更加深入剖析Kafka--Producer篇(中)
来源:互联网 发布:手机号码免费定位软件 编辑:程序博客网 时间:2024/06/11 09:43
客户端
客户端和服务端都是网络传输的终(端)点,两者角色是相对而言的,前者主动发起请求并接收后者应答。
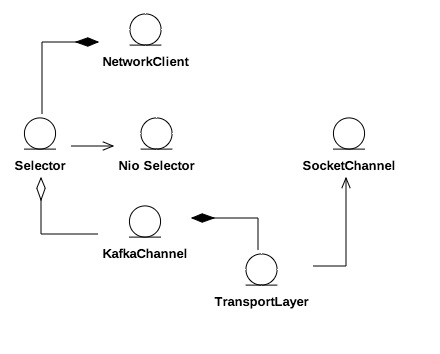
两端之间由通道(连接)连通,每个客户端都有0到多个通道连接0到多个服务端。通道通过传输层交换数据,传输层有加密和明文两种实现。客户端通过选择器轮询所有通道,标记连接状态并收发网络数据,客户端获得所有通道处理结果再统一应答。这样就将客户端与具体网络I/O实现解耦,网络对客户端而言就成为一个整体。
客户端请求
客户端请求来自上游,它是发送给客户端而非由客户端发出的,它是网络请求的载体而非网络请求。客户端对请求的处理分成两步:1)客户端收到请求,记录其为处理中请求,再将网络请求写入发送缓冲。2)客户端开始轮询:选择器先全通道轮询并记录轮询结果:已发送请求(completedSends)、已接收回复(completedReceives)和所有无效通道(disconnected);客户端再拉取选择器轮询结果,判断哪些请求已完成,并逐一回复。 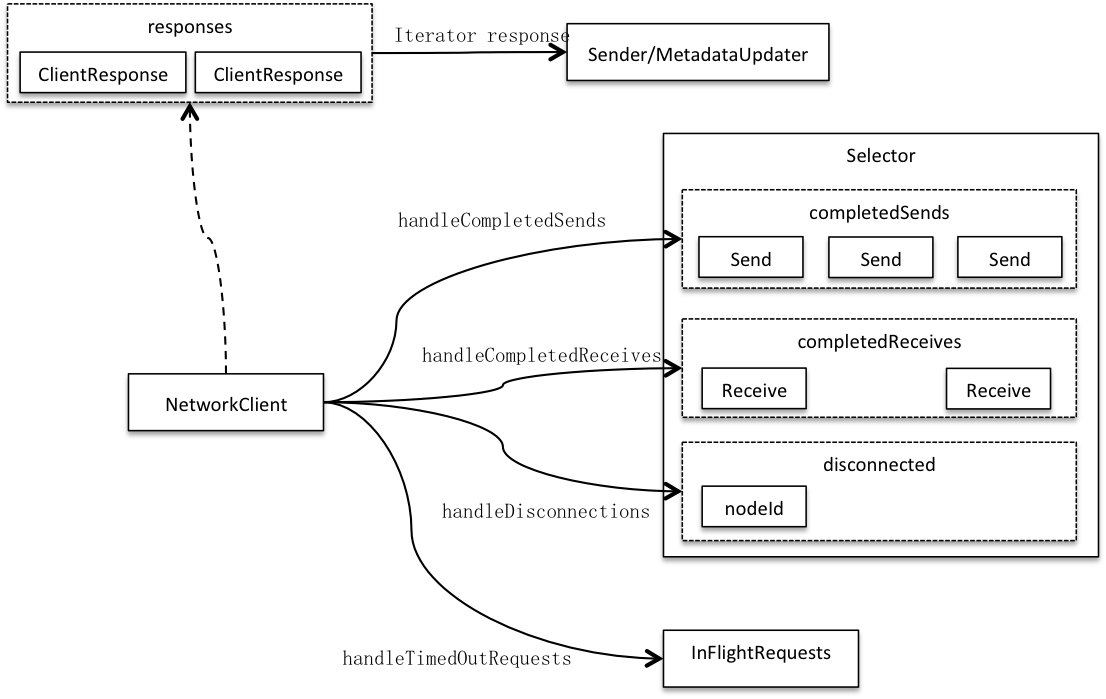
客户端请求有三个关键属性,依次为网络请求、需要网络响应和请求完成回调接口。
* 网络请求是个数据载体,它可以承载各种类型请求,任何类型的请求在其中都以一定格式序列化成字节数据,网络I/O传输的也是这部分字节。
* 需要网络响应用于标识客户端请求是否需要服务端确认,如果不需要则在网络请求发送成功后客户端请求立即成功。
* 回调接口注册在上游,用于请求完成后回调执行,它的回调方法参数是客户端响应,因此执行时会将响应回复给上游。
