更加深入理解Kafka--Producer篇(下)
来源:互联网 发布:unity3d如何设置中文 编辑:程序博客网 时间:2024/06/05 17:04
批次
积累器在创建批次之前,就在堆上为它预分配一段空间,这段空间用于装载消息。消息最终会顺序落到内存块中形成消息集。批次的逻辑结构如下: 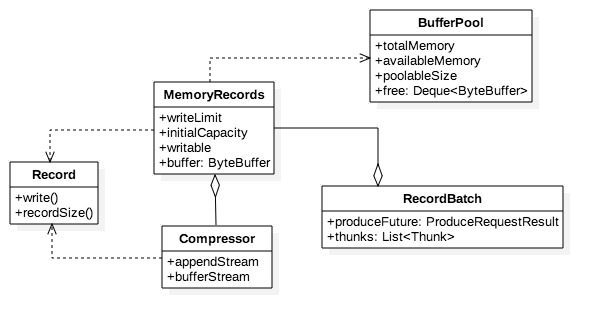
* MemoryRecords即消息集的抽象,它容纳0到多条Record。
* Record则代表消息在内存中的状态,即按二进制协议格式化之后的消息结构,它是消息集的元素。
* 用户可通过compression.type配置压缩方式,开启压缩可显著增大内存使用率、同时减少网络开销。Compressor负责压缩消息,它的属性appendStream是个包装流,其结构是DataOutputStream—>压缩处理流—>ByteBufferStream。
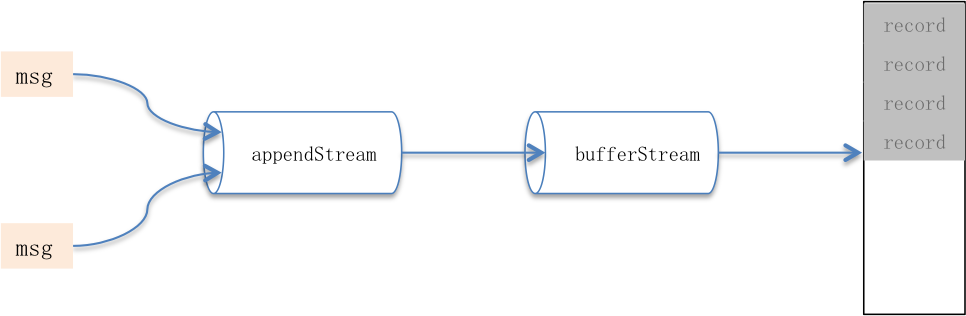
批次失效会关闭消息集使其变为只读状态,并引起Compressor关闭:释放全部I/O资源并在开启压缩时在缓冲头部位置填充协议元数据。关闭后缓冲将不再有消息写入,它被回给消息集并flip后等待发送。
数据协议
批次是消息存储的最小物理单元,读取时就只能按批次整块读取,因此如果没有标准数据协议就无法对数据块做反序列化。
Kafka把消息分割成写前日志、协议头和协议体三部分,协议头和协议体合成协议正文。日志标识消息在批次中的相对顺序和原始正文大小;消息头声明CRC、魔数和属性;最后消息体记录追加时间以及key和value值。
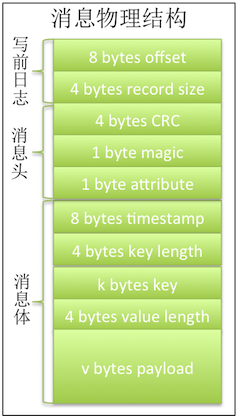
CRC即checkSum值,用于校验消息是否完整;魔数用于声明所用协议版本;属性占1个字节即8位,目前只使用了前三位,每一位代表一种压缩协议,为0即不压缩;key和value几乎一致,前4个字节标识内容长度,如果内容为-1,则表示无内容填入。
