,该结点的内存可能已经用尽。对此情况,每个结点都提供了一个备用列表(借助于struct zonelist)。该列表包含了其他结点(和相关的内存域),可用于代替当前结点分配内存,列表项的位置越靠后,就越不适合分配。在UMA系统上,上图中只有一个pg_data_t结点,其他的都不变。
主要数据结构分析:
struct pg_data_t详细分析:
- typedef struct pglist_data {
- struct zone node_zones[MAX_NR_ZONES];
- struct zonelist node_zonelists[MAX_ZONELISTS];
- int nr_zones;
- #ifdef CONFIG_FLAT_NODE_MEM_MAP
- struct page *node_mem_map;
- #endif
- struct bootmem_data *bdata;
-
- #ifdef CONFIG_MEMORY_HOTPLUG
- spinlock_t node_size_lock;
- #endif
- unsigned long node_start_pfn;
- unsigned long node_present_pages;
- unsigned long node_spanned_pages;
- int node_id;
- wait_queue_head_t kswapd_wait;
- struct task_struct *kswapd;
- int kswapd_max_order;
- } pg_data_t;
struct zone详细分析:
该结构比较特殊的方面是它由ZONE_PADDING分割为几个部分。这是因为对zone结构的访问非常频繁。在多处理器系统上,通常会有不同的CPU试图同时访问结构成员。因此使用锁(后面的博客会详细介绍)防止它们彼此干扰,避免错误和不一致。由于内核对该结构的访问非常频繁,因此会经常性地获取该结构的两个自旋锁zone->lock和zone->lru_lock。
如果数据保存在CPU高速缓存中,那么会处理得更快速。高速缓存分为行,每一行负责不同的内存区。内核使用ZONE_PADDING宏生成“填充”字段添加到结构中,以确保每个自旋锁都处于自身的缓存行中。还使用了编译关键字__cacheline_internodealigned_in_smp,用以实现最优的高速缓存对齐方式。
该结构的最后两个部分也通过填充字段彼此分隔开来。两者都不包含锁,主要目的是将数据保持在一个缓存行中,便于快速访问,从而无需从内存加载数据。由于填充字段造成结构长度的增加是可以忽略的,特别是在内核内存中zone结构的实例相对很少。
struct page详细分析:
- struct page {
- unsigned long flags;
- atomic_t _count;
- union {
- atomic_t _mapcount;
- unsigned int inuse;
- };
- union {
- struct {
- unsigned long private;
- struct address_space *mapping;
- };
- #if NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS
- spinlock_t ptl;
- #endif
- struct kmem_cache *slab;
- struct page *first_page;
- };
- union {
- pgoff_t index;
- void *freelist;
- };
- struct list_head lru;
-
-
-
-
-
-
-
-
-
-
- #if defined(WANT_PAGE_VIRTUAL)
- void *virtual;
- #endif /* WANT_PAGE_VIRTUAL */
- };
上述结构中使用了大量的union结构,考虑一个例子:一个物理内存页能够通过多个地方的不同页表映射到虚拟地址空间,内核想要跟踪有多少地方映射了该页,为此,struct page中有一个计数器用于计算映射的数目。如果一页用于slab分配器(后面的博客会详细介绍),那么可以确保只有内核会使用该页,而不会有其它地方使用,因此映射计数信息就是多余的,因此内核可以重新解释该字段,用来表示该页被细分为多少个小的内存对象使用,联合体就很适用于该问题。

<script>window._bd_share_config={"common":{"bdSnsKey":{},"bdText":"","bdMini":"2","bdMiniList":false,"bdPic":"","bdStyle":"0","bdSize":"16"},"share":{}};with(document)0[(getElementsByTagName('head')[0]||body).appendChild(createElement('script')).src='http://bdimg.share.baidu.com/static/api/js/share.js?v=89860593.js?cdnversion='+~(-new Date()/36e5)];</script>
阅读(130) | 评论(0) | 转发(0) |