客户端响应也有三个关键属性,分别是坏连接标识,客户端请求引用和网络响应。客户端请求必定有回复,反馈网络I/O结果。如果有坏连接代表该笔请求失败。 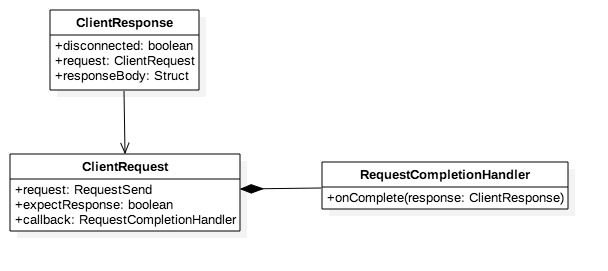
场景演绎
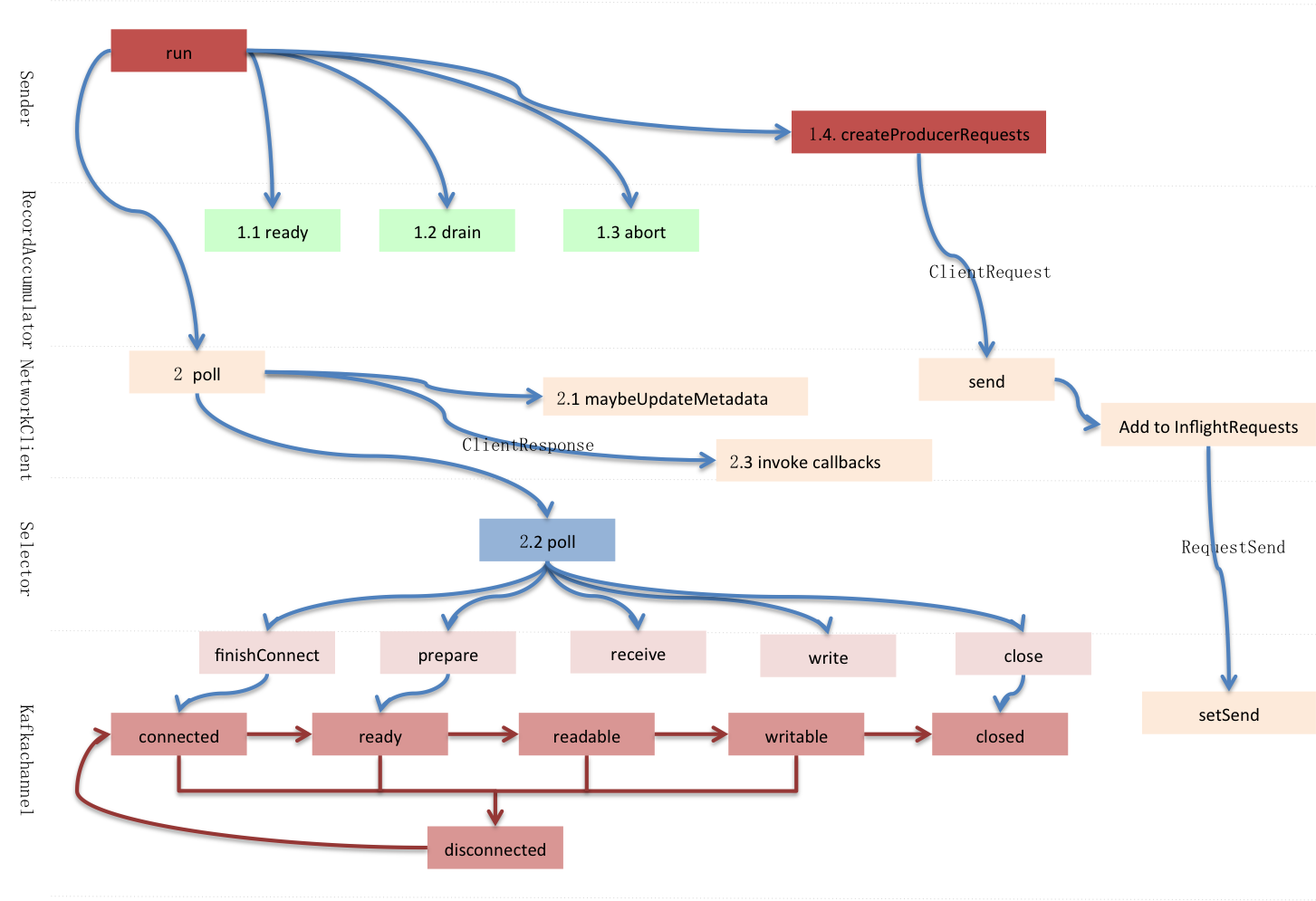
客户端上游有可能是生产者或者元数据更新组件,两者的请求类型分别为ProduceRequest和MetadataRequest,它们按传输报文格式将批次/主题转成标准格式Struct。
以发送者上游举例,它挤出批次,并构建生产请求。消息发送是以批次为最小单位,但出于节省网络资源,会将同节点下所有待发送批次合并到一个请求。 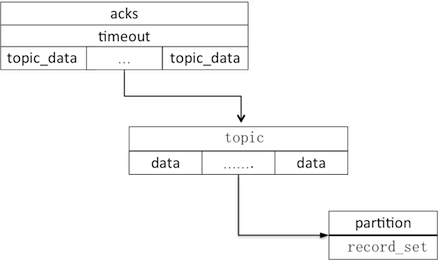
节点下的批次是个topic_data数组,topic_data是归属同一topic的所有批次,一个data就是一个批次消息集。Acks和timeout分别表示需要确认收到的replica个数和请求超时时间。
生产请求构建完成后,被序列化成字节缓冲写入RequestSend,后者再作为ClientRequest的网络请求属性发送给客户端,……
积累器
生产者就好比在向一个有分槽的水池注水,每次注入必须向同一个水槽,当前水槽容量不足则换一个,老水槽即使还有剩余空间,也不能被再次使用,除非水被排出。发送者排水也水槽为单位,一次性排出被排水槽全部水量。总水位满则禁止注水,生产者需等待足够水量放出,一段时间还没有足够空间则放弃。
在Kafka中,水池就是积累器即下图的RecordAccumulator,水槽则是消息批次即RecordBatch,注水和排水则分别应对追加消息和提取消息过程。 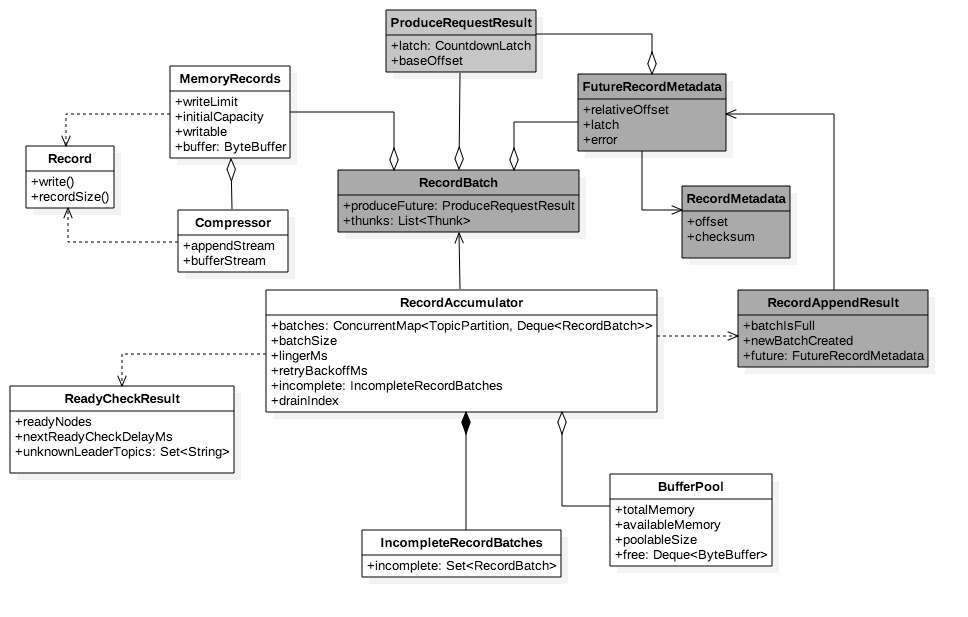
积累器以分区分组批次,每组一个队列,按时间先后将分区排队,只有最后/新入队的批次是开放状态,允许消息追入。消息只被追加到相应分组的最新批次,相应的也只有最老批次才被挤出,如果只有一个批次,先close再挤出。