当开启压缩时,Compressor会对消息集偏移在起始位置预留出报文头长度的位置,在批次关闭后再将报文头相关数据写入,因为正文长度、payload长度以及消息数量都只能在消息只读后确定。报文头加上消息集才是完整的压缩报文。压缩报文结构和消息几乎一致,也分日志和正文两个部分,但是在个别属性上会有细微差异:1)offset分别被用于标识消息数量;2)没有key值,所有key长度都是-1;3)value长度是消息集(压缩后)的长度,payload就是消息集本身。报文头并不会被压缩,因此可以很容易被读取,程序识别报文的长度、压缩协议、版本号以及CRC等属性之后就可以选用合适的方式读取一定长度的消息以及校验批次的完整性。
批次管理
批次创建后会逗留linger.ms时间,它集聚该段时间内归属该分组(区)的消息。如果生产速率特别高又或者有超大消息流入很快将分区打满,则实际逗留时间会低于linger.ms。想象一下极端场景,批次大小默认16k,如果消息以5k、12k间隔发,则内存实际利用率只有(5+12)/(2*16)。
另一方面,积累器挤出前先要做就绪节点检查,挤出动作也只针对leader在这些节点上的分区批次,但节点ready to drain后,可能因为连接或者inflightRequests超限等问题,被从发送就绪列表移除,从而导致这些节点的可发送批次不会被挤出。它们始终占据分组队列的最高挤出优先级,这会导致:1)后追加的消息被积压,即使连接恢复后新入的消息也只能等待顺序处理,整体投递延时猛增。2)批次占据的内存得不到释放,有可能发生雪崩:因为只有追加没有挤出,问题节点的批次有可能占满全部内存空间导致其他正常节点分区无法为新批次申请空间。Kafka提供请求超时timeout.ms解决这个问题,从逗留截止开始计算批次超时则被废弃–释放内存空间并从分组队列移除。
理想状况下,单位时间内追入和挤出应该恰好相等且内存被充分使用。长期观察下调好linger.ms、batch.size、timeout.ms以及batch.size和buffer.memory这几个参数将有助于达到这个目标。
内存管理
消息集内存直接分配在堆上,如果对它不加以限制在消息生产速率足够高时很可能频繁出现fgc乃至oom,另一方面频繁的内存申请和释放操作也很吃系统资源,因此Kafka自建了内存池BufferPool管理内存。
内存池有四个关键属性:totalMemory代表内存池上限,由buffer.memory决定;poolableSize指池化内存块大小,由batch.size设置;free和availableMemory则分别代表池化内存和闲置内存大小。注意free和available的区别,前者是已申请但未使用,后者是未申请未使用,它们之间关系:totalMemory= 可使用空间+已使用空间,可使用空间=availableMemory+free.size()*poolableSize代表。
只有固定大小的内存块被释放后才会进入池化列表,非常规释放后只会增加可用内存大小,而释放内存则由虚拟机回收。因此如果超大消息比较多,依然有可能会引起fgc乃至oom。
积累器通过内存池预分配消息集内存,如果没有足够内存则用户主线程被放入有序队列并进入等待。批在批次done时释放出部分空间,同时唤醒队首线程,如果没有释放出足够的空间则继续进入等待,如果已经释放出足够空间,分配空间且线程出队。 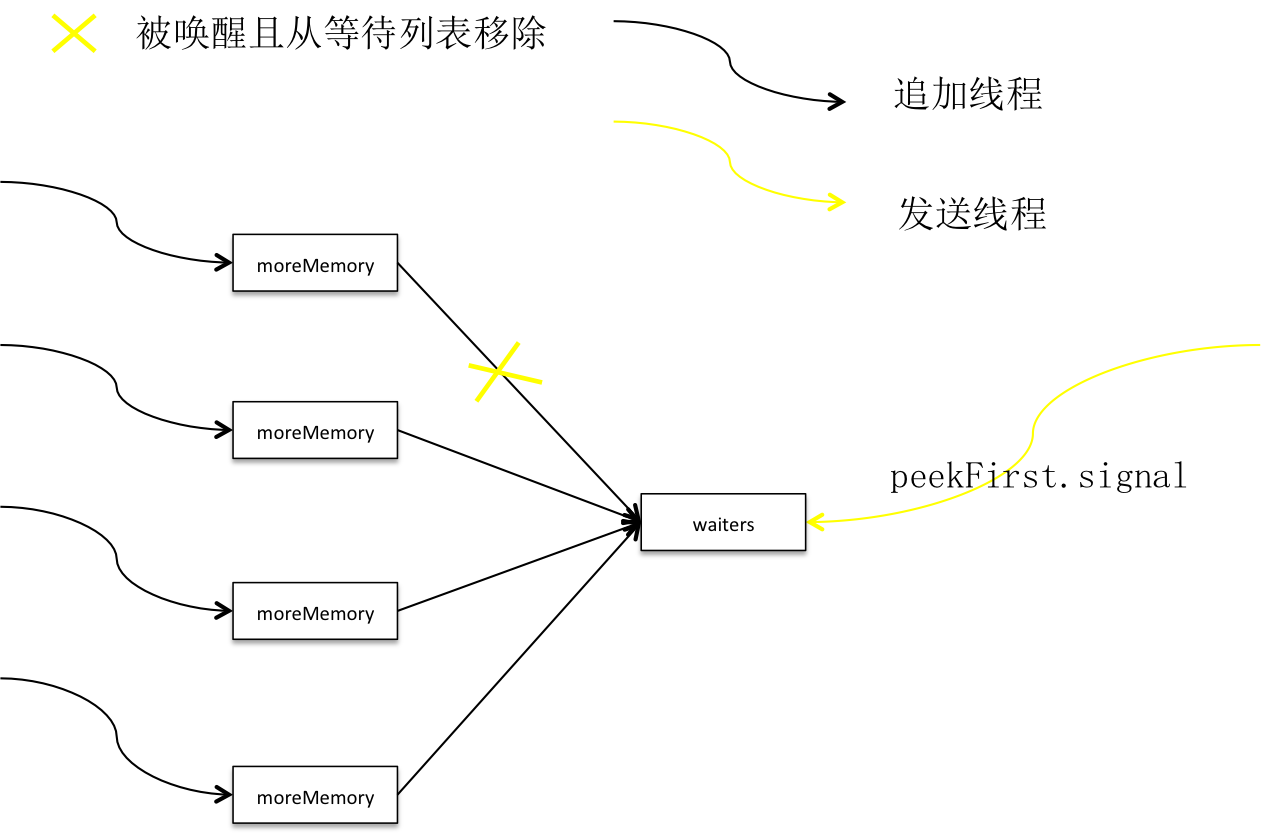
- 更加深入理解Kafka--Producer篇(下)
- 更加深入剖析Kafka--Producer篇(上)
- 更加深入剖析Kafka--Producer篇(中)
- kafka 之 producer篇
- Kafka Producer
- kafka producer
- kafka--producer
- Torch7入门续集(一)----- 更加深入理解Tensor
- kafka深入理解
- kafka深入理解
- Apache Kafka编程入门指南:Producer篇
- java编写Producer(线程池,kafka)
- kafka生产者示例(kafka-python producer example)
- kafka producer的serializer
- kafka producer总结
- Kafka Producer APIs
- Kafka Producer接口
- kafka Producer API使用
- HTML元素分类
- HDU2063-过山车
- 【bzoj2038】[2009国家集训队]小Z的袜子(hose)
- Apriori关联分析与FP-growth挖掘频繁项集
- 树状数组——A
- 更加深入理解Kafka--Producer篇(下)
- cocos2dx之九宫格
- msyql 查看表锁和查看表锁情状况
- 一道感觉很难受的题QAQ
- git (分布式管理控制系统)学习
- python进程和线程详解
- 318. Maximum Product of Word Lengths
- Java:集合框架详解(ArrayList)和代码示例
- IO(字符流)