挤出
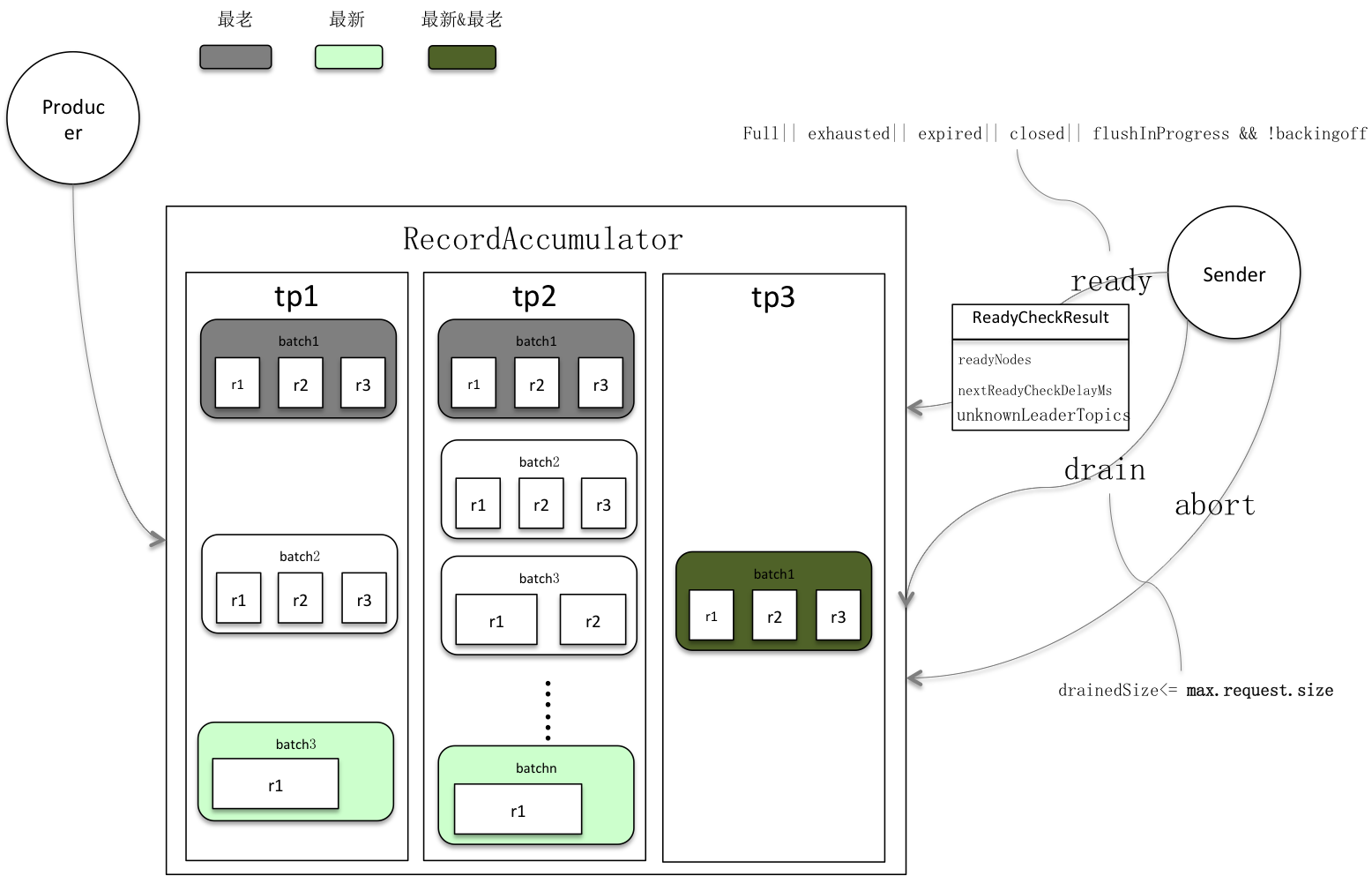
积累器在挤出前会做就绪检查(ready),就绪检查返回上图ReadyCheckResult,它有三个属性ReadyNodes、UnknownLeaderTopics和NextReadyCheckDelayMs。分别代表有待发送批次节点,分区leader未知topic和下次就绪检查时间点。
* 积累器被关闭或预分配总内存占满以及Producer强制刷新
KafkaProducer#flush()三个全局性动作会让任意批次进入待发送;此外批次被关闭或逗留时间超时也会使该它进入待发送。有待发送批次意味该节点处于就绪状态,需提取待发送批次发送。 * 领袖未决可能因为集群拓扑结构发生变化,需要更新元数据,Sender会申请对这些节点做元数据更新。
* 生产频率较低时,积累器很难积累满至少一个批次,如果此时就绪检查又在逗留超时之前,就会发生无就绪节点的情况。比较好的处理方式就是堵塞这段时间,因为在这段时间之前,Sender执行多少次都会一样。Kafka将这段时间交给nio select,获取更多读事件同时又堵塞了线程,这里是特别特别棒的细节处理,因为CPU不断来回切换select线程会非常浪费CPU资源。
就绪检查是整个Sender的先奏,它决定了后面挤出批次的范围甚至客户端轮询网络I/O事件的时间跨度:
1) 就绪节点被选出后,Sender对它们做连接分析,移除坏连接节点。
2) Sender会对剩下的节点做挤出(drain),返回<就绪节点->待发送批次集合>的映射。积累器遍历就绪节点的所有分区队列,每个分区只挤出最老批次,最终每个就绪节点就都提取出一个批次集合。集合长度会有限制,里面的元素即批次总大小必须小于max.request.size。max.request.size是单笔请求的大小上限,在网络传输时每个集合(节点)下的的批次会合并到一个请求,这样有利于显著减少网络开销,因此提取的批次总大小不能超过该值。
3) 最后Sender还会做丢弃(abort),它遍历所有未挤出批次将请求超时的丢弃。请求超时由timeout.ms决定,它从批次处于可发送状态(记录满或逗留时间到)的时间A开始算,如果
追加
积累器收到消息后找到归属分区的最新批次队追加,如果批次无足够剩余容量则申请新批次。如下图,Producer追加三条消息,第一条较小追加成功;第二条5k大于剩余容量4k,新分配默认大小批次;第三条20k不仅大于剩余空间11k还大于默认大小16k,按消息大小新分配批次。 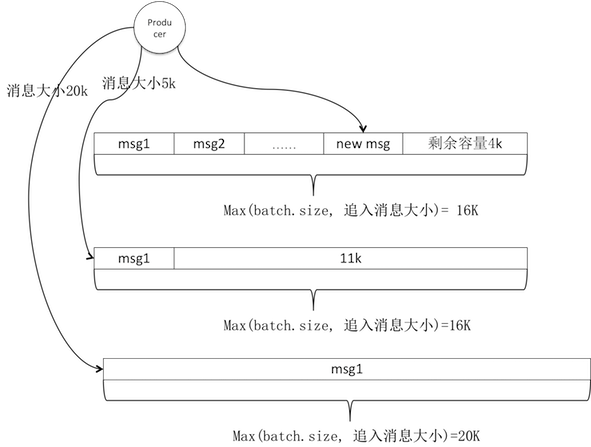
新批次会记录到incomplete未完成批次中,在生产者关闭时要丢弃所有未完成批次,保证所有消息源能感知到消息状态。生产者有可能同步等待消息发送结果或预定义拦截器触发结果事件。
消息追加成功返回RecordAppendResult,结构在图3.0.2中用灰色底标注,它有三个属性,其中batchIsFull和newBatchCreated用于判断是否有关闭和新建批次,它们可用于判断是否立即需要唤醒被nio select堵塞的线程。因为批次集满或者新建意味着下次提取有极大可能可以挤出数据,所以此时应该快速进入下次ready周期。
另一属性future是FutureRecordMetadata类型,它是批次返回的消息追入返回值,是对RecordMetadata的引用。后者代表消息元数据,记录消息在分区上存储的偏移量等元属性,它只会在Sender成功发送或废弃消息后才会生成,也就是在主线程追加成功后某个未来时间段,因此对追加来说是未来结果。
ProduceRequestResult是批次的全局变量同时也是未来消息元数据全局变量。它由批次初始化并在批次返回未来消息元数据时传递进去。未来消息元数据是每次追加的返回值,因此是消息级的实例;而ProduceRequestResult是批次级别的实例,因为它由批次初始化。
类似Jdk Future,未来消息元数据也可以堵塞get。ProduceRequestResult内置CountdownLatch且count times是1,它被用来堵塞未来消息元数据的get请求。另一方面Sender线程会保证done每个批次,done会释放回写批次在分区存储的开始位移即baseOffset到ProduceRequestResult以及拉开latch。 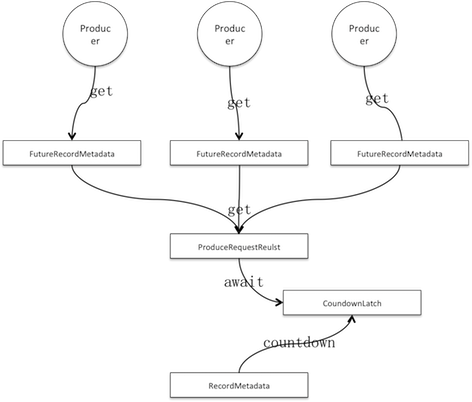
因为latch的count times是1,所以countdown就会将其拉开,从而所有被堵塞的线程被释放。这里也是Kafka设计上的一处精妙点,批次级的ProduceRequestResult用来堵塞消息级请求,批次的完成就可以用来释放消息级的请求。
主线程请求被释放会获取服务端的返回值,未来消息元数据可以方便读取ProduceRequestResult(见图4.0.2两者关系),用后者来自服务端返回的开始位移加上自身记录的消息在批次中的相对顺序即relativeOffset即可算出消息在服务端的分区存储偏移量,再构造RecordMetadata作为返回值;如果批次不是正常完成,例如服务端处理失败或批次被丢弃,ProduceRequestResult被标记有异常,此时直接抛出执行异常。 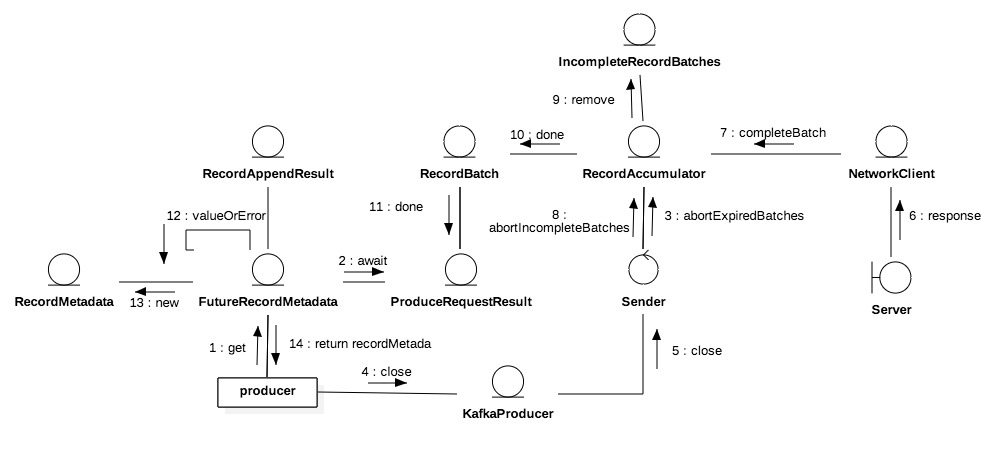
以下三种动作会触发批次done:
1)超时丢弃;2)Producer强制关闭;3)服务端响应。
* Producer强制关闭会把Sender标记为forceClosed,Sender执行完网络轮询后如果需要强制关闭会丢弃incomplete中所有未完成批次。
* 丢弃done会把批次完成状态标记为异常:超时丢弃为超时异常,强制关闭为非法状态异常。
- 更加深入剖析Kafka--Producer篇(中)
- 更加深入剖析Kafka--Producer篇(上)
- 更加深入理解Kafka--Producer篇(下)
- kafka 之 producer篇
- kafka-深入剖析
- Kafka Producer
- kafka producer
- kafka--producer
- kafka producer 中partition 使用方式
- Apache Kafka编程入门指南:Producer篇
- java编写Producer(线程池,kafka)
- kafka生产者示例(kafka-python producer example)
- 使用启动kafka中producer出现UnrecognizedOptionException错误
- kafka producer的serializer
- kafka producer总结
- Kafka Producer APIs
- Kafka Producer接口
- kafka Producer API使用
- HDU.2516 取石子游戏 (博弈论 斐波那契博弈)
- 更加深入剖析Kafka--Producer篇(上)
- 在eclipse中快速打开项目中的文件(夹)在硬盘的位置
- HDU6078-Wavel Sequence
- Shell语法训练
- 更加深入剖析Kafka--Producer篇(中)
- [JQuery小笔记]淡出淡入
- Linux下的文件操作命令
- POJ.1067 取石子游戏 (博弈论 威佐夫博弈)
- 常用设计模式
- 深入了解HTTP协议
- 网络编程:基于C语言的简易代理服务器实现(proxylab)
- 数据埋点统计前端代码
- Spring Junit4 Test中JDBC事务回滚抛异常Connection is null


